Michael SpectorPostgreSQL HA Cluster in KubernetesWe all know how easy is setting up an Amazon RDS-based PostgreSQL cluster with automatic failover that just works out of the box. There are…Apr 12, 20182Apr 12, 20182
Michael SpectorinViyaDBAnalyzing 1 Billion of User Events with ViyaDBViyaDB is rapidly developing open source in-memory OLAP database that facilitates ad-hoc queries on unordered data (in contrast to…Feb 26, 2018Feb 26, 2018
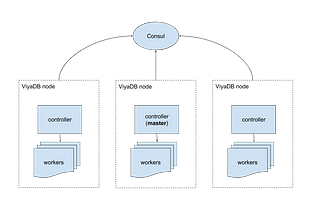
Michael SpectorinViyaDBSetting up ViyaDB cluster for real-time event processingPreviously, I wrote about an interesting use case on high volume of unordered events and on gathering analytical insights from them in…Dec 27, 2017Dec 27, 2017
Michael SpectorinViyaDBAdding SQL Interface to a non-relational databaseWhen it’s the right time for adding SQL interface to a database, which wasn’t designed as a relational database? Let’s take a step back…Nov 6, 2017Nov 6, 2017
Michael SpectorinViyaDBAnalyzing Mobile Users Activity with ViyaDBNot long ago, I worked on a very interesting and technologically challenging use case. Let’s say you have a stream of events, where each…Oct 19, 2017Oct 19, 2017
Michael SpectorThe Importance of Real DataImagine you’re bootstrapping a Big Data ecosystem for a new project, which still doesn’t have real clients. Even if you’re using your past…Sep 3, 2017Sep 3, 2017
Michael SpectorHow to Stay Relevant in Software Engineering Field?First of all, you have to feel the need for staying relevant. The world is changing every day: new technologies arise, new methods evolve…Aug 14, 2017Aug 14, 2017
Michael Spectorinsome-tldrs-ruСила метода “Двух случайных выборов”The Power of Two Random ChoicesJul 23, 2017Jul 23, 2017
Michael SpectorProfiling Spark Applications: The Easy WayRecently, I thought about some one-click way to profile Spark applications, so it could be easily integrated in any work environment…Jun 5, 2017Jun 5, 2017
Michael SpectorSchema-on-Read vs. Schema-on-WriteTL;DR — sometimes it worth to have them both.Mar 27, 2017Mar 27, 2017