Creating Reddit’s roast_Me AI Roaster bot
In this post I will go through the each and every step from scraping data from reddit api to creating Keras model and try to do my best to explain it to create Reddit Roastme data based model that generate roasts given the input image

What is Roast Me ?
Roast Me is one of the most popular sub Reddit ,where lot of people can take roasts in stride and don’t get hurt by those kinds of insults, so they see it as a way to hear some good jokes about themselves by posting their pics.

Final model result will look something like this :
Note that this are not best sequences generated by this model ,there are some surreal results we got (scroll to last for that :))these are some random picked results
Nerd Alert:The below part is completely skip able its assumes that you are familiar with of Machine learning & Python,It shows the whole technical procedure goes behind to create this ,you can directly skip to last Prediction part
Outline:
This will be a long post ,so to better organize all the methods into sections
- Deep Learning Refresher
- Choosing appropriate model for this problem
- Exploring data through Push shift reddit api
- Cleaning data and package it for training
- Exploring steps for creating our model (Inputs & Outputs)
- Start training the model on packaged data (On approach 1)
- Saving Model and Making Predictions from it or [ Doing Roast :)]
- Next steps (Apply approach 2)
Deep Learning in Brief

Now there are various ways in ML that we can use it to generate sentence,we decided to go with most modern way possible to generate text given image
We will use neural network based model in this
Neural Network
The model that we are going to use will be combination of
CNN(Convolution neural network) & LSTM (Long short-term memory)
Before diving into directly into model code and its structure let’s do little revision on neural networks and explore its types in brief
What is neural networks ?(Best explanation of NN I’ve ever seen by Michael Neilson)
How does the neural networks learns ?
Note that this is really high level overview of neural networks,since covering whole part is beyond the scope of this post although I’ll link to to many post to explore a particular part that all we use
In learning process of neural network first we randomly assigns weights to each unit ,After initialisation of weights we feed input data to input layer each single node in input layer compute Linear function and gives output which is used as input to next layer to compute activation function(Non linear) and that output is used by next layer and this cycle repeats until we reach Output layer (Forward Propagation)
The output layer gives output ,that output is use to calculate the error by using its actual output that error is use to compute gradients using chain rule for each weights in each node,which we will use to nudge down the weights to its best fit(Backward propagation)

MLP(Multi layer Perceptrons)
A multilayer perceptron (MLP) is a deep, artificial neural network. It is composed of more than one perceptron. They are composed of an input layer to receive the signal, an output layer that makes a decision or prediction about the input, and in between those two, an arbitrary number of hidden layers that are the true computational engine of the MLP. MLPs with one hidden layer are capable of approximating any continuous function.
MLPs are suitable for classification prediction problems where inputs are assigned a class or label.
On paper we could use MLP for image,but we will get really bad accuracy because MLP does not learns spatial features due to its flat single vector input and fully connected layer but that doesn’t mean FC connected layers cannot use for image classification,but it would need absurd amount amount of training data and computational power to do even a simple image classification
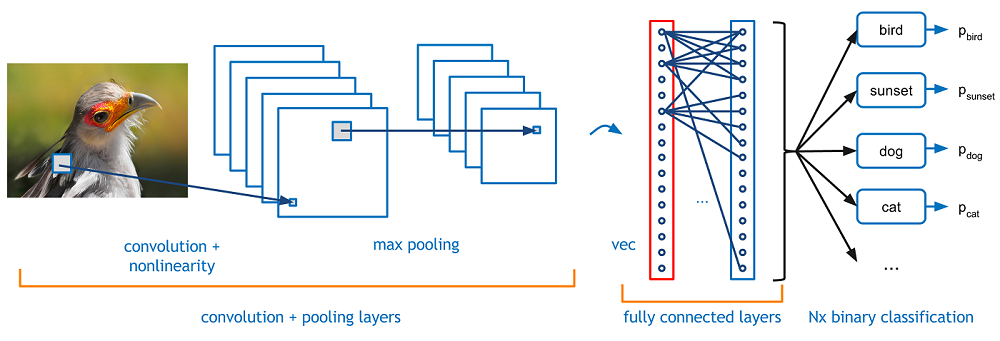
Here comes CNN(Convolution neural network)
Since we are working with images,it would we ideal if we consider data around each pixel intact and consider them as a input which helps in learning spatial features

As you can see we are filtering each input with filter ,so what does CNN looks like?

{kind=link}
Here we are not connecting each every input node to next layer like FC
You can explore much more about CNN in this awesome post about Kernel,channels,Pooling etc
The benefit of using CNNs is their ability to develop an internal representation of a two-dimensional image. This allows the model to learn position and scale in variant structures in the data, which is important when working with images.
The CNN input is traditionally two-dimensional, a field or matrix, but can also be changed to be one-dimensional, allowing it to develop an internal representation of a one-dimensional sequence. Therefore it can also be used in problems where there is an ordered relationship in the time steps of a time series
But for this project we are using CNN just to extract features that can be passed as input along with sequential data different separate RNN to deal with sequential
Recurrent Neural Networks(RNN)
Now MLP & CNN are not ideal choice when training there is sequential data(eg. text data,video frames,time series data etc )
RNN is different type of neural networks which is use to learn sequence
What makes it so special to learn sequence ?

Well you can see the difference between RNN and Feed foward NN ,that the output of the hidden layer in a recurrent neural network is fed back into itself which helps in retaining sequence,but we are not using RNN why ?The problem with vanilla recurrent neural networks, constructed from regular neural network nodes, is that as we try to model dependencies between words or sequence values that are separated by a significant number of other words, we experience the vanishing gradient problem (and also sometimes the exploding gradient problem)this happens because small gradients or weights are multiplied due to its time steps and reduce gradients to 0 ,which does not help to learn long-term dependencies
To tackle this we use LSTM (Advanced version of RNN)

Why LSTM works better ?
Because LSTM gate have various gates like input gate,forget gate & output gate which regulate and store only useful information(its working much deeper than 2 sentence checkout here)
RNNs in general and LSTMs in particular have received the most success when working with sequences of words and paragraphs, generally called natural language processing.
Choosing Method
What model we will use ?We’re gonna go with 2 different approaches
1st ) Model with single Image as a Input and comment as a output
2nd )Model with image as well as Title as input and comment as a output (NEXT POST)
APPROACH 1

Preparing Data for Method 1 :

Fetching Data
To scrape data we will be using Push shift api,the reason we are using this api and not the official reddit api is because we will get a api call limitations after certain large no. of calls which does not happen in Push shift api
here’s the demo api call :
To get the api keys you have to register your application official Reddit Dev Api site
Creating api instance :
import praw
import pandas as pd
import datetime as dt
from psaw import PushshiftAPI
import osreddit = praw.Reddit(client_id='******', client_secret='*********', user_agent='roastme_bot')api = PushshiftAPI(reddit)
To use the Api instance :
subreddit = reddit.subreddit('RoastMe')for submission in subreddit.top(limit=5):
print(submission)
Getting top 5 submissions objects
OUTPUT:
amnyr9
bb6nwq
7eo0zr
5nkbyc
6aeianTo get the data embedded in this classes we can print its attrs
for submission in subreddit.top(limit=1):
print(submission.title)
print(submission.url)
print(submission.comments)OUTPUT :
Title : Thank you for all the support! Seeing complete strangers care about my situation really warmed my heart.URL : https://i.redd.it/s2fi2wr7ibe21.jpg<praw.models.comment_forest.CommentForest object at 0x7f0c8ec8cba8>
As you can see the comment itself is class in submisson class ,to extract that we can loop comments attrs eg.
for comment in submission.comments:Getting data

Inputs:The data which we will feed the model
Now this is really crucial step for our Model,nature of input can have really high impact on model’s performance.
After a lots of trial and error we decided to go with
10 top comments of single post along its corresponding image
Here’s a single sample data looks like
[ImageID.jpg
ImageID comment 1
ImageID comment 2
"
"
ImageID comment 10]Collecting Data
This part of Machine learning where engineers spent majority of time in whole pipeline and likewise we did too!
Starting with api setting :
import datetime as dtstart_epoch=int(dt.datetime(2015, 1, 1).timestamp())data = list(api.search_submissions(after=start_epoch,
sort_type='num_comments',
subreddit='RoastMe' ,filter['url','author','title', 'subreddit'],limit=30000))
This will return a list of top 30000 (sorted by no. of comments) submissions of r/RoastMe from 2015
We could not get these much data at least from single account from official reddit api all credits goes to Push shift,but the problem that we faced during this pushshift’s submission.url which gives the Image link( eg. https://i.redd.it/zhuyuq00pq131.jpg) but we needed an actual image to do that we used urlib to hit the image url and get the image numpy data and convert into image
And also to handle to api limit error for image that we are requesting for image data on official Reddit api’s service we we wraped urlib retry( ) around our loop using try and except
This is what script looks like
Importing all necessary libraries:
import datetime as dtstart_epoch
import cv2
import urllib
import numpy as np
import matplotlib.pyplot as plt
import re
from urllib.error import URLError, HTTPError
from urllib import request
from urllib.request import urlopen
import os
from praw.models import MoreCommentsdeclaring some variables
posts_IDs = []
new_post_ids = []comments_data=open("text_data_v2.txt", "a+")post_ID_list=open("posts_id.txt", "r")posts_IDs = str(post_ID_list.read()).split("\n")print("continuing from {}".format(len(posts_IDs)))all_post_ids = posts_IDs.copy()
iteration = 0
duplicates = 0
You may ask why we are creating separate files text_data_v2.txt(all comments will save here) and posts_id.txt(Record of all Submission IDs that have been saved in data) is because ,since its really a huge data collection process and server failures from our side or from server’s side can stop whole process in between ,so to make it efficient we stored all the IDs and every time process starts the collector checks if that particular post id is present in ID file it skips that
for submission in data:
iteration = iteration + 1
print("On iteration : {}".format(iteration))
comment_counter = 0if submission in all_post_ids :
duplicates = duplicates + 1
print("Duplicates found until now : {}".format(duplicates))
continueif len(submission.comments) < 20:
print("Skipping less comment of {}".format(submission.id))
continue
All the continues that are the conditions to skip if the that post fall under that condition,we also created the jpg condition that you can see in below codeblock,because in many the image were missing so it skips that kind of conditions ,all the saving part are done only if post url a image link
elif str(submission.url).split(".")[-1] == "jpg":
all_post_ids.append(str(submission.id))
new_post_ids.append(str(submission.id))
print(submission.url)
try:
with urllib.request.urlopen(submission.url) as url:
arr = np.asarray(bytearray(url.read()), dtype=np.uint8)
if arr.shape == (503,):
continue
rgb_img = cv2.imdecode(arr, -1)
cv2.imwrite(os.path.join('image_data',str(submission.id)+".jpg"),rgb_img)except HTTPError as e:
if e.code == 502:
@retry(urllib.error.URLError, tries=4, delay=3, backoff=2)
def urlopen_with_retry():
return urllib.request.urlopen(submission.url)
urlopen_with_retry()
if e.reason == 'Not Found':
continue
else:
print ('Failure: ' + str(e.reason))
The above codeblock saves image in image_data directory ,some conditions that I have to highlight is arr.shape == (503,) that basically skips if image is corrupted or its not available another condition e.code == 502 is to handle api limit that I talked about
After this we will save comments
for comment in submission.comments:
if isinstance(comment, MoreComments):
continue
if comment_counter == 10 :
break
a = comment.body
if len(str(a).split("\n")) == 1 and len(a) < 90 and len(a) > 7:
comment_counter = comment_counter + 1
a_filtered = " ".join(re.findall(r"[a-zA-Z0-9]+", str(a))).lower()
print("{}.jpg#{} {}".format(submission.id,comment_counter,a_filtered))
comments_data.write("{}.jpg {} {}\n".format(submission.id,comment_counter,a_filtered))Conditions in comment are pretty straight forward 1st condition is to skip if we get MoreComments error 2nd conditon is to break loop after we saved top 10 comments of that particular post 3rd one is main condition it basically states that save comments only if its not too short and not too long
Finally saving files
comments_data.close()
post_ID_list.close()post_Write_file=open("posts_id.txt", "a+")for post_id in new_post_ids:
post_Write_file.write("{}\n".format(post_id))post_Write_file.close()
Example Log of this :
continuing from 3541
On iteration : 1
Skipping less comment of bvkgnn
On iteration : 2
https://i.redd.it/zhuyuq00pq131.jpg
bvkcf0.jpg 1 study or you ll need to start posting these with far less clothes to make a living
bvkcf0.jpg 2 the asian in me says study but the white in me craves attention
bvkcf0.jpg 3 not the first time you disappointed your parents
bvkcf0.jpg 4 with that giant noggin you are more disproportionate than a child s stick figure drawing
bvkcf0.jpg 5 this isn t right don t dox the girl who gave robert kraft a tug at that spa
bvkcf0.jpg 6 never say that to your barber again
bvkcf0.jpg 7 what s it like having micro everything
bvkcf0.jpg 8 there was less sunken chest on pirates of the caribbean
bvkcf0.jpg 9 i ve seen more meat on a coat hanger
bvkcf0.jpg 10 you look like the boyfriend in a documentary about obscenely fat womenOn iteration : 3
Skipping less comment of bvkbaq
On iteration : 4
Skipping less comment of bvk9zn
On iteration : 5
Skipping less comment of bvk2ew
On iteration : 6
Skipping less comment of bvjyvg
On iteration : 7
Skipping less comment of bvjtib

And in image_data dir should be get filled with image along with text_data.txt & posts_id.txt files
Up To this I think we are done with data cleaning and collecting : )
Cleaning & Pre-processing data

Now we have data ,lets now work on model creation
To extract feature data from image we will use CNN for that we can write our own custom cnn but to save time lets direclty use a pre-trained model :
VGG(Pre trained CNN model)
To use it we will use Keras(Deep learning Framework)
Importing VGG and other methods of keras
from os import listdirfrom pickle import dump
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.vgg16 import preprocess_input
from keras.models import Model
import stringInstantiating keras VGG & other required classes
NOTE :Before directly passing image into VGG we have to remove the softmax output layer which is use to give probability distribution of imagenet classes using .pop( ) method and and directly save the features extracted from all previous layers and save it into dict
We will now iterate image_dir and and reshape each image then pass it to model and save its output
model = VGG16()
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
features = dict()for name in listdir('image_data'):
filename = directory + '/' + name
image = load_img(filename, target_size=(224, 224))
image = img_to_array(image)
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) image = preprocess_input(image)
feature = model.predict(image, verbose=0) image_id = name.split('.')[0] features[image_id] = feature print('{}'.format(name))
Now we have features dict which have all the image feature data, let save that into pickle file
dump(features, open('image_features.pkl', 'wb'))Text data preparation
To clean text data first lets load text data into memory and read
file = open('text_data.txt', 'r')descriptions = file.read()
Now we have data into memory lets split by new line & create condition if length of spitted line which will have image name & comment data ,that list must have 2 elements if does not skip that line then remove ID from image name and save comment data(image_desc) into image_id key into mapping dict
mapping = dict()
for line in descriptions.split('\n'):
tokens = line.split()
if len(line) < 2:
continue
image_id = tokens[0]
image_desc = tokens[1:]
image_id = image_id.split('.')[0]
image_desc = ' '.join(image_desc)
if image_id not in mapping:
mapping[image_id] = list()
mapping[image_id].append(image_desc)Now we’ll remove the punctuation with white space maketrans( ) using and also remove single ‘a’ & ‘s’
table = str.maketrans('', '', string.punctuation) for key, desc_list in descriptions.items():
for i in range(len(desc_list)):
desc = desc_list[i]
desc = [w.translate(table) for w in desc]
desc = [word for word in desc if len(word)>1]
desc = [word for word in desc if word.isalpha()]
desc_list[i] = ' '.join(desc)
Extracting all vocabulary
all_desc = set()
for key in descriptions.keys():
[vocabulary.update(d.split()) for d in descriptions[key]]Saving into clean txt file
lines = list()
for key, desc_list in descriptions.items():
for desc in desc_list:
lines.append(key + ' ' + desc)
data = '\n'.join(lines)
file = open('cleaned_data.txt', 'w')
file.write(data)
file.close()Now we have all the cleaned data let’s build model now
Building Model
Since our model will have multiple inputs we will use Keras Functional API
Before defining that lets load cleaned data into memory
Loading Cleaned text data
file = open('cleaned_data.txt', 'r')
text_data = file.read()
file.close()Loading Clean Data and creating new descriptions set
descriptions = dict()for line in text_data.split('\n'):
tokens = line.split() image_id = tokens[0]
image_desc =tokens[1:] descriptions[image_id] = list() desc = 'startseq ' + ' '.join(image_desc) + ' endseq'
descriptions[image_id].append(desc)y_descriptions = set(descriptions)
Loading image features from pickle data by dataset(list of all id)
dataset = list()for line in text_data.split('\n'):
identifier = line.split()[0]
dataset.append(identifier)all_features = load(open('image_features.pickle', 'rb'))
features = {k: all_features[k] for k in dataset}X_features = features
we have now X_features(image data) & y_descriptions(text data)
Generating Encoding
We cannot directly feed text data into we have to tokenized units(assigning each each words a unique number) since we are building world level rather than character level model
Keras preprocessing class provide a wonderful tokenization class we will use that, although you can use anything you want like NLTK
To tokenize we’ll use fit_on_texts() function
from keras.preprocessing.text import Tokenizertokenizer = Tokenizer()lines = list()for key in descriptions.keys():
[lines.append(d) for d in descriptions[key]]tokenizer.fit_on_texts(lines)
We also be needing max word in among each line
max_length = max(len(d.split()) for d in lines)Digging into model

The problem that we are trying to solve here is little complex here than compare to plain Computer vision or NLP tasks ,here we are combining both
The structural unit we will follow here is recursively unit

We will use Encoder ( A model that reads the image input and encodes the content into a fixed-length vector using an image feature) — Decoder ( A model that reads the encoded vector data and generates the textual description output) structure where we will encode image data and text data into vector then decode that into text,state of the art models for that type of structure is Inject & Merge model
We’ll go with merge model
Merge Model
It requires both methods from computer vision to understand the content of the image and a language model from the field of natural language processing to turn the understanding of the image into words in the right order. Recently, deep learning methods have achieved state-of-the-art results using merge model ,so what’s merge model ?
In merge model we’ll combined encoded data of image input with text generated then feed that to decoder to predict next word

To feed data into recursively unit based model we have to format data like that ,example(data like image and its comment you look like fool will become
X1, X2 (text sequence), y (word)
image startseq, you
image startseq,you, look
image startseq,you,look, like
image startseq,you,look,like fool
image startseq,you,look,like endseqto do this
X1, X2, y = list(), list(), list()for key, desc_list in descriptions.items(): for desc in desc_list: seq = tokenizer.texts_to_sequences([desc])[0] for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] X1.append(photos[key][0])
X2.append(in_seq)
y.append(out_seq)
Here in above code ,we are saving output as a one hot encoded and also pad each descriptions to max length
Defining a model
We’ll use keras functional api to create model since we have to deal with multiple input addition
Image extractor model expects a 4096 dimension vector
image_input = Input(shape=(4096,))
fe1 = Dropout(0.5)(image_input )
fe2 = Dense(256, activation='relu')(fe1)Now for LSTM model,first layer is a word embedding layer(This will convert our words (referenced by integers in the data) into meaningful embedding vectors.This Embedding() layer takes the size of the vocabulary as its first argument, then the size of the resultant embedding vector that you want as the next argument. and Finally we will pass text_input into it in functional api way and add dropout layer to prevent overfitting
Coming to next layer adding LSTM layer with hidden size 256(hidden size is the number of nodes in the hidden layers inside LSTM cell, e.g. the number of cells in the forget gate layer, the tanh squashing input layer and so on.)
text_input = Input(shape=(max_length,))
se1 = Embedding(vocab_size, 256, mask_zero=True)(text_input)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)Finally we will add both layer using Keras add( ) then followed by a softmax layer for output and compile it
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) model = Model(inputs=[inputs1, inputs2], outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')

Fitting the model and giving save path for model weight
filepath = 'weights-improvement-{epoch:02d}-{loss:.4f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=2, save_best_only=True, mode='min')model.fit([X1, X2], y, epochs=35, verbose=2, callbacks=[checkpoint], validation_split=0.2)
Training

We trained on 1500 data for 20 epochs ,this is last epoch log
Epoch 00020: loss improved from 2.86418 to 2.76852, saving model to weights-improvement-20-2.7685.hdf5
Doing Prediction[or Roasting ;)]

Now we will plugin weights-improvement.h5 into model.predict( ) & see how the model is roasting
My thoughts

I did not expected this model to be perform even avg because we trained this on very less data and on GTX 1060 6gb GPU with very small models but what really shocked us are some of the below results
Being a skyrim fanboy you can clearly see what’s model is trying to predict :),Its accounting hair maybe or something and comparing that to skyrim characters which you look below ,you can why its seeing resemblance
Similar in below result its acknowledging things from image too clearly
Some other mediocre results

Next steps
This post has been more kind of proof of work,we can definitely improvise a this existing model by using more heavier models like Transformer for Sequence model and Resnet CNN models for Image models
But before that we also try to integrate Title input along with image of reddit submission for approach 2 in next post or we will extend this

