Introduction to Different Activation Functions for Deep Learning
The Idea of Neural Networks was first introduced way back in the 1950s, but it wasn’t until 2012 that they come to action. Even application of Optimization Algorithm(Gradient Descent) in 2006 by Hinton, wasn’t giving good results, it was the introduction and usage of Activation functions, which revolutionized Deep Learning Research.
There are various kind of Activation Functions that exists, and Some Researchers are still working on finding better functions, which can help networks to converge faster or use less layers, etc. Let's go through each of them:
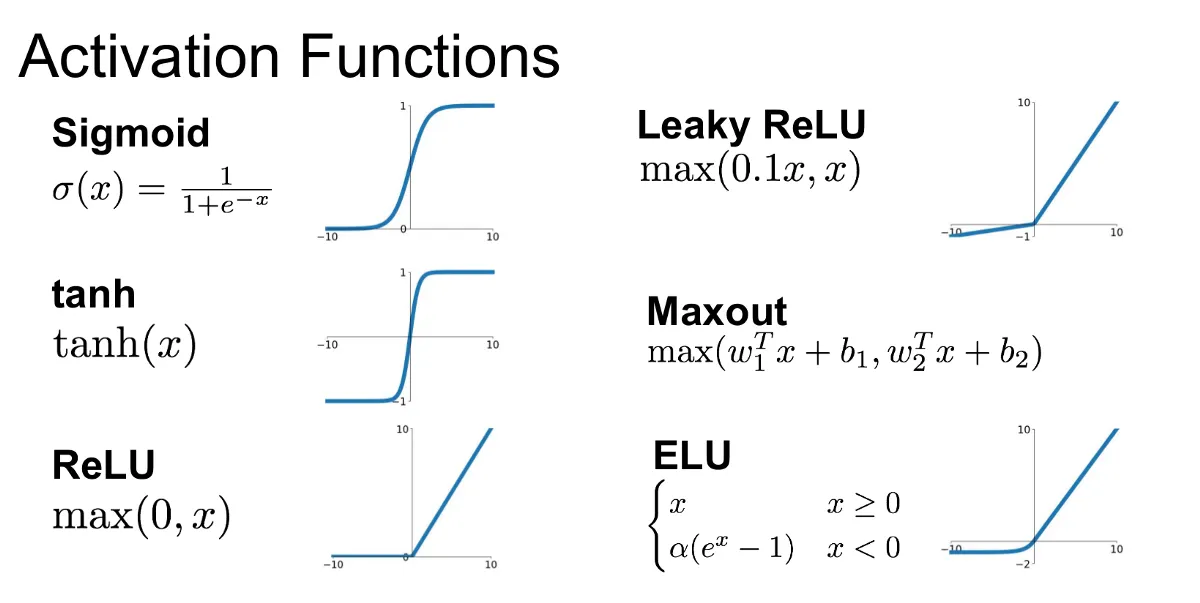
- Sigmoid Activation Function: Sigmoid Function is one of the special functions in the Deep Learning Field, thanks to its simplification during Back Propagation. As we can see in this image, it:
(a.) Range from [0,1].
(b.) Not Zero Centered.
(c.) Have Exponential Operation (It's Computationally Expensive!!!)
The Main Problem we face is because of Saturated Gradients, as the Function ranges between 0 to 1, the values might remain constant, thus the gradients will have very less values. Therefore, no change during gradient descent.
2. Hyperbolic Tangent Activation Function(tanh): Hyperbolic Tangent also have the following properties:
(a.) Ranges Between [-1,1]
(b.) Zero Centered
tanh can be considered as a good example in case when input>0, so the gradients we will obtain will either be all positive or negative, which can lead to explosion or vanishing issue, thus usage of tanh can be a good thing. but this still faces the problem of Saturated Gradients.
3. Rectified Linear Unit Activation Function (ReLU): ReLU is the most commonly used Activation Functions, because of its simplicity during backpropagation and is not computationally expensive. It has the following properties:
(a.) It doesn’t Saturate.
(b.) It converges faster than some other activation functions.
But we can face an issue of dead ReLU, for Example, if:
w>0, x<0. So, ReLU(w*x)=0, Always.
4. Leaky ReLU: Leaky ReLU can be used as an improvement over ReLU Activation function. It has all properties of ReLU, plus it will never have a dead ReLU problem.
We can consider different multiplication factors to form different variations of Leaky ReLU.
5. ELU(Exponential Linear Units): ELU is also a variation of ReLU, with a better value for x<0. It also has the same properties as ReLU along with:
(a.) No Dead ReLU Situation.
(b.) Closer to Zero mean Outputs than Leaky ReLU.
(c.) More Computation because of Exponential Function.
6. Maxout: Maxout has been introduced in 2013. It has the property of Linearity in it. So, it never saturates or dies. But is Expensive as it doubles the parameters.
7. KAFNETS: Most neural networks work by interleaving linear projections and simple (fixed) activation functions, like the ReLU function. A KAF is instead a non-parametric activation function defined as a one-dimensional kernel approximator:
where:
- The dictionary of the kernel elements is fixed by sampling the x-axis with a uniform step around 0.
- The user can select the kernel function (Gaussian in our implementation) and the number of kernel elements D.
- The linear coefficients are adapted independently at every neuron via standard back-propagation.
KAFNETS (Link) gives promising Results, we have tested them for One-shot Learning as mentioned in Article.
Mostly, Neural Networks go for different variations of RELU for its simplicity and easy computation both during forward and backward. But, in certain Cases, Other Activation Functions give us better results, Like Sigmoid is used at the end layer when we want our outputs to be squashed between [0,1], or tanh is being used in RNNs and LSTMs.
If you found this article useful, please consider citing us:
@article{jadon2018introduction,
title={Introduction to different activation functions for deep learning},
author={Jadon, Shruti},
journal={Medium, Augmenting Humanity},
volume={16},
year={2018}
}Are you preparing for an upcoming Machine Learning/Data Science interview? If yes, make sure to check out https://www.datasciencepreparation.com/
