Sachin KalsiinTowards AIA Deep Dive into FlashAttention V1 -part 3Diving Deep into FlashAttention V1: Cracking the Code on Safe Softmax and Online Normalization — Exploring Nvidia’s Innovative AlgorithmOct 24, 20231Oct 24, 20231
Sachin KalsiFlashAttention: An Advancement in GPU Acceleration for Training LLMsUnlocking the Potential of FlashAttention: Elevating GPU Acceleration in LLM TrainingOct 24, 2023Oct 24, 2023
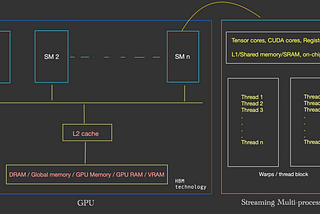
Sachin KalsiFlashAttention: Understanding GPU Architecture-Part 1Unlocking the Power of FlashAttention: A Deep Dive into GPU Architecture for Efficient Language ModelsOct 23, 2023Oct 23, 2023
Sachin KalsiKey takeaways from building multiple machine learning modelsHere is a list of my major key takeaways from doing various machine learning & deep learning experiments and reading several research…Mar 19, 2022Mar 19, 2022