JARK Stack for Generative AI, Part 6
Scalable Model Inference
Table of Contents
This series is composed of six parts:
- Part 1: Introduction
- Part 2: Build the JARK Stack with Terraform
- Part 3: Autoscaling with Karpenter
- Part 4: Parallel Computing with KubeRay
- Part 5: Generative AI on JARK
- Part 6: Scalable Model Inference (this article)
Inference: Crucial Transition from Training to Production
After numerous iterations of training and fine-tuning, an AI/ML model is finally ready for production release. At this stage, the primary focus shifts from model development to using the model to perform inference for customers. For many organizations, it is during inference that they start to see a return on investment, making it a critical phase for revenue generation. Furthermore, the resources utilized for inference, particularly GPUs, represent a significant portion of the infrastructure costs associated with AI/ML operations. As such, it becomes imperative for companies to identify and implement a truly scalable solution capable of managing the demands of inference infrastructure efficiently.
Leveraging KubeRay’s RayService for Scalable AI Inference
Ray Serve is a prominent AI library built atop the Ray framework, designed to provide scalable model inference APIs. It seamlessly integrates within Kubernetes through the KubeRay operator. The operator introduces a custom resource definition known as RayService, which amalgamates Ray Serve applications with the underlying RayCluster into a unified resource. This union simplifies the management and scaling of inference workloads.
Taking advantage of KubeRay’s autoscaling capabilities can pave the way for developing a truly scalable end-to-end inference API service. In this article, we will build upon the fine-tuned model from part 5 by orchestrating an auto-scaling API service on Amazon Elastic Kubernetes Service (EKS). We’ll demonstrate the concurrent serving of both the original stable diffusion model and our DreamBooth fine-tuned version, showcasing the flexibility of the system without the need for any additional code.
The Python Application Code
It is truly remarkable how a succinct piece of Python code can facilitate inferences on two different stable diffusion models with such ease. The required code is contained within a single file, stable_diffusion.py, which is composed of under 70 lines. Among these, there are only a few critical lines that underpin its functionality:
model_path = os.environ.get("MODEL_PATH", "/data/tmp/model-tuned")This crucial line instructs the program to load the stable diffusion model from a directory specified by the MODEL_PATH environment variable. As we will explore later, this variable is conveniently configured via the RayService definition.
@app.get(
"/imagine",
responses={200: {"content": {"image/png": {}}}},
response_class=Response,
)
async def generate(self, prompt: str, img_size: int = 512):Here we see the FastAPI framework in action, implementing a GET endpoint at /imagine which returns the dynamically generated image in PNG format. By utilizing the power of FastAPI, we make image generation accessible with minimal effort, highlighting the efficacy of the API design.
Understanding the RayService Configuration
The inference.ymlfile is a critical Kubernetes manifest for deploying the RayCluster and orchestrating our Ray Serve applications. This manifest is divided into two main sections.
In the first section, the file defines configurations for two Ray Serve applications:
spec:
serveConfigV2: |
applications:
- name: original_stable_diffusion
route_prefix: /original
import_path: 05_dreambooth_finetuning.rayservice.stable_diffusion:entrypoint
runtime_env:
working_dir: "https://github.com/jinzishuai/jark-demo/archive/master.zip"
env_var:
- name: MODEL_PATH
value: "/home/ray/efs/src/jark-demo/05_dreambooth_finetuning/data/model-orig/models--stabilityai--stable-diffusion-2-1/snapshots/5cae40e6a2745ae2b01ad92ae5043f95f23644d6"
...
This excerpt demonstrates the setup for the original_stable_diffusion service, which includes routing details and environmental configuration. Here, route_prefix determines the REST API's entry point (/original/imagine), while MODEL_PATH specifies the model's file location on disk.
- name: tuned_dreambooth
route_prefix: /tuned
...The tuned_dreambooth application mirrors the configuration of original_stable_diffusion with alterations to its route_prefix and MODEL_PATH. This ensures the fine-tuned model is accessible via a different REST API endpoint (/tuned/imagine).
The import_path and working_dir configurations direct KubeRay to download the specified branch of a specified code repository, set up a temporary working directory, and execute the entrypoint statement found in 05_dreambooth_finetuning/rayservice/stable_diffusion.py.
The second section of the manifest presents the Ray cluster configuration, advancing the setup we previously used by introducing autoscaling capabilities:
rayClusterConfig:
rayVersion: "2.9.0"
enableInTreeAutoscaling: true
...With enableInTreeAutoscaling set to true, an autoscaler sidecar container is integrated into the head node pod. This container meticulously manages scaling operations, adjusting the number of active worker nodes within the defined limits:
workerGroupSpecs:
- replicas: 0
minReplicas: 0
maxReplicas: 2With this configuration, the cluster can scale between 0 and 2 worker pods, adapting dynamically to the workload demands.
Running the RayService Demonstration
To initiate the demo, we simply deploy the RayService using the inference.yml manifest:
╭─ ~/src/jinzishuai/jark-demo/05_dreambooth_finetuning/rayservice main *1 ?5 ·································································· base ⎈ jark-stack 08:15:25
╰─❯ kubectl apply -f inference.yml
rayservice.ray.io/dreambooth-inference createdThis commands Kubernetes to instantiate all required resources within the ray-gpu namespace:
╰─❯ kubectl -n ray-gpu get rayservice,raycluster,service,pod,nodes -o wide
NAME AGE
rayservice.ray.io/dreambooth-inference 2m29s
NAME DESIRED WORKERS AVAILABLE WORKERS STATUS AGE HEAD POD IP HEAD SERVICE IP
raycluster.ray.io/dreambooth-inference-raycluster-x6k2n ready 2m27s 100.64.195.137 172.20.170.198
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/dreambooth-inference-head-svc ClusterIP 172.20.115.77 <none> 10001/TCP,8265/TCP,52365/TCP,6379/TCP,8080/TCP,8000/TCP 2m6s app.kubernetes.io/created-by=kuberay-operator,app.kubernetes.io/name=kuberay,ray.io/cluster=dreambooth-inference-raycluster-x6k2n,ray.io/identifier=dreambooth-inference-raycluster-x6k2n-head,ray.io/node-type=head
service/dreambooth-inference-raycluster-x6k2n-head-svc ClusterIP 172.20.170.198 <none> 10001/TCP,8265/TCP,52365/TCP,6379/TCP,8080/TCP,8000/TCP 2m28s app.kubernetes.io/created-by=kuberay-operator,app.kubernetes.io/name=kuberay,ray.io/cluster=dreambooth-inference-raycluster-x6k2n,ray.io/identifier=dreambooth-inference-raycluster-x6k2n-head,ray.io/node-type=head
service/dreambooth-inference-serve-svc ClusterIP 172.20.101.124 <none> 8000/TCP 2m6s ray.io/cluster=dreambooth-inference-raycluster-x6k2n,ray.io/serve=true
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/dreambooth-inference-raycluster-x6k2n-head-49dlg 2/2 Running 0 2m28s 100.64.195.137 ip-100-64-177-12.ec2.internal <none> <none>
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node/ip-100-64-177-12.ec2.internal Ready <none> 73m v1.28.5-eks-5e0fdde 100.64.177.12 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-32-74.ec2.internal Ready <none> 73m v1.28.5-eks-5e0fdde 100.64.32.74 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2With no initial GPU nodes spun up, we establish two proxy connections to interface with the REST API and Ray dashboard:
kubectl -n ray-gpu port-forward service/dreambooth-inference-head-svc 8265
kubectl -n ray-gpu port-forward service/dreambooth-inference-serve-svc 8000Before commencing any tasks, the Ray Cluster should show zero worker nodes. The Ray dashboard at http://localhost:8265/ will confirm this, revealing only the head node running the APIIngress processes.
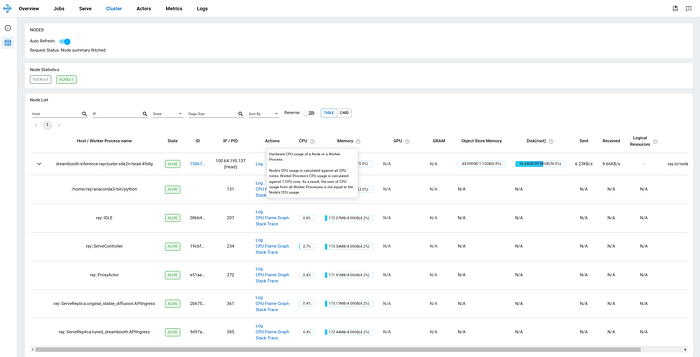
We can also check the Serve tab and confirm the StableDiffusionV2 deployment has 0 repilca at this time.
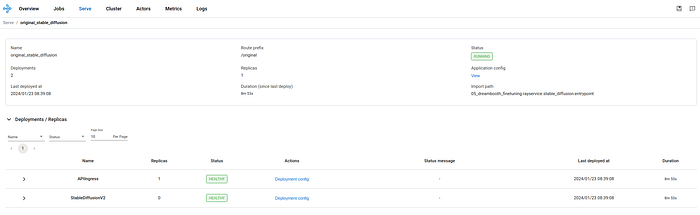
Now let’s perform an inference on the original stable diffusion model by visiting URL http://localhost:8000/original/imagine?prompt=”a dog on paddle board in Moraine Lake, Alberta”. Note that the URL will be converted by the browser to be something like http://localhost:8000/original/imagine?prompt=%22a%20dog%20on%20paddle%20board%20in%20Moraine%20Lake,%20Alberta%22
The browser will spin for a while since behind the scene Ray is requesting a new worker pod and Karpenter will meet that request with a new g5.xlarge instance. We can check what’s happening by
╰─❯ kubectl -n ray-gpu get pod,nodeclaim,nodes -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/booth-inference-raycluster-x6k2n-worker-gpu-group-x64bz 0/1 Init:0/1 0 2m10s <none> ip-100-64-99-95.ec2.internal <none> <none>
pod/dreambooth-inference-raycluster-x6k2n-head-49dlg 2/2 Running 0 16m 100.64.195.137 ip-100-64-177-12.ec2.internal <none> <none>
NAME TYPE ZONE NODE READY AGE CAPACITY NODEPOOL NODECLASS
nodeclaim.karpenter.sh/gpu-vcvx6 g5.xlarge us-east-1c ip-100-64-99-95.ec2.internal True 2m9s on-demand gpu gpu
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node/ip-100-64-177-12.ec2.internal Ready <none> 87m v1.28.5-eks-5e0fdde 100.64.177.12 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-32-74.ec2.internal Ready <none> 87m v1.28.5-eks-5e0fdde 100.64.32.74 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-99-95.ec2.internal Ready <none> 86s v1.28.5-eks-5e0fdde 100.64.99.95 <none> Amazon Linux 2 5.10.192-183.736.amzn2.x86_64 containerd://1.7.2The Ray Serve dashboard also shows the upscaling in progress
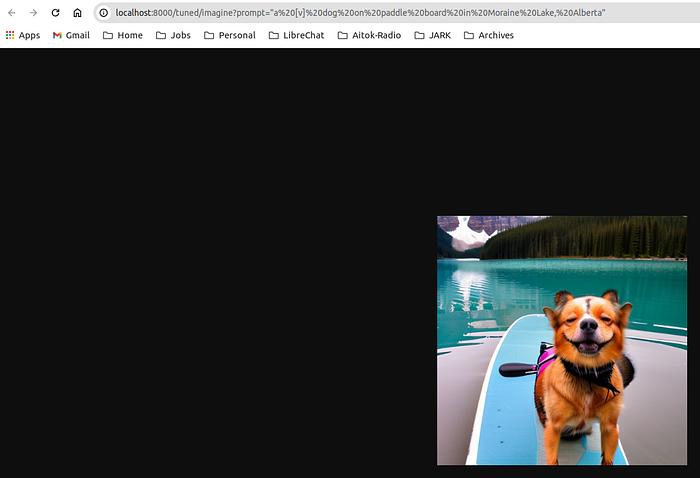
In a few minutes, we should see an image similar to this in the browser

We can try again with different prompts and we’ll get reponses very quickly.
Similarly, we can activate the fine-tuned model by visiting http://localhost:8000/tuned/imagine?prompt=”a [v] dog on paddle board in Moraine Lake, Alberta”
At this point, our infrastructure has scaled to have two g5.xlarge GPU instances in the EKS and Ray cluster.
╰─❯ kubectl -n ray-gpu get pod,nodeclaim,nodes -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/booth-inference-raycluster-m549l-worker-gpu-group-tmzv6 1/1 Running 0 7m15s 100.64.131.195 ip-100-64-203-155.ec2.internal <none> <none>
pod/booth-inference-raycluster-m549l-worker-gpu-group-w566w 1/1 Running 0 19m 100.64.75.253 ip-100-64-115-5.ec2.internal <none> <none>
pod/dreambooth-inference-raycluster-m549l-head-x96q2 2/2 Running 0 19m 100.64.224.97 ip-100-64-177-12.ec2.internal <none> <none>
NAME TYPE ZONE NODE READY AGE CAPACITY NODEPOOL NODECLASS
nodeclaim.karpenter.sh/gpu-6bjpv g5.xlarge us-east-1c ip-100-64-115-5.ec2.internal True 19m on-demand gpu gpu
nodeclaim.karpenter.sh/gpu-c9s8f g5.xlarge us-east-1d ip-100-64-203-155.ec2.internal True 7m14s on-demand gpu gpu
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node/ip-100-64-115-5.ec2.internal Ready <none> 18m v1.28.5-eks-5e0fdde 100.64.115.5 <none> Amazon Linux 2 5.10.192-183.736.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-177-12.ec2.internal Ready <none> 151m v1.28.5-eks-5e0fdde 100.64.177.12 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-203-155.ec2.internal Ready <none> 6m38s v1.28.5-eks-5e0fdde 100.64.203.155 <none> Amazon Linux 2 5.10.192-183.736.amzn2.x86_64 containerd://1.7.2
node/ip-100-64-32-74.ec2.internal Ready <none> 151m v1.28.5-eks-5e0fdde 100.64.32.74 <none> Amazon Linux 2 5.10.205-195.804.amzn2.x86_64 containerd://1.7.2So far, we’ve seen how the RayService automatically scales out when load increases. When the load subsides, and the service idles, we will observe the RayService automatically scale down, terminating worker pods and consequently Karpenter would remove the provisioned GPU instances shortly after.
Note: To maintain seamless user experiences in production, it’s advisable to retain a minimum number of worker pods active. This strategy can help mitigate the latency associated with new pod initialization, particularly when dealing with large Docker images.
Summary: Scalability with KubeRay and Karpenter on EKS
This article showcased the impressive scalability achievable with KubeRay and Karpenter on EKS when applied to AI model inferencing. The seamless orchestration between these tools underlines the potential for responsive and cost-effective scaling in demanding AI workloads. I hope that the insights shared here have illuminated a path forward for leveraging cloud resources efficiently and effectively in the realm of machine learning operations.
Series Wrap-Up: Reflecting on the JARK Stack for Generative AI Journey
With this final installment, we bring to a close the “JARK Stack for Generative AI” series. Throughout our journey, we have navigated the intricate landscape of cutting-edge AI model deployment, capitalizing on the strengths of the JARK stack within the AWS ecosystem.
Fueled by curiosity, a review of my AWS billing for the duration of these explorations revealed some unexpected insights. In a span of just over a week — a period marked by the active creation and destruction of AWS infrastructure, including GPU instances — the financial tally remained below $100 USD. Intriguingly, it was not the GPU instances but rather the NAT gateway’s network traffic that surged to the forefront of expenditures, consuming over 30% of the overall budget. This finding draws attention to potential cost-saving strategies, such as downsizing Docker images and transitioning to the Amazon Elastic Container Registry (ECR), to tamp down networking costs.
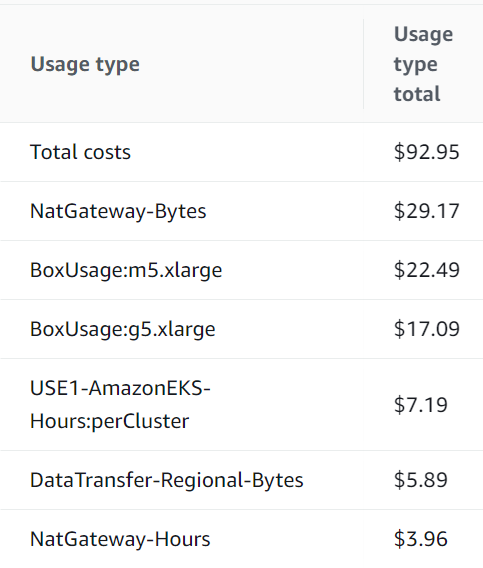
Yet, the key takeaway extends beyond mere numbers. This experience stands as a testament to the economic agility possible through dynamic cloud resource management. When considering the sizeable weekly expense typically associated with just a pair of g5.xlarge GPU instances — upwards of $300 USD — our frugal footprint underscores the fiscal prudence we’ve tapped into.
This series was never intended to serve as a comprehensive dissection of every technical substrate but rather as a starting point — an appetizer to whet the appetite and spark intrigue. It was designed to prompt deeper dives and further investigations into this robust technological stack.
As we conclude, your insights and experiences are invaluable — I warmly welcome any commentary, critique, or reflections on the blog posts or code shared throughout this series. Let’s continue to learn, discover, and innovate together in the ever-expanding domain of generative AI.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!

