Easiest way to understand CNN (Convolution Neural Network)
HI,……I am SOUMEN DAS, I am trying to break-down step by step procedure of CNN in depth intuition.
We are living a AI society, Where a computer System has ability to see, hear, talk, even it sence like a Human. In some case, in some domain , it’s much appreciable than a human being.
In this blog, we will see how a Computer can see and can realize the the objects though a camera.
On the bellow image (fig1), we can see one image has passes through a black box, called “Convolution Neural Network ” and magically will have a power to detect the object on the image.

Source of the Image
Let’s open the BLACK BOX……….
Introduction :
In human Brain, We Have cerebral cortex , The cerebral cortex mostly consists of the six-layered neocortex that help us to see. So, now if we want to give power to see to a machine , we have to create something “artificial ” same as neocortex. Convolution Neural Network is a process to give power to see a objects and analyses and detect the objects for a computer.
Convolution Neural Network is a variant of Neural Network.
It is widely used in Field of Computer Vision. It’s inspired by the visual cortex of Animal Brain.
CNN consists these layer:
- Convolution Layer
- Activation Layer
- Pooling Layer
- Fully Connected Layer or Dense Layer

The source of the Image
Before we drive depth in it, we must know about the pixelization of a image.
Pixel :
A pixel is the smallest unit of a digital image or graphic that can be displayed and represented on a digital display device.
A pixel is also known as a picture element (pix = picture, el = element)

Gray Image :
Here, Each pixel is represented by single channel, where minimum value is 0,represent Black, and maximum value is 255,represent White.

Source of the Image
{kind=link}
Color Image or RGB Image :
Here, Each pixel is represented by three color channel Red, Green, Blue, (R-G-B), where for each channel minimum value is 0, and maximum value is 255.


Source of the Image
1. Convolution Layer :
It is the very First layer on CNN, where model try to fetch features of a Image. This layer is also called Feature Extractor Layer.
Then Question Occurs ,What is Feature?
Feature is basically information about the types of edges , different types of shapes of any image.
But how does feature extraction happen ? That follows below :
Convolution Operation: As convolution is a mathematical operation on two functions that produces a third function that expresses how the shape of one function is modified by another.
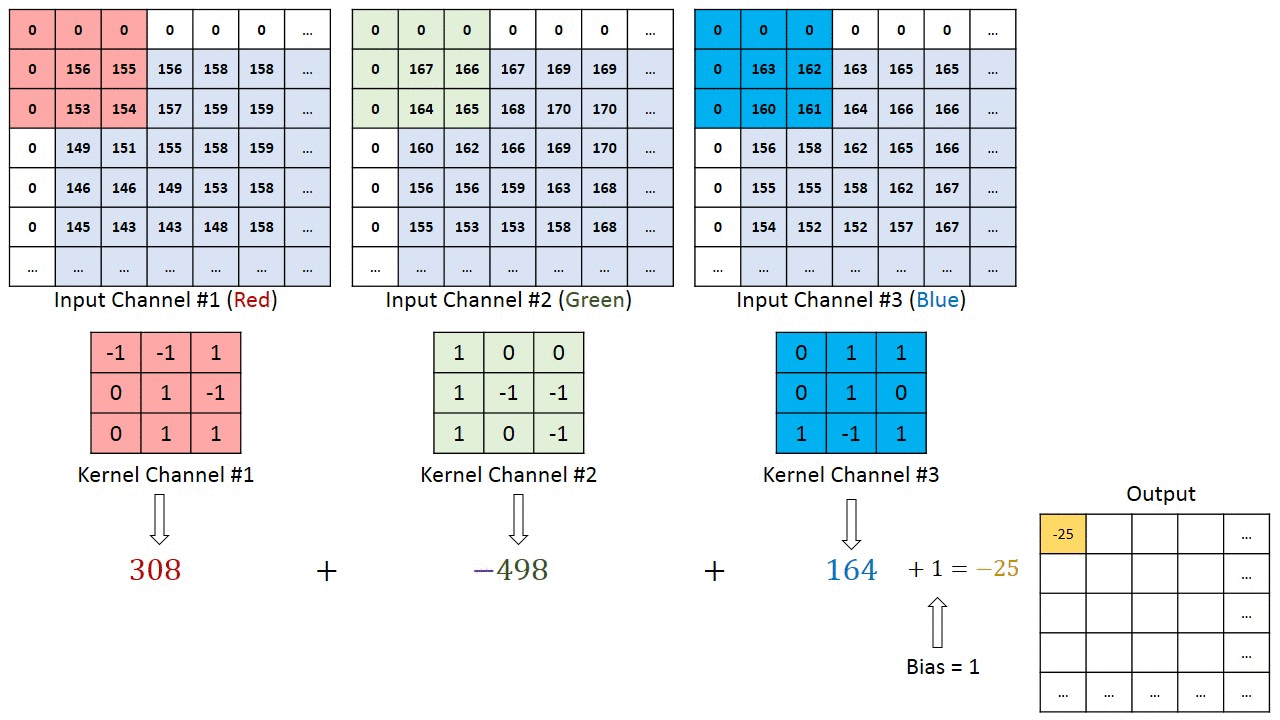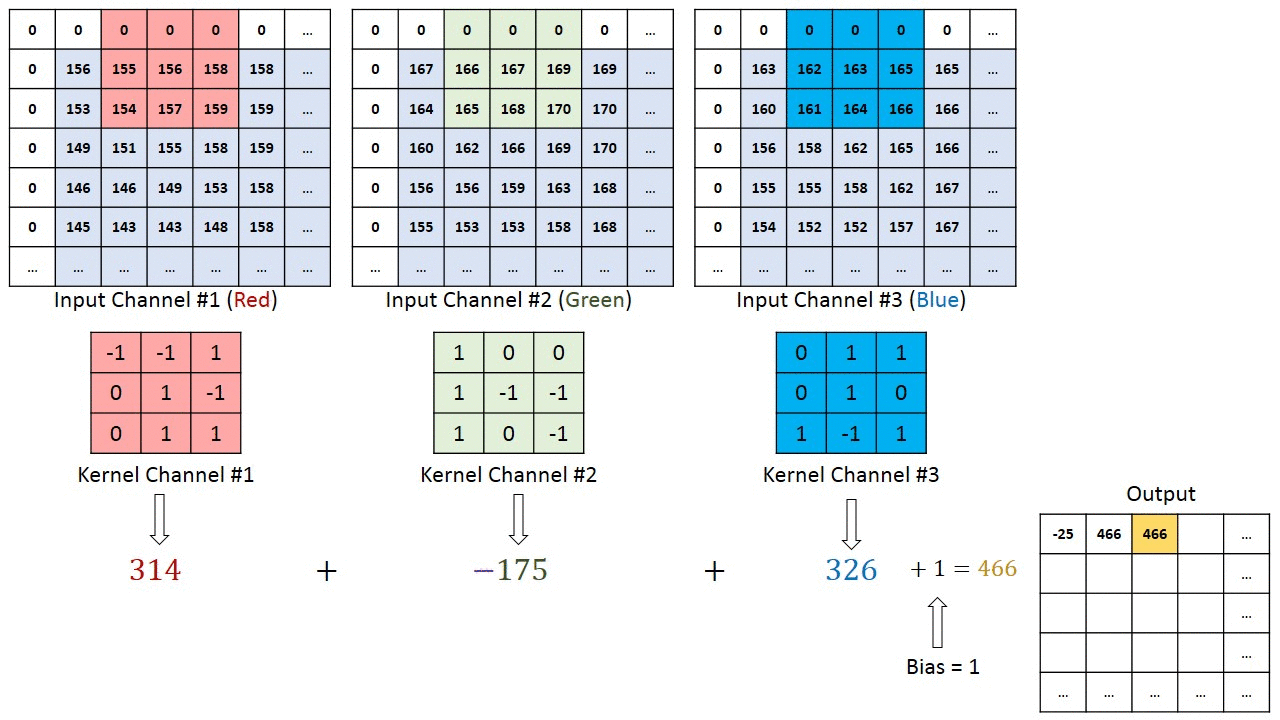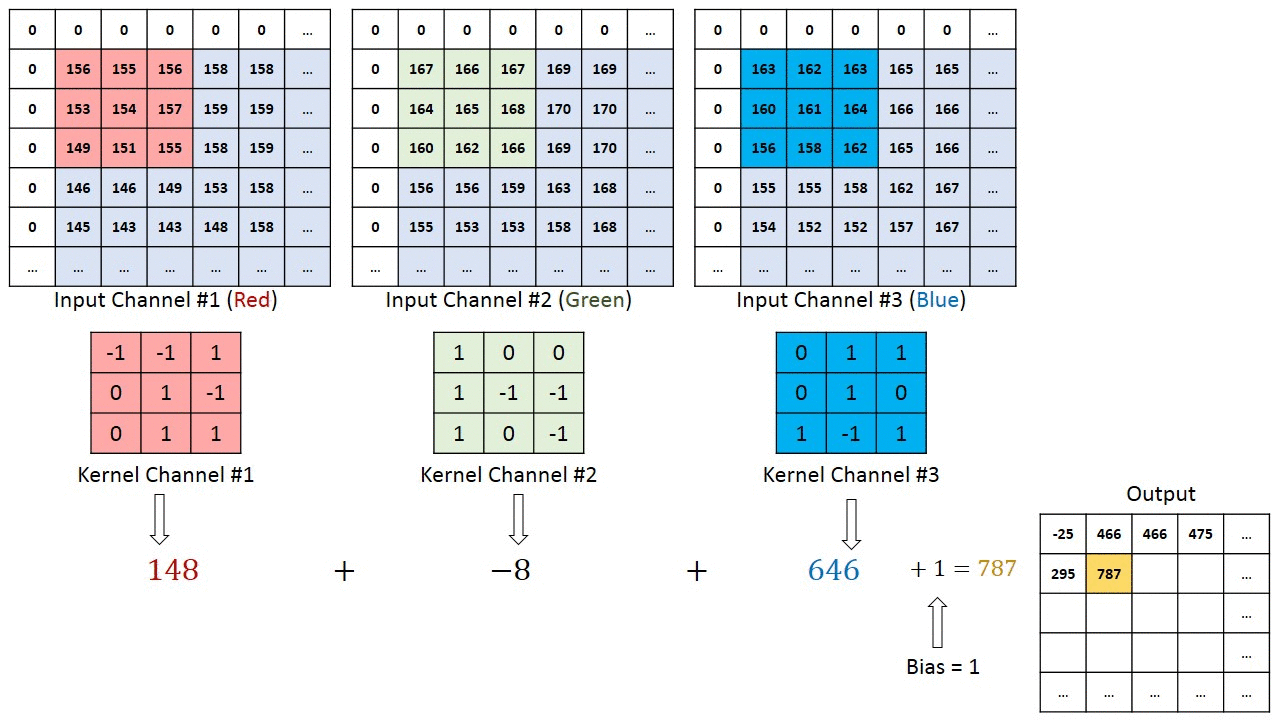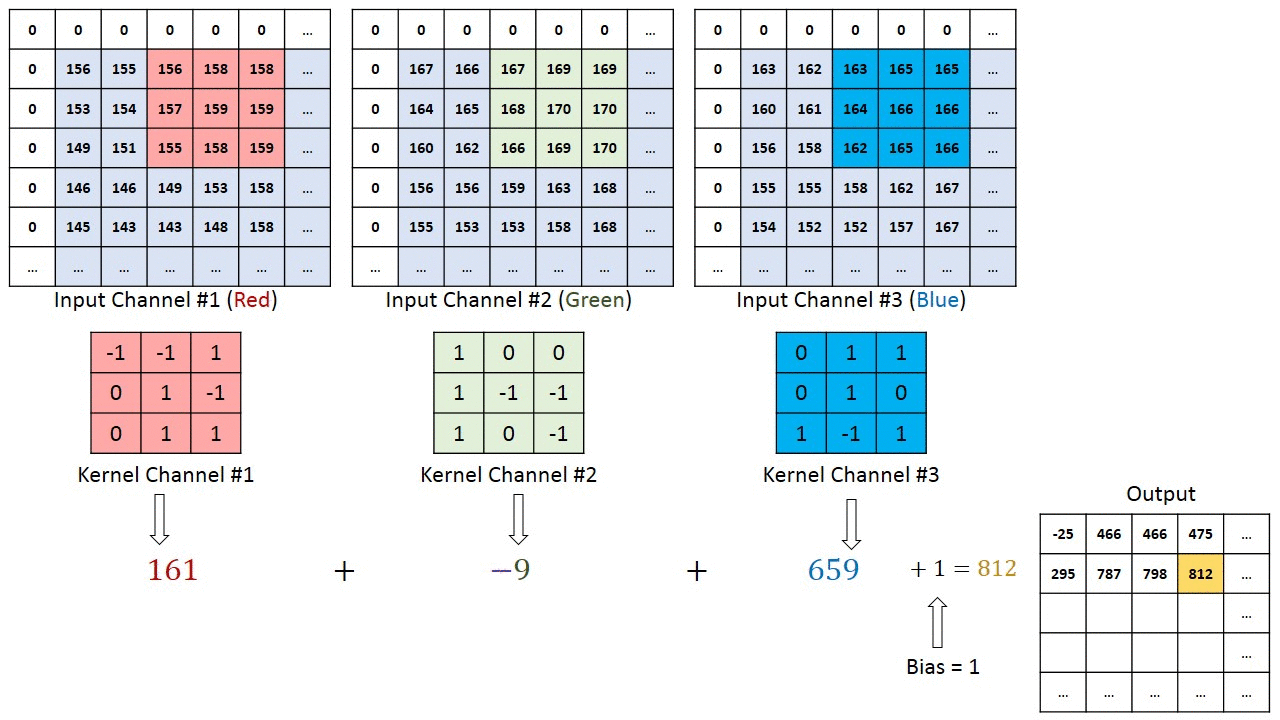
Here, We have image pixel Values (it’s may Gray scale or R-G-B scale) and Some filter/Kernel to create a feature map that summarizes the presence of detected features in the input.
From top left corner, select a block of pixel values on image with same size as filter size, calculate point wise production them add them all to get a single value for top left position on feature map. Then stride it right then down until it reach to right down corner.
See the image and GIF for better understanding…..

Iteration is like this………….see the animation

we convolve the input image with Feature Detector (also known as Kernel or Filter) to generate a Feature Map (also known as Convolved Map or Output Feature Map). This reveals patterns in the image, and also compresses the image for easier processing. Feature Map is generated by element-wise multiplication and addition of corresponding image.
Problem with Simple Convolution Layers
- For a gray scale (n x n) image and (f x f) filter/kernel, the dimensions of the image resulting from a convolution operation is (n — f + 1) x (n — f + 1).
For example, for an (8 x 8) image and (3 x 3) filter, the output resulting after convolution operation would be of size (6 x 6). Thus, the image shrinks every time a convolution operation is performed. - Also, the pixels on the corners and the edges are used much less than those in the middle.
Padding :
Padding is simply a process of adding layers of zeros to our input images so as to avoid the problems mentioned above.

- This prevents shrinking as, if p = number of layers of zeros added to the border of the image, then our (n x n) image becomes (n + 2p) x (n + 2p) image after padding. So, applying convolution-operation (with (f x f) filter) outputs (n + 2p — f + 1) x (n + 2p — f + 1) images. For example, adding one layer of padding to an (8 x 8) image and using a (3 x 3) filter we would get an (8 x 8) output after performing convolution operation.
- This increases the contribution of the pixels at the border of the original image by bringing them into the middle of the padded image. Thus, information on the borders is preserved as well as the information in the middle of the image.
Types of Padding
- Valid Padding : It implies no padding at all. The input image is left in its valid/unaltered shape.
Image[(n x n)] * Filter[(f x f)] → New Image[(n — f + 1) x (n — f + 1)]
2. Same Padding : In this case, we add ‘p’ padding layers such that the output image has the same dimensions as the input image.
Image[(n + 2p) x (n + 2p)] * Filter[(f x f)] → New Image [(n x n)]
Stride:
How many jump , you want your your filter to take when moving to next block of values during Convolution

If stride = 1, the filter will move one pixel.

If stride = 2, the filter will move two pixels.

finally, shape of feature map will be,

Convolution Layer With Padding :

Source of GIF
{kind=link}
Parameter Shared Weights And Biases :
CNNs, like neural networks, are made up of neurons with learnable weights (filters/ kernels ) and biases. Each neuron receives several inputs, takes a weighted (filter) sum over them, pass it through an activation function and responds with an output.
Parameter sharing is sharing of weights of a filter by entire convolution in a particular feature map.
How to Define number of filter in a convolution layer?
If we want to detect n number of features in an image , n number of filters are being applied to the image again and again and stack them channel wise , to get only one output feature map /Convolved Map.(As, done in the last image.)

Source of Image
In the above image , there are 2 filter with (3*3) size, and generated 2-D channel feature map. If we take n filter, will get n-D feature map as well.

Time to see How really Convolution effect on Feature Extraction:

2. Activation Layer :
Simply put, an activation function is a function that is added into an neural network in order to help the network learn complex patterns in the data. The activation function is at the end deciding what is to be fired to the next neuron.
An ACTIVATION LAYER is always followed by Convolution Layer, After each convolution layer in a CNN, we apply a nonlinear activation function, such as ReLU, ELU, or any of the other Leaky ReLU variants.

RELU: We typically denote activation layers as RELU in network diagrams as since ReLU activations are most commonly used.

3. Pooling Layer :
After Convolution and Activation, the next layer is pooling layer. It help to reduce feature map values, that reduce computation efficiency.
Types of Pooling
- Max pooling : This time you’ll place a 2×2 box at the top-left corner, and move along the row. For every 4 cells your box stands on, you’ll find the maximum numerical value and insert it into the pooled feature map.
2. Average Pooling :This time you’ll place a 2×2 box at the top-left corner, and move along the row. For every 4 cells your box stands on, you’ll find the average numerical value and insert it into the pooled feature map.

(nh - f + 1) / s x (nw - f + 1)/s x nc
nh - height of feature map
nw - width of feature map
nc - number of channels in the feature map
f - size of filter
s - stride length
4. Fully Connected Layer or Dense Layer :
Dense layer is final layer on the model. It is same as normal Artificial Neural Network.
Before sending feature map to Dense Layer, we need to flatten the feature map.

The reason we do this is that we’re going to need to insert this data into an artificial neural network later on.

Dense Neural Network is Sequential Combination of layer with neuron connected with each other. For each connection link, there assign some Weights , and perform weighted sum for a node and pass through a activation function and forward the result to next node. From the last layer/output layer we Predicted output.
For better understand Neural Network , a link is given here…………
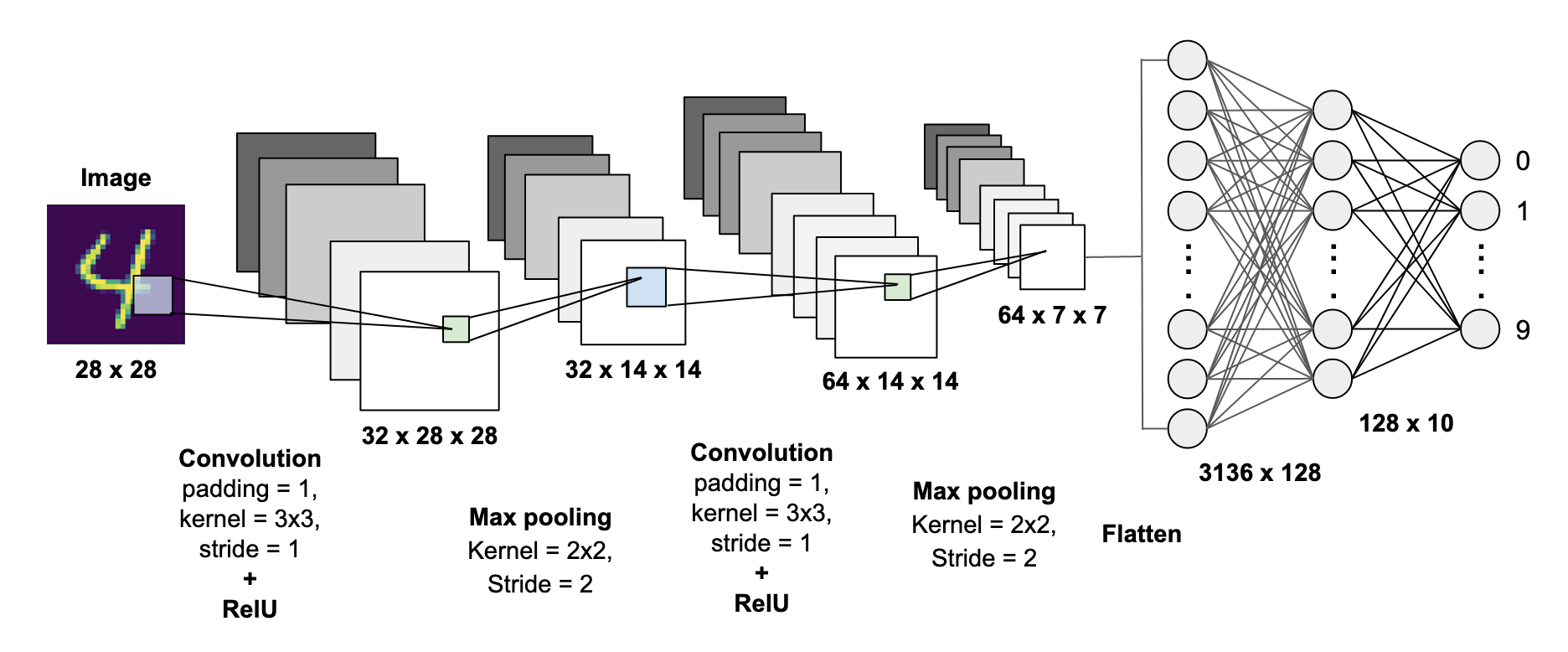
Complete Architecture of Convolution Neural Network for hand written numeric digit recognition model on MNIST data set.

Source of the Image
{kind=link}
Architecture of the CNN
Input size is 28*28
1st Convolution Layer with kernel 3*3, padding=1 ,stride=1 ReLU Activation
1st Max pooling with kernel=2*2 ,stride=2
2nd Convolution Layer with kernel 3*3, padding=1 ,stride=1 ReLU Activation
2nd Max pooling with kernel=2*2 ,stride=2
Final feature map shape 7*7*64
Flatten size=7*7*64=3136
Dense layer with 128 neuron
Output layer with 10 neurons, and Soft-max Activation
Code in Python for a American Sign language detection using CNN Git-hub link is here.
For back propagation on Convolution Neural Network , a link is given here…………