SHIBIKANTH RPCA → PRINCIPAL COMPONENT ANALYSISPrincipal component analysis, or PCA, is a dimensionality-reduction method that allows you to summarize the information content in large…May 26, 2022May 26, 2022
SHIBIKANTH RBroadcast and Accumulator variable in PySparkFor parallel processing, Apache Spark uses shared variables. A copy of shared variable goes on each node of the cluster when the driver…May 9, 2022May 9, 2022
SHIBIKANTH RA Most Useful Feature in PySpark — UDFPySpark UDF (User Defined Function) is the most useful feature of Spark SQL & DataFrame that is used to extend the PySpark build in…May 9, 2022May 9, 2022
SHIBIKANTH RSPARK from APACHEIn this module, we are going to have look at the SPARK from Apache.May 8, 2022May 8, 2022
SHIBIKANTH RHIVEIn this side, we are going to have a very simple overview of hive and its architecture.May 2, 2022May 2, 2022
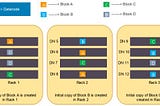
SHIBIKANTH RHadoop ArchitectureHadoop is an open source framework from Apache and is used to store process and analyze data which are very huge in volume. Hadoop is…Apr 25, 2022Apr 25, 2022
SHIBIKANTH RMovie Ticket Booking SystemHere we are going to look into the movie ticket booking system using Python.Apr 17, 2022Apr 17, 2022
SHIBIKANTH RPandasPandas is an open source Python package that is most widely used for data science/data analysis and machine learning tasks. It is built on…Apr 13, 2022Apr 13, 2022
SHIBIKANTH RPolymorphismPolymorphism is taken from the Greek words Poly (many) and morphism (forms). It means that the same function name can be used for different…Apr 11, 20221Apr 11, 20221
SHIBIKANTH RNumpyWe are going to have a glance at the numpy operations of python.Apr 11, 2022Apr 11, 2022