In Depth intuition of Artificial Neural Network (ANN) for Beginners
HI,……I am SOUMEN DAS,I am trying to represent easiest way of ANN in depth intuition.
Neural Network is back bone of Deep Learning, has major Contribution on Deep Learning such as Computer Vision and Natural Language Processing . let’s see….

Source of Image
{kind=link}
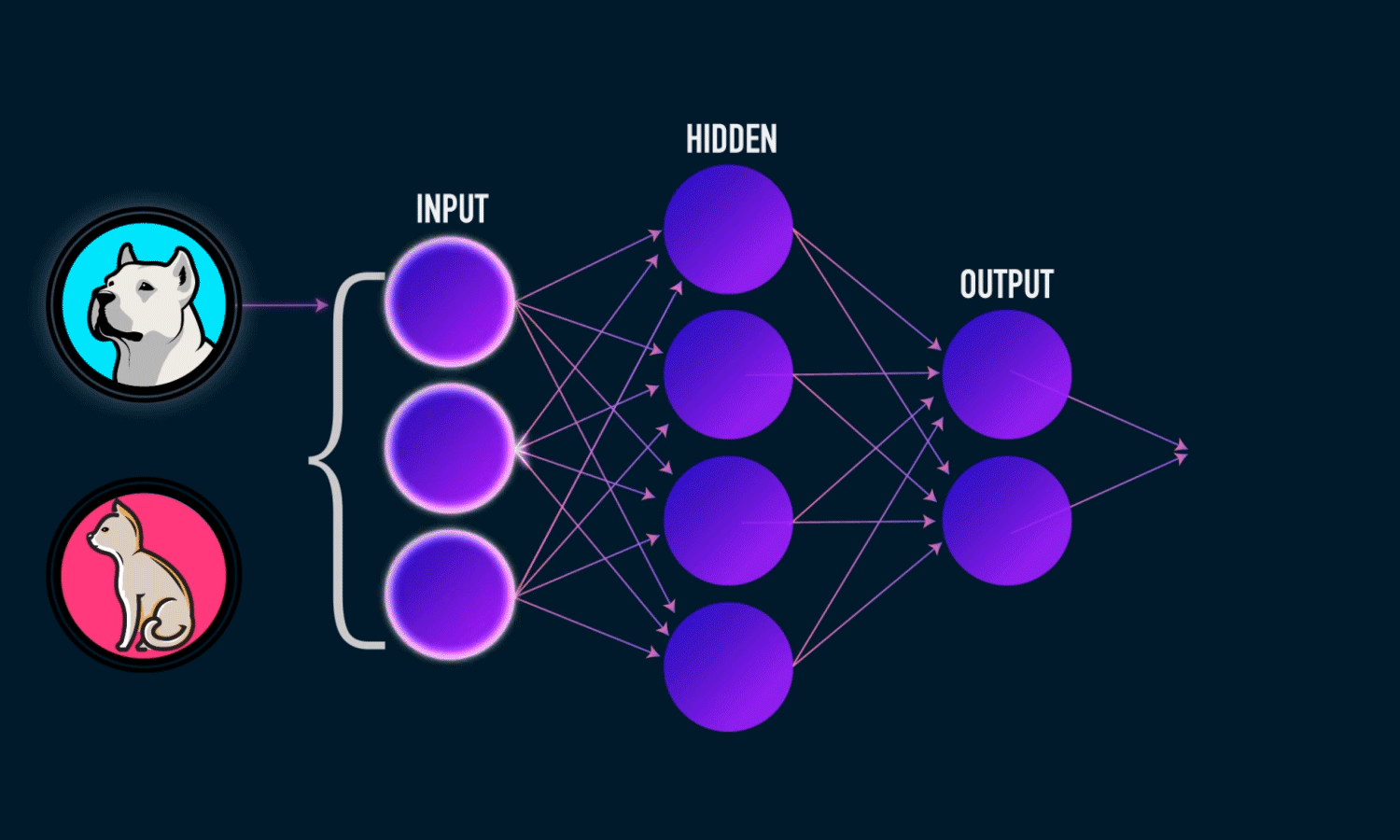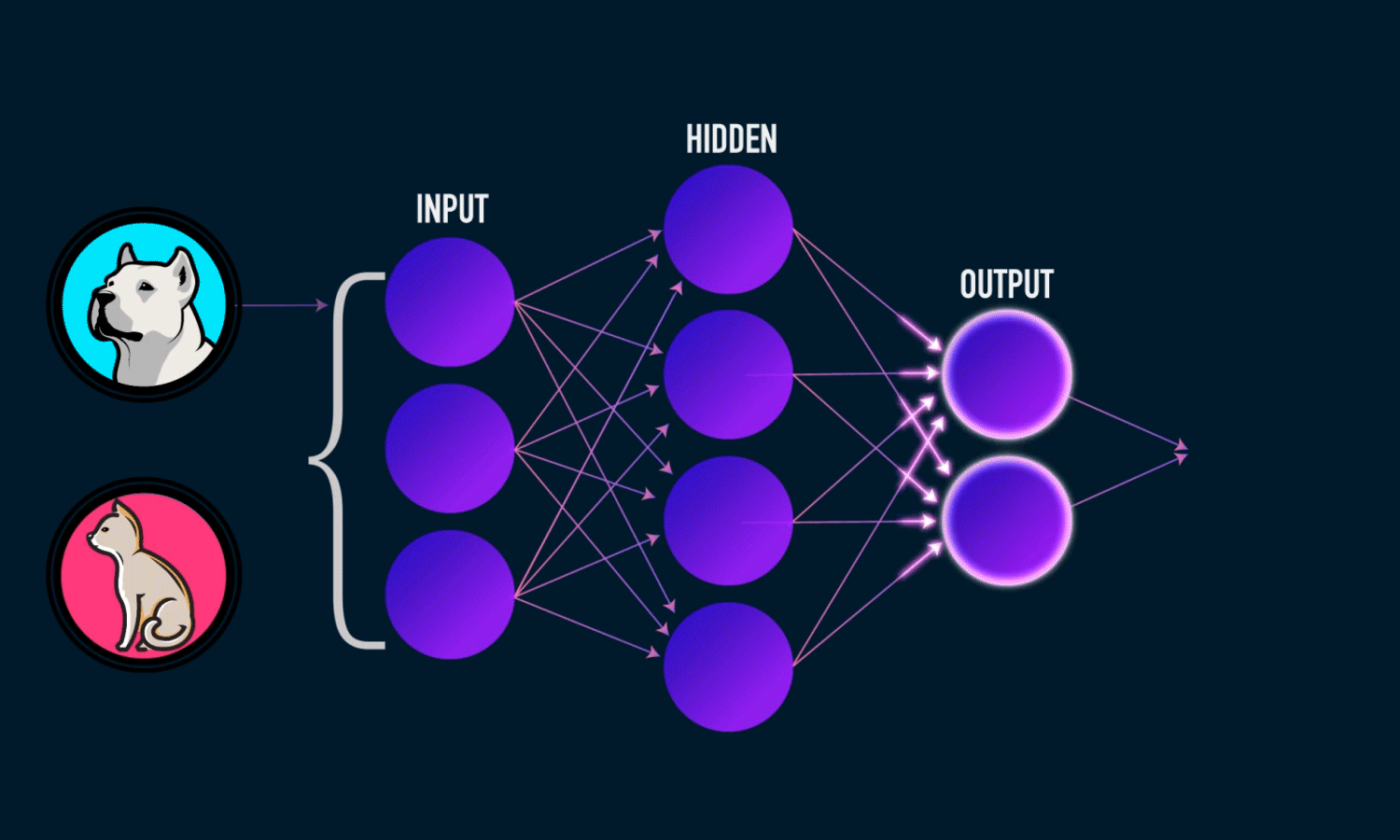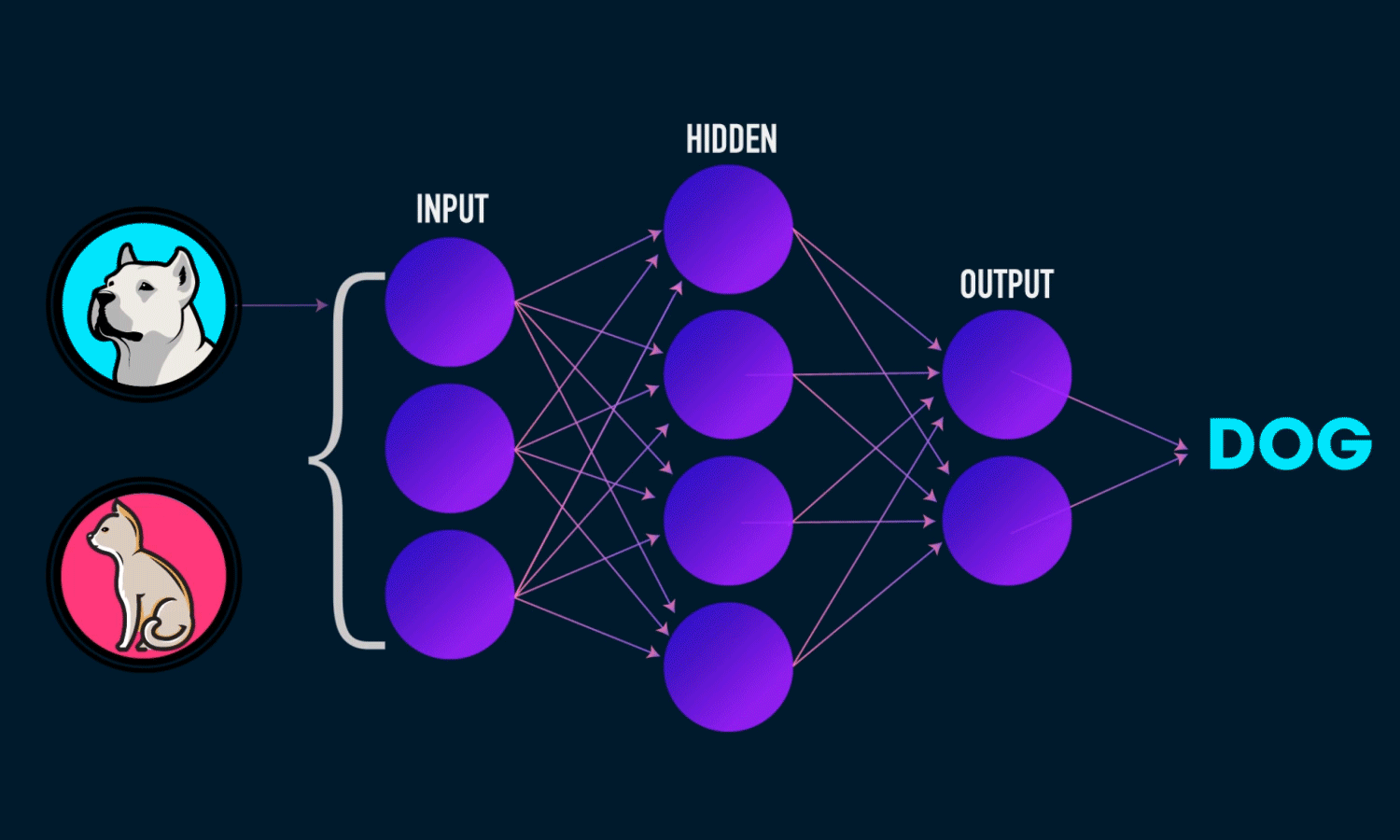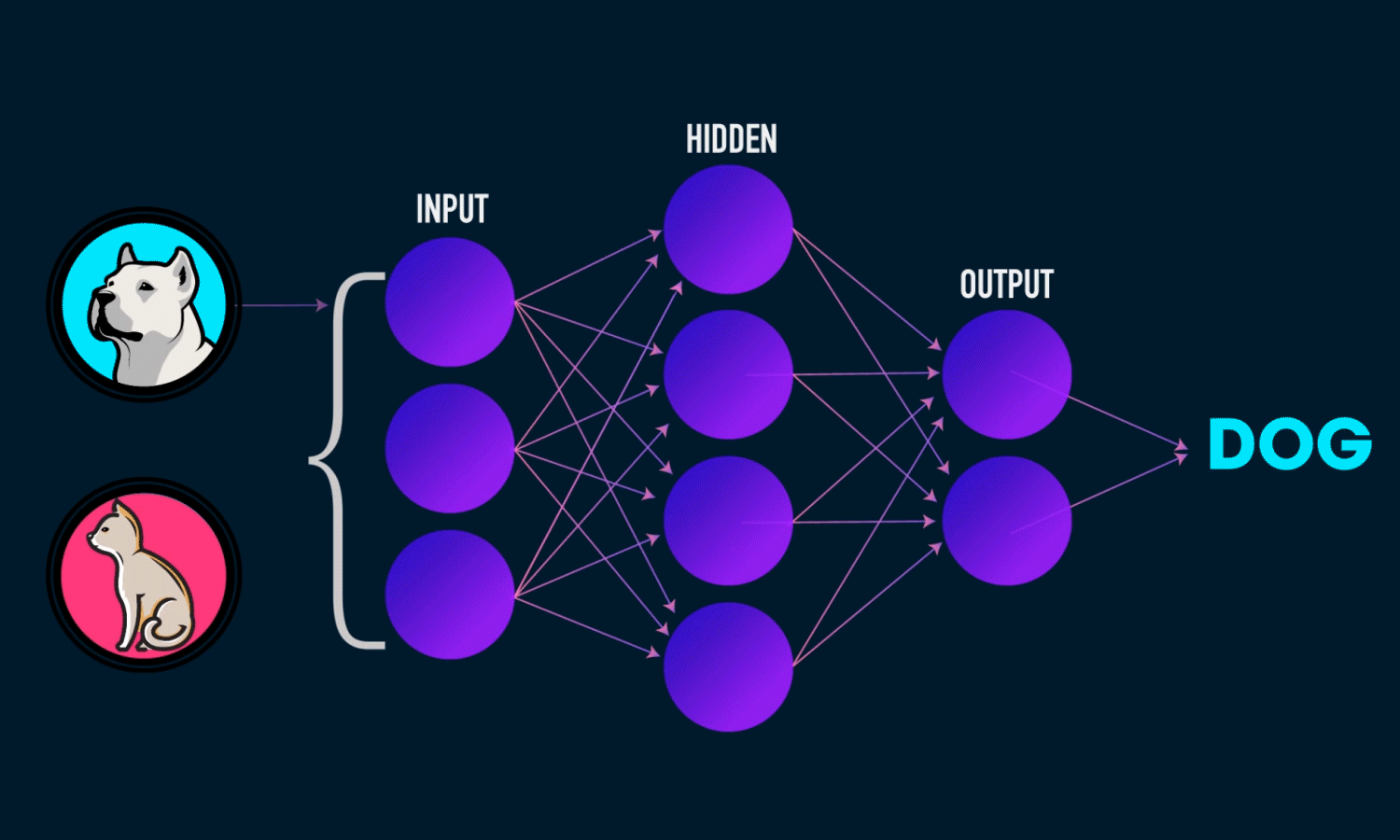
In the [Fig1] ,we can see Machine has power to take Decision By a Neural Network model.
Then Question Occurs ,What is Neural Network?
Let’s start with some prior Knowledge, and break down complete process of Neural Network model.
Artificial intelligence :
Artificial intelligence (AI), the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings.
Artificial intelligence is the simulation of human intelligence processes by machines, especially computer systems.
Machine learning :
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
The process of learning begins with observations or data, such as examples, direct experience, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow the computers learn automatically without human intervention.

Deep Learning :
Deep learning is an artificial intelligence (AI) function that imitates the workings of the human brain in processing data and creating patterns for use in decision making.
Deep learning is a subset of machine learning, which is essentially a neural network with three or more layers.
These neural networks attempt to simulate the behavior of the human brain — albeit far from matching its ability — allowing it to “learn” from large amounts of data.
While a neural network with a single layer can still make approximate predictions, additional hidden layers can help to optimize and refine for accuracy.
What is Neural Network !!!!!!
Fight of Biology vs technology
Just like a biological neuron has dendrites to receive signals, a cell body to process them, and an axon to send signals out to other neurons.
The artificial neuron has a number of input channels, a processing stage, and one output that can fan out to multiple other artificial neurons.[fig3]

Source of Image
ANNs incorporate the two fundamental components of biological neural nets:
1. Neurons = Nodes (Processing Unit)
2. Synapses = Weights (Learning Parameter )
Weights :
Weights is a learning parameter for a neural network. It’s like how much importance we are giving to a specific input. The importance is calculated by Multiplying Weights with corresponding Inputs. Initially all weight assign to zero . During training it updates through a optimizer and fit to best weight for a model. Finally, Model gives a best predicted result, Then, We can say weight has learned.
The idea of weight is a foundational concept in artificial neural networks. A set of weighted inputs allows each artificial neuron or node in the system to produce related outputs.
The weight shows the effectiveness of a particular input. More the weight of input, more it will have impact on network.
Perceptron / Nodes (Processing Unit) :
A single node picked from neural network is called perceptron .

Each perceptron has two function to process it inside
- Weighted Sum : Take all Weights and corresponding Inputs , produce them and Calculate Sum of product.
- Activation Function : Take Weighted Sum pass through a Mathematical Function and produces a decision (either firing or not firing).

Source of Image
{kind=link}
Bias :
Biases, and their relationship with errors and predictions, are in fact a problem that characterizes not only machine learning, but also the whole discipline of statistical analysis.
Bias is like the intercept added in a linear equation. It is an additional parameter in the Neural Network which is used to adjust the output along with the weighted sum of the inputs to the neuron. Therefore Bias is a constant which helps the model in a way that it can fit best for the given data.
Try to understand Neural Network with proper Example:
Hypothesis :
Suppose , we have Set of input features X={x1, x2, x3, ….., xN } and target feature /Class Y. Between X and Y there is Functional dependency Y=f(X) . The actual relationship between X and Y is f(X), called Target Function.
Now, We are trying to get/ predict functional dependency between input and output . Y’=f’(X). Where f(X)=f’(X)+E or Y=Y’+E . E is error here, Difference between Actual output and Predicted output. We have to find a f’(X) such that E is close to zero , f’(X) is close to f(X). f’(X) is called Hypothesis.
Hypothesis Space :
For a Dataset with N features will may have 2^N possible Hypothesis . Set of all legal hypothesis is called Hypothesis space. Our goal is to find best hypothesis (fitting curve) that fit perfectly with input and output among Hypothesis Space

All these legal possible ways in which we can divide the coordinate plane to predict the outcome of the test data composes of the Hypothesis Space.
Each individual possible way is known as the hypothesis.
Example-
AND Gate :
The Truth table of AND Gate is given bellow, The output is 0 and 1, it’s Classification problem .

Using a single perceptron , With a linier equation Y’=A*w1+B*W2+Bias Bias=(-1.5) , We can separate the target class.

OR Gate :
The Truth table of OR Gate is given bellow, The output is 0 and 1, it’s Classification problem .

Using a single perceptron , With a linier equation Y’=A*w1+B*W2+Bias Bias=(-0.5) , We can separate the target class.

X-OR Gate :
The Truth table of X-OR Gate is given bellow, The output is 0 and 1, it’s Classification problem .

But , we can see using a single perceptron , With a linier equation Y’=A*w1+B*W2+Bias Bias, it is not possible to classify the output class.
We can separate the target class using two linear equation , h1=A*W11+B*W21 + Bias1 and h2=A*W12+B*W22 + Bias2 We can the Negative and positive class. And finally , we marge h1 and h2 using one perceptron output, Y’=h1*w1+h2*W2+B. The layer between input and output layer is called Hidden Layer .

We can see, When the Dependency function is not linear and complex to define we need some layer of Neuron to Predict the class of output.

Source of Image
In an artificial neuron, a collection of weighted inputs is the vehicle through which the neuron engages in an activation function and produces a decision (either firing or not firing). Typical artificial neural networks have various layers including an input layer, hidden layers and an output layer. At each layer, the individual neuron is taking in these inputs and weighting them accordingly.
How to Train a Neural Network ?
There is a neural Network with 2 input node, 3 hidden node and 1 output node.

For the above network , Weight and bias matrix of 1st layer is ….

Multiply weight with corresponding inputs and pass through a activation function, and finally get a predicted output from last layer.

How to feed a proper Weights to a Neural Network ?
Error Calculation:
Difference between desire output and predicted output.
Actual/ desire output=Y and Predicted Output Y’ , Then error (E)=Y-Y’
Loss function :
For Regression:

For Classification:


Gradient Descent
As the Error functions is a Quadratic function , has define a from of “U” shape.

To make loss =min , according to the minima theory ,d(L)/d(w) should be 0.

Weight and Bias are learning parameter . Updating Weights and Bias using Gradient Descent (dL/dw) like this…

Learning Parameter
How fast model is learning or getting converging to optimal minima. Alpha (α) is denoting as learning parameter.
Backward Propagation

Chain Rule


CODE :code from Scratch step by step is given in the link