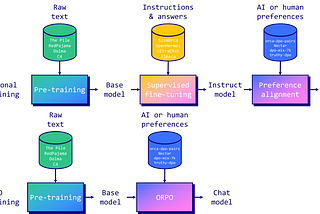
Sivanarayana MamidiORPO , DPO and PPODPO : Direct Preference Optimization (DPO) is a method for aligning large language models (LLMs) with human preferences without the need…2 min read·3 hours ago----
Sivanarayana MamidiLoRA and QLoraLoRA is low-rank decomposition method to reduce the number of trainable parameters which speeds up finetuning large models and uses less…1 min read·Apr 25, 2024----
Sivanarayana MamidiQuantization loading models by different data typesQuantization — concept3 min read·Apr 25, 2024----
Sivanarayana MamidiQuantizationquantization means , it shrink models to a small size, so that anyone can run it with their own computer with little to no performance…4 min read·Apr 25, 2024----
Sivanarayana MamidiPrompt engineeringChain of thought: Anytime u went with large language models, consider two things3 min read·Apr 25, 2024----
Sivanarayana MamidiDocument image analysisPre processing with rule-based parsers:2 min read·Apr 24, 2024----
Sivanarayana MamidiHow to pass the cuda software inside the containerwget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run 10 ls 11 chmod a+x…1 min read·Apr 24, 2024----
Sivanarayana MamidiChunking :Chunking means taking a long piece of text, like a large document, breaking down into smaller pieces into the vector databases1 min read·Apr 24, 2024----
Sivanarayana MamidiSemantic Search for LLM’sGoal: given an input text , find semantic similar content from a corpus of documents for use in prompt templates1 min read·Apr 23, 2024----