Sivanarayana MamidiRLHFReinforcement learning from Human Feedback is a method used to improve the performance of AI models like LLaMA by training them to align…Sep 23Sep 23
Sivanarayana MamidiHyde approach to context optimizationThe Hyde approach to context optimization in large language models (LLM) is method designed to manage and enhance the effectiveness of the…Sep 5Sep 5
Sivanarayana MamidiLLM on Multi_inferenceHorizontal scaling means adding more instances or pods of a service to handle more load or requests. By running several instances of the…Aug 31Aug 31
Sivanarayana MamidiMULTI INFERENCE of LLMLLM model can handle multiple users simultaneously through combination of several undelying technologies and techniquesAug 31Aug 31
Sivanarayana MamidiTraining arguments of SFT of LLData collator : In the context of the hugging face transformers library is a utility that helps preprare batches of data during training…Aug 31Aug 31
Sivanarayana MamidiQLORA, PTQ,QLoRA, PTQ, and QAT are all techniques related to the optimization and fine-tuning of machine learning models, particularly large language…May 29May 29
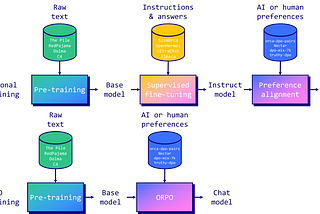
Sivanarayana MamidiORPO , DPO and PPODPO : Direct Preference Optimization (DPO) is a method for aligning large language models (LLMs) with human preferences without the need…May 28May 28