Tic Tac Toe AI Tournament: Analyzing Strategies and Showcasing Superiority
Over the last 2 weeks, I’ve been working on eight AI agents built to play Tic Tac Toe. Today, we’ll be putting them to the test to evaluate how they perform against each other.
Before we start, I’ve covered a lot of information that I won’t be explaining here:
If you’re interested in my implementation you can check that out here: https://github.com/saiccoumar/TicTacToe
If you’re interested in deeper explanations about each algorithm and how they work you can check out my previous medium article on that: https://medium.com/@saicoumar/applying-ai-to-tic-tac-toe-7f3634402ea2
I highly recommend reading those first to really understand the algorithms and the expectations we have of agents based on them.
Now, let’s get into it.
I could have absolutely set up some test cases with formal metrics and those probably would have been a more accurate quantification of performance; but as a longtime fan of Dragon Ball, I naturally felt that the best way to test these algorithms against each other was through a tournament.
Rules
For this tournament, we’ll be using a double elimination bracket with seven games per match in a round. If the games are drawn after seven matches, then we’ll keep having games until one agent wins and the other loses.
Agents
Let’s take a look at the competitors:
Reflexive Rule-Based Agents
Center Agent: This agent picks the center if it’s available.
Corner Agent: This agent picks the corners if they’re available.
One-Step: This agent looks one step into the future to check for immediate wins and prevent immediate losses.
Combined Rules Agent: This agent uses the three rules above as well as a new rule that checks for forks.
Adversarial Search Agents
Minimax Agent: This agent uses minimax to search all outcomes and pick the action that minimizes loss in the worst possible outcome.
Monte Carlo Tree Search Agent (MCTS) : This agent uses MCTS to build an MCTS tree and pick the best action based on simulations. We use an exploration/exploitation constant C=0.7 with 100,000 iterations.
Neural Networks
Predict Wins NN Agent: This agent, trained on endgame data, uses a neural network to predict whether an action will result in a win.
Predict Position NN Agent: This agent, trained on data of the outputs of Combined Rules Agent, Minimax Agent, and the MCTS agent, predicts the next position to play.
Based on our conclusions from the analysis of the theory, the heavy hitters we’re expecting to see big performances from are the Combined Rules agent, the Minimax agent, the MCTS agent, and the Predict Position NN agent.
Round 1 (Winners Bracket)

Starting with Round 1 of the winners bracket we have 4 matches.
Match 1: Center Agent vs Minimax
Going into this match, I expected a strong performance from Minimax. Center Agent has one strong move and then defaults to random choices whereas Minimax exhaustively searches all possible outcomes.
Results:
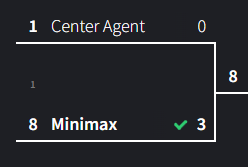
These results surprised me quite a bit. Minimax only won by 3 and drew 4 times, which wasn’t a blowout like I expected. I reran it several times after, and it seems that Minimax would often draw if the center agent started first. I think this can be attributed to how many winning/drawn board combinations exist for the player who has picked the center. Picking the center removes one of the strongest positions, so Minimax has fewer winning combinations and more draws to play towards.
Match 2: Corner Agent vs Predict Position
Given that the Predict Position agent uses a neural network and corner agent is a considerably weaker AI, I’m fully expecting predict position to win easily.
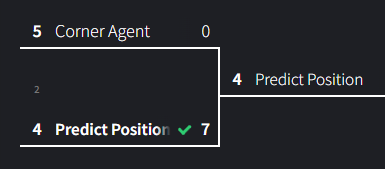
There’s the blowout we were expecting. The corner agent consistently blundered by trying to take corners, while the Predict Position would simply pick the middle column or row and win easily. This performance was almost painful to watch.
Match 3: Predict Win NN vs MCTS
Despite being a neural network, the Predict Win Neural Network Model performed abysmally in prior testing due to a poor choice of dataset. The Monte Carlo Search Tree isn’t the strongest algorithm, but against an algorithm this weak, it shouldn’t have any trouble.
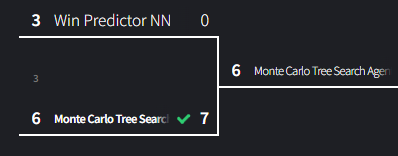
An expectedly tragic performance for the Predict Win NN Agent. MCTS moves onto the next round.
Match 4: Combined Rules vs One-Step
The Combined Rules Agent was built on One-step so I’d be considerably surprised if it struggled against it’s baby brother.
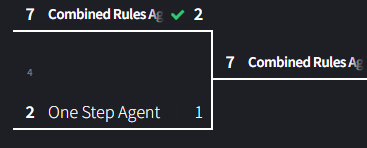
My predictions were way off the mark. Evidently, the performance benefits from the corner/center rule and the forking rule are only marginal, and the Combined Rules agent only narrowly beat out One-step. I ran it a few more times, and the Combined Rules agent did win more often than One-step, but only after drawing at a minimum of three times as often as it won.
Round 1 (Winner’s Bracket) Results

Round 1 (Loser’s Bracket)
Going into the losers bracket, I’m a little less confident about what to expect. One-step is the strongest agent, but among the other three, I have no expectations.
Match 5: Center Agent vs Corner Agent
I genuinely have no idea what to expect with this match. Both agents work very similarly with only slightly different rules. The looming question here is what’s a more valuable position in Tic Tac Toe: The center or the corners?

With zero draws and a win by only one, I’m not certain that I can really answer the question from earlier. My theory is that both agents are equal and we only saw these results due to the default policy of using random positions when their respective positions are taken. Center Agent won nonetheless, and moves forward.
Match 6: Predict Win NN vs One-Step
After the poor performance from Predict Win NN agent and the strong performance from One-step in the last round, I’m going to safely place my bets on One-step.
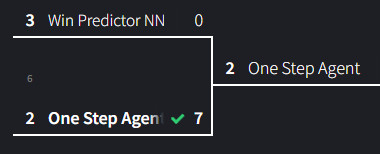
Not much to say here. One-step cooked.
Round 1 (Loser’s Bracket) Results

Round 2 (Winner’s Bracket)
Round 2 is looking to see some intense competition. The current 4 competitors in the winners bracket were what I considered to be my top picks and the strongest agents.
Match 7: Minimax vs Predict Position
Here we have a contest between an agent that will deterministically pick the best answer and an agent that has seen over 30,000 possible game states and learned to play from them. These two approaches are theoretically the best approaches as one calculates the best option and the other has seen an absurd quantity of solutions.
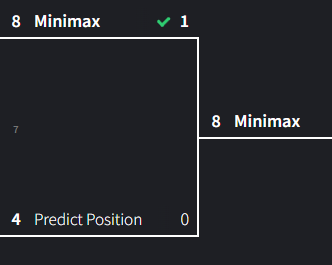
This match took me forever to run. It drew eight times in a row and only on the 9th did minimax win. I think the losses had to have been from one of the 30,000 examples that didn’t predicted the next position well while minimax does exhaustive searches and returns “perfect” decisions.
Match 8: MCTS vs Combined Rules
MCTS and Combined rules are both imperfect algorithms and seem like a balanced matchup. MCTS theoretically should be able to evaluate more scenarios but combined rules also has the ability to deterministically pick immediate winning moves.

Evidently, being able to simulate games and make moves towards a winning outcome is not as valuable as seeking immediate wins. MCTS’ foresight seems to be its own downfall and it didn’t even register a single win in this match.
Round 2 (Winner’s Bracket) Results

Round 2 (Loser’s Bracket)
In this round we have MCTS vs Center agent and Predict Position vs One-step. We’ll hopefully start to weed out the bottom 50% of agents after this round and really get a look at what algorithms we can consider “good”.
Match 9: MCTS vs Center Agent
MCTS should pretty easily handle center agent given that Minimax absolutely obliterated it and MCTS is also an adversarial search algorithm.
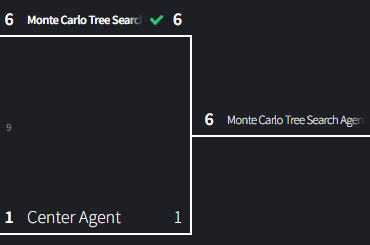
With zero draws and only one loss, MCTS was expectedly strong. However, I’m considerably surprised that MCTS even lost once to Center Agent. My guess is that this is another trait of a problem with so few possible game board combinations and that allows playing random to lead to good outcomes accidentally quite often.
Match 10: Predict Position vs One-Step
I’m less sure about Predict Position and One-step. Predict Position should be the better algorithms since it’s much more holistic and robust but One-step has proven to be much stronger than I originally thought.
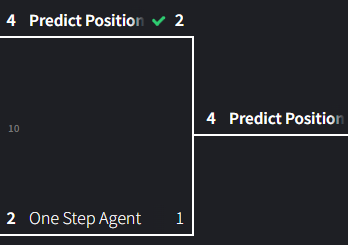
This match was a real nailbiter. These agents drew 5 times and then predict position won on the sixth match. On the seventh match, which I thought would be the last, one-step won to tie it up. After that, they went to draw FIFTEEN times straight for a total of 21 draws before predict position finally scored another win. One-step put up a fight before it went down and really had predict position on the ropes.
Round 2 (Loser’s Bracket) Results

Round 3 (Both brackets):
Going into the semifinals we have our top 4 competitors. We have MCTS and Predict Position in the loser’s bracket and Minimax and Combined Rules Agent in the winner’s bracket with the winner of both competing in the finals
Match 11: MCTS vs Predict Position
Once again we have a really close matchup. MCTS threw a game in the last match against an easy opponent so it isn’t looking so good for it, but Predict Position had to fight tooth and nail for it’s last win.

Once again we saw a really close matchup for Predict Position. It took the lead early on and drew for 3 games straight to barely hold out going into the seventh game.
Match 12: Minimax vs Combined Rules
In the last round we saw a blowout from the Combined Rules agent and a close victory from minimax. With that being said, I think minimax will still come out on top. Minimax has adaptability to every possible outcome while Combined Rules definitely has some circumstances that it can’t account for.
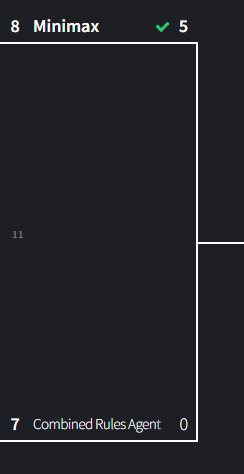
As expected, Minimax put the Combined Rules agent to shame. However, I noticed that the game states often looked very similar. I think Minimax managed to find and exploit conditions that would bypass the combined rules agent, and kept using them, similar to human testers. Unfortunately, combined rules seemed to just be up against the worst possible opponent it could have come up against
Round 3 (Both brackets) Results

Round 4 (Loser’s bracket final)
Match 13: Predict Position vs Combined Rules
Fighting for another chance to win it all, we have our Combined Rules agent and the Predict Position agent. Combined Rules shouldn’t be so susceptible to exploitations like it was against minimax, but Predict Position is much more robust and contains knowledge that Combined Rules Agent has as well as MCTS and minimax — the latter previously beating Combined Rules.

Another close match for Predict Position. These were pretty even in performance but Combined Rules NEVER managed to win against Predict Position. The neural network simply had too much experience for Combined Rules to get the upper hand.
Round 4 (Loser’s bracket final) Results

Round 5 (Winner’s bracket final)
Match 14: Minimax vs Predict Position
In the final round of our tournament we’re seeing a rematch of one of the closest matchups. Predict Position has made it’s way back from the loser’s bracket up to the final round. Will minimax secure another win or will Predict Position come out on top?
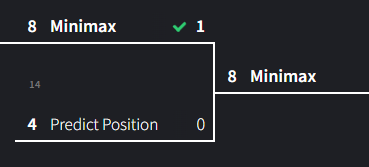
With a narrow victory minimax barely comes out on top. Predict Position did really well though, managing to draw every match except for one, and I think it could have continued to draw if not for the seven game cap. Nevertheless, Minimax wins!
Round 5 (Winner’s bracket final) Results

Minimax has been crowned as our best agent. The small game state space makes it efficient, and its exhaustive nature to look for the best option that maximizes gain in the worst-case scenario guarantees it wins that the other algorithms often can’t match, even when they get close.
Regardless, my personal MVP of this tournament was the Predict Position agent. Predict Position crawled its way from the loser’s bracket all the way to the top and could only be stopped by a “perfect” algorithm. It was also much faster than both MCTS and Minimax, and was more robust than the combined rules agent. It was also the most fun to play against since it presented a constant challenge for humans and wouldn’t become predictable.
I had a lot of fun setting this up, and it was a really entertaining way to put my work to the test. I highly recommend checking out my other work on this project, if you haven’t already. Check out my Github for more projects @ https://github.com/saiccoumar
Thanks for reading!





