Difference of Overfitting & Underfitting
Any machine learning model performance may result poor due to some reasons like overfitting & underfitting. We have to minimize the cost function. To do this we need to train the model well. In regression problem we cannot simple draw the line by anywhere. If we do so, error rate will be increased. Before we dive into this we need to understand two terminology called Bias & Variance.
Bias : This is the term defined by the difference between y prediction & y actual. High bias means the model is unable to capture important features in our data sets & low bias always make small assumptions when the model is too simple.
Variance: This is the variation of the values of the prediction if we change our training dataset values. High variance means there will be much difference between y prediction & y actual if we change training data. Low variance means variation will be low between y prediction & y actual if training data changes.
Bias Variance Complexity:
- Low bias & low variance is the ideal condition in theory only, but practically it is not achievable.
- Low bias & high variance is the reason of overfitting where the line touch all points which will lead us to poor performance on test data.
- High bias & low variance is the reason of underfitting which performs poor on both train & test data.
- High bias & high variance will also lead us to high error.
Overfitting: If the fitted line touches all the data points, it performs very well in training data but it performs very poor on test data. So test accuracy is not so good.
Underfitting: If the fitted line is highly bias, neither it performs well in training data nor on test data. So both train & test accuracy is poor.

To find out the best fit line we have to do a bias variance trade off.

Total error = error due to Bias+ error due to Variance
When the Bias increases automatically variance decreases and vice versa also. So We have to find a optimal position for error due to biases & variances minimized. We can find the position in some ways that we have to learn.
- Regularization technique
- Cross Validation
- Feature Scaling
- Tuning the parameters of the model
Regularization Technique:
It is used for many types of regression. It adds a penalty term to neutralize the error term.
X1,X2… are the independent features
β0, β1,…..βn are the coefficients of features

Now we have to add a penalty term equal to this residual sum of sqaures. We can do this in two ways of regularization.
- Ridge Regression: Here we introduce small amount of bias term called Ridge Penalty. Lambda, a hyperparameter to be tuned, is multiplied with the summation of squared of the coefficients. When we have multicollinearity of some independent variable we can go for ridge regression. So MAE & RMSE errors in ridge regression are less than that of linear regression. Its called L2 regularization.

2. Lasso Regression: Here we introduce small amount of bias term called Lasso Penalty. Lambda, a hyperparameter to be tuned, is multiplied with the summation of mod values of the coefficients. It helps us by making some coefficients of features zero. So MAE & RMSE errors in lasso regression are less than that of linear regression. Its called L1 regularization. But unlike ridge, Lasso will be unable to make model if there is multicollinearity.

This way adding penalty term will help us to avoid the error.
2. Cross Validation: It divides the dataset into train & test set k times.

We can divide the dataset by k ways for k times into the train set & test set. Every time we get some error. Finally the model automatically evaluate the models perfection. There are three techniques we can use.
- Hold-out (The dataset divided into a Test set & train set)
- K-folds (The dataset divided into a Test set & train set for k times, generally it gives the model more accuracy than hold out)
- Leave-one-out (The dataset divided into a Test set & train set for n times where n=no of records, it is special type of K fold cross validation)

3. Feature Scaling:
We do feature scaling to do scale the data. If there multiple independent features having scale on very different ranges we need to do scaling by either normalization or standardization. We use minmax scaler & standardscaler respectively for this. Please click the link for the detail analysis for scaling.
4. Tuning the parameters of the model with help of Grid search or grid search CV. The parameters are following as such:
In KNN model: K value, batch size, no of epochs etc.
In logistic regression: C value, random state.
In SVC model: The kernel, C.
In Decision tree: The max depth, the criteria.
In Lasso Regression: The alpha.

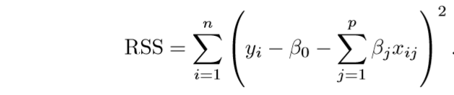{kind=link}
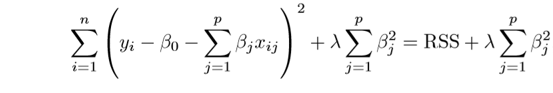{kind=link}
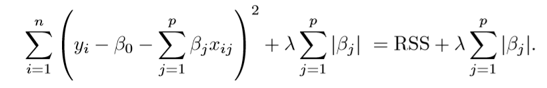{kind=link}