Overview On Machine Learning Algorithms
Machine learning algorithms are the core of machine learning systems. These algorithms are designed to learn from data and make predictions or decisions without being explicitly programmed to perform the task. They use statistical methods to enable machines to improve their performance on tasks through experience.

In this blog we will learn overview of different types of ML algorithms and later on upcoming Blog we will dive deep into each topics . Machine learning algorithms can be broadly categorized based on the nature of the learning process and the type of data they handle. Here’s an overview of the primary categories:
Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- K-Nearest Neighbors (KNN)
- Gradient Boosting Machines (GBM)
- AdaBoost
- XGBoost
- LightGBM
- CatBoost
- Naive Bayes
- Neural Networks
- Ridge Regression
- Lasso Regression
Unsupervised Learning Algorithms
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Principal Component Analysis (PCA)
- Independent Component Analysis (ICA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Gaussian Mixture Models (GMM)
- Association Rule Learning (e.g., Apriori, Eclat)
Semi-Supervised Learning Algorithms
- Self-Training
- Co-Training
- Generative Adversarial Networks (GANs)
Reinforcement Learning Algorithms
- Q-Learning
- Deep Q-Networks (DQN)
- SARSA (State-Action-Reward-State-Action)
- Policy Gradient Methods
- Actor-Critic Methods
- Proximal Policy Optimization (PPO)
- Trust Region Policy Optimization (TRPO)
Ensemble Learning Algorithms
- Bagging
- Boosting
- Stacking
- Blending
Deep Learning Algorithms
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory Networks (LSTMs)
- Generative Adversarial Networks (GANs)
- Autoencoders
- Transformer Networks
Supervised Machine Learning Algorithms

1. Linear Regression
Mechanism: Linear regression is used for predicting a continuous dependent variable based on one or more independent variables. The relationship between the variables is modeled by fitting a linear equation to the observed data.
Applications:
- Predicting house prices
- Forecasting sales
- Risk management in finance
Advantages:
- Simple and easy to implement
- Interpretable coefficients
Disadvantages:
- Assumes a linear relationship between the variables
- Sensitive to outliers
2. Logistic Regression
Mechanism: Logistic regression is used for binary classification problems. It predicts the probability that a given input belongs to a certain class by applying a logistic function to a linear combination of input features.
Applications:
- Spam detection
- Disease diagnosis
- Customer churn prediction
Advantages:
- Outputs probabilities
- Works well with large datasets
Disadvantages:
- Assumes a linear relationship between the features and the log odds
- Not suitable for non-linear problems
3. Decision Trees
Mechanism: Decision trees split the data into subsets based on the value of input features. Each node represents a feature, each branch represents a decision rule, and each leaf represents an outcome.
Applications:
- Loan approval
- Customer segmentation
- Fraud detection
Advantages:
- Easy to visualize and interpret
- Handles both numerical and categorical data
Disadvantages:
- Prone to overfitting
- Sensitive to small changes in data
4. Random Forest
Mechanism: Random forest is an ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes for classification or mean prediction for regression.

Applications:
- Stock market analysis
- Medical diagnosis
- Recommendation systems
Advantages:
- Reduces overfitting compared to individual decision trees
- Robust to noise and outliers
Disadvantages:
- Computationally intensive
- Less interpretable than single decision trees
5. Support Vector Machines (SVM)
Mechanism: SVM finds the hyperplane that best separates the data into classes. It maximizes the margin between the closest points of the classes, known as support vectors.
Applications:
- Image classification
- Handwriting recognition
- Bioinformatics
Advantages:
- Effective in high-dimensional spaces
- Works well with clear margin of separation
Disadvantages:
- Not suitable for large datasets
- Difficult to interpret the model
6. K-Nearest Neighbors (KNN)
Mechanism: KNN classifies a data point based on the majority class among its K nearest neighbors in the feature space.
Applications:
- Recommender systems
- Anomaly detection
- Image recognition
Advantages:
- Simple and intuitive
- No training phase
Disadvantages:
- Computationally expensive at prediction time
- Sensitive to the choice of K and the distance metric
7. Gradient Boosting Machines (GBM)
Mechanism: GBM builds an ensemble of trees sequentially, where each tree corrects the errors of the previous ones. It optimizes a loss function by adding trees to the model.
Applications:
- Web search ranking
- Credit scoring
- Predictive maintenance
Advantages:
- High predictive accuracy
- Robust to overfitting
Disadvantages:
- Computationally intensive
- Requires careful tuning of parameters
8. AdaBoost
Mechanism: AdaBoost combines multiple weak classifiers to create a strong classifier. It adjusts the weights of incorrectly classified instances, focusing more on them in subsequent rounds.
Applications:
- Face detection
- Customer churn prediction
- Fraud detection
Advantages:
- Boosts the performance of weak learners
- Simple to implement
Disadvantages:
- Sensitive to noisy data and outliers
- Prone to overfitting with complex classifiers
9. XGBoost
Mechanism: XGBoost is an optimized implementation of gradient boosting designed for speed and performance. It uses a variety of enhancements such as regularization and parallel processing.
Applications:
- Competition-winning solutions
- Time series forecasting
- Click-through rate prediction
Advantages:
- High accuracy and performance
- Handles missing values well
Disadvantages:
- Requires careful tuning
- Can be complex to interpret
10. LightGBM
Mechanism: LightGBM is a gradient boosting framework that uses tree-based learning algorithms. It is designed to be distributed and efficient with large datasets.
Applications:
- Large-scale data applications
- Real-time prediction systems
- Natural language processing
Advantages:
- Fast training speed
- Lower memory usage
Disadvantages:
- Sensitive to overfitting
- Complex model structure
11. CatBoost
Mechanism: CatBoost is a gradient boosting algorithm that handles categorical features automatically and reduces the need for extensive preprocessing.
Applications:
- Recommendation systems
- Finance and insurance
- Marketing analytics
Advantages:
- Handles categorical data natively
- Reduces overfitting
Disadvantages:
- Requires careful parameter tuning
- Less interpretable
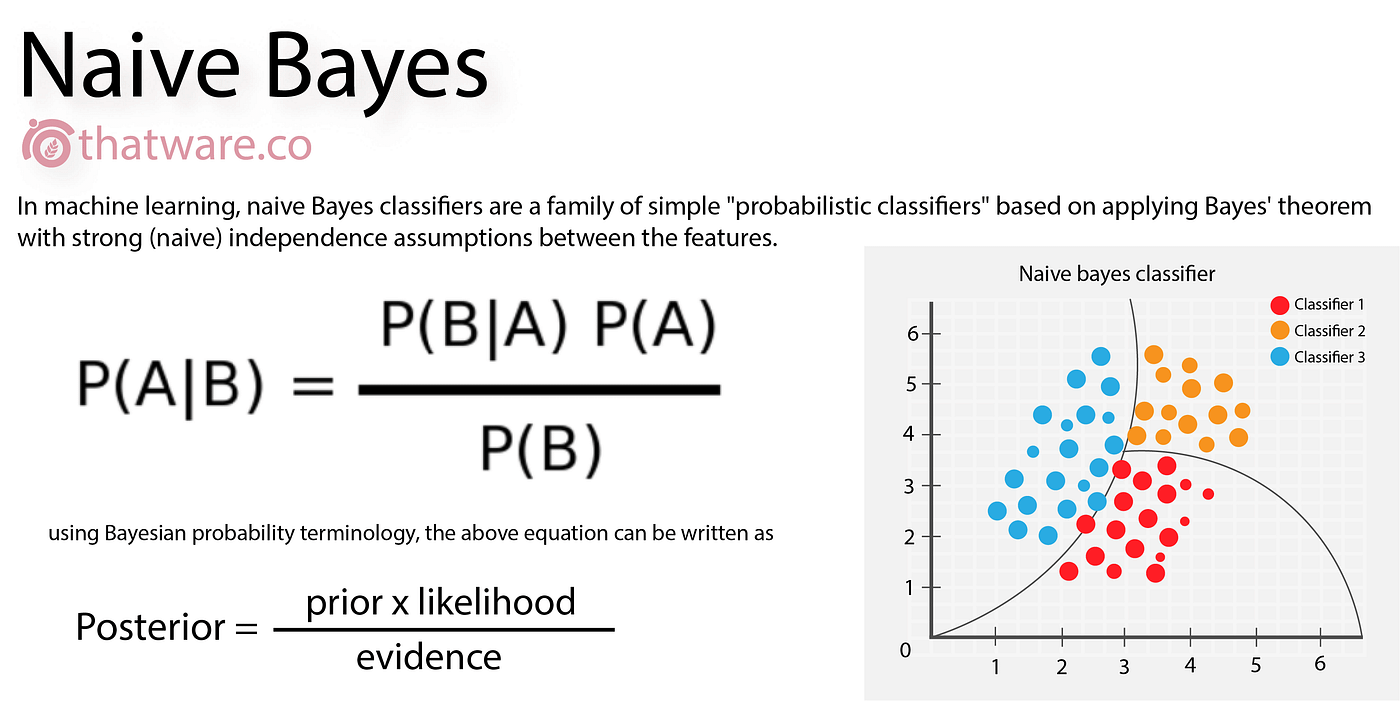
12. Naive Bayes
Mechanism: Naive Bayes is based on Bayes’ theorem and assumes independence between the features. It calculates the probability of each class and selects the one with the highest probability.

{kind=link}
Applications:
- Text classification
- Sentiment analysis
- Spam detection
Advantages:
- Simple and fast
- Works well with high-dimensional data
Disadvantages:
- Assumes feature independence
- May not perform well with correlated features
13. Neural Networks
Mechanism: Neural networks consist of interconnected layers of neurons that process input features and learn complex patterns. They are the foundation of deep learning.
Applications:
- Image and speech recognition
- Natural language processing
- Autonomous vehicles
Advantages:
- Can model complex relationships
- Scales well with large datasets
Disadvantages:
- Requires large amounts of data and computational power
- Hard to interpret
14. Ridge Regression
Mechanism: Ridge regression is a linear regression technique that includes a regularization term to prevent overfitting by penalizing large coefficients.
Applications:
- Multicollinearity problems
- Prediction models with many features
Advantages:
- Reduces overfitting
- Handles multicollinearity
Disadvantages:
- May not perform well if there is a lot of noise in the data
- Requires tuning of the regularization parameter
15. Lasso Regression
Mechanism: Lasso regression adds a penalty equal to the absolute value of the magnitude of coefficients, which can result in some coefficients being exactly zero, leading to sparse models.
Applications:
- Feature selection
- Predictive modeling
Advantages:
- Produces simpler and more interpretable models
- Can handle high-dimensional data
Disadvantages:
- Can be computationally intensive
- Sensitive to the choice of regularization parameter
Unsupervised Machine Learning Algorithms
Unsupervised learning is a class of machine learning techniques used to find patterns in data without predefined labels. These algorithms are crucial for tasks like clustering, dimensionality reduction, and association rule learning. This guide explores some of the most commonly used unsupervised learning algorithms, detailing their mechanisms, applications, advantages, and disadvantages.

1. K-Means Clustering
Mechanism: K-means clustering partitions data into K distinct clusters based on feature similarity. It assigns data points to the nearest cluster center, then updates the cluster centers iteratively.
Applications:
- Customer segmentation
- Image compression
- Market basket analysis
Advantages:
- Simple and easy to implement
- Scales well to large datasets
Disadvantages:
- Requires specifying the number of clusters in advance
- Sensitive to initial cluster centroids and outliers
2. Hierarchical Clustering
Mechanism: Hierarchical clustering creates a tree-like structure (dendrogram) to represent data. It can be agglomerative (bottom-up) or divisive (top-down). Agglomerative clustering starts with each data point as a single cluster and merges the closest pairs iteratively.
Applications:
- Gene expression data analysis
- Social network analysis
- Document clustering
Advantages:
- No need to specify the number of clusters
- Produces a dendrogram for detailed analysis
Disadvantages:
- Computationally intensive for large datasets
- Sensitive to noise and outliers
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Mechanism: DBSCAN groups data points that are closely packed together while marking points in low-density regions as outliers. It defines clusters based on the density of data points in a region.
Applications:
- Anomaly detection
- Geographic data analysis
- Image segmentation
Advantages:
- Can find arbitrarily shaped clusters
- Robust to outliers
Disadvantages:
- Requires tuning of parameters (epsilon and minPoints)
- Not suitable for datasets with varying densities
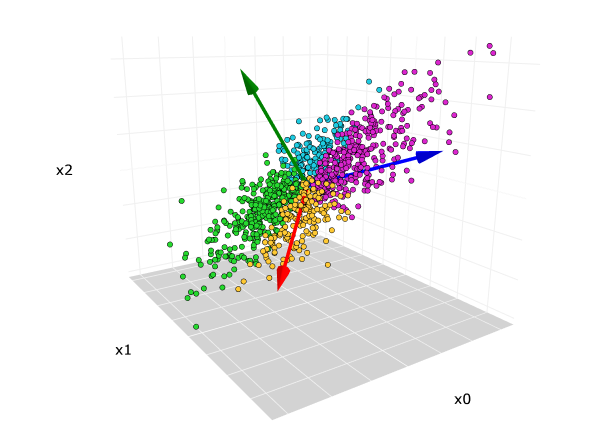
4. Principal Component Analysis (PCA)
Mechanism: PCA is a dimensionality reduction technique that transforms data into a new coordinate system. It finds the directions (principal components) that maximize the variance in the data.

{kind=link}
Applications:
- Data visualization
- Noise reduction
- Feature extraction
Advantages:
- Reduces dimensionality of data
- Captures most of the variance in the data
Disadvantages:
- Linear method, may not capture complex relationships
- Interpretation of principal components can be challenging
5. Independent Component Analysis (ICA)
Mechanism: ICA is a statistical technique for separating a multivariate signal into additive, independent components. It assumes that the observed data is a mixture of unknown, independent sources.
Applications:
- Blind source separation (e.g., separating audio signals)
- Feature extraction
- Medical signal processing
Advantages:
- Identifies underlying factors or sources
- Effective for non-Gaussian data
Disadvantages:
- Assumes independence of sources
- Sensitive to noise
6. t-Distributed Stochastic Neighbor Embedding (t-SNE)
Mechanism: t-SNE is a non-linear dimensionality reduction technique that visualizes high-dimensional data in a low-dimensional space (typically 2D or 3D). It preserves the local structure of the data.
Applications:
- Data visualization
- Understanding complex datasets
- Cluster analysis
Advantages:
- Effective for visualizing complex data structures
- Captures local relationships well
Disadvantages:
- Computationally expensive
- Difficult to interpret in higher dimensions
7. Gaussian Mixture Models (GMM)
Mechanism: GMM models the data as a mixture of several Gaussian distributions. Each component is defined by a mean and a covariance. It estimates the parameters using the Expectation-Maximization (EM) algorithm.
Applications:
- Image segmentation
- Anomaly detection
- Speech recognition
Advantages:
- Can model complex distributions
- Provides probabilistic cluster assignments
Disadvantages:
- Requires specifying the number of components
- Sensitive to initialization and convergence issues
8. Association Rule Learning (e.g., Apriori, Eclat)
Mechanism: Association rule learning discovers interesting relations between variables in large datasets. The Apriori algorithm generates frequent itemsets and derives association rules. Eclat (Equivalence Class Clustering and bottom-up Lattice Traversal) is another algorithm that uses a depth-first search strategy.
Applications:
- Market basket analysis
- Recommendation systems
- Inventory management
Advantages:
- Identifies hidden patterns in data
- Useful for market basket analysis
Disadvantages:
- Can produce a large number of rules, requiring post-processing
- Computationally expensive for large datasets
Semi-Supervised Learning Algorithms
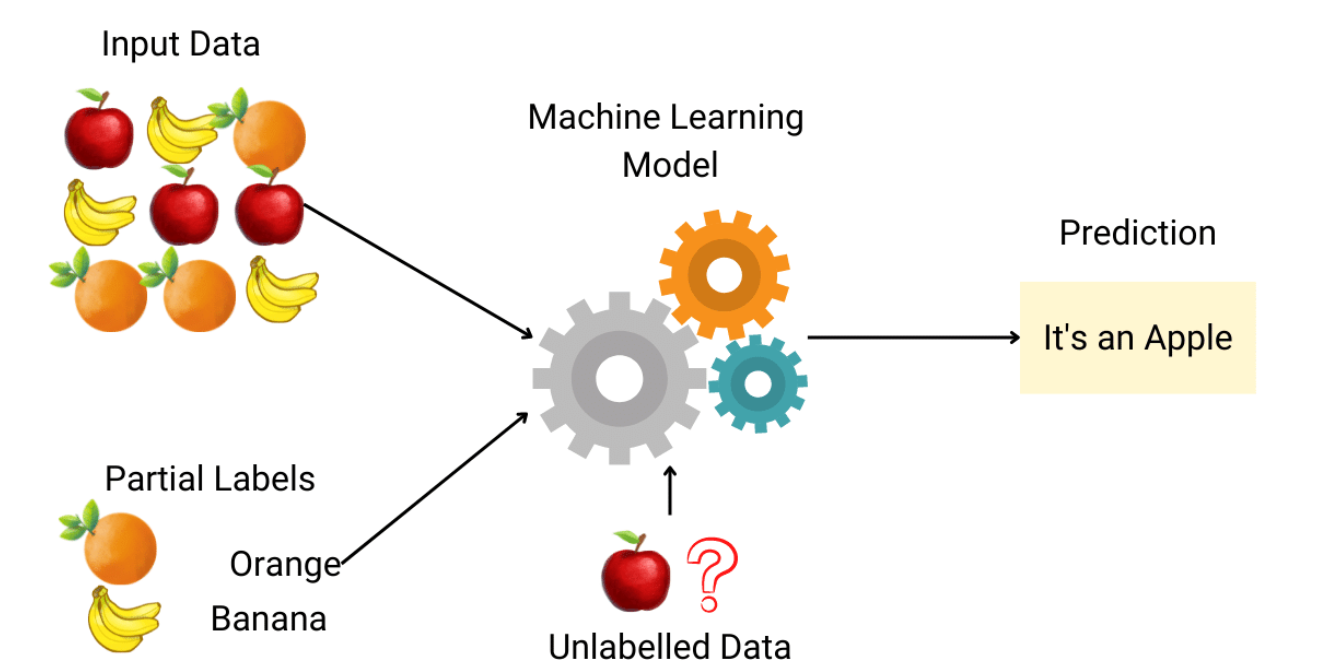
Semi-supervised learning lies between supervised and unsupervised learning. It leverages a small amount of labeled data along with a large amount of unlabeled data to improve learning accuracy. This guide explores some commonly used semi-supervised learning algorithms, detailing their mechanisms, applications, advantages, and disadvantages.

{kind=link}
1. Self-Training
Mechanism: Self-training is an iterative process where a supervised learning algorithm is first trained on a small labeled dataset. It then labels the unlabeled data, and the most confident predictions are added to the labeled dataset. This process is repeated until a stopping criterion is met.
Applications:
- Text classification
- Image recognition
- Speech recognition
Advantages:
- Simple to implement
- Utilizes both labeled and unlabeled data effectively
Disadvantages:
- Error accumulation: mislabeled data can degrade performance
- Requires a good initial model
Example Process:
- Train a classifier on a small labeled dataset.
- Use the classifier to predict labels for the unlabeled data.
- Select the most confident predictions and add them to the labeled dataset.
- Repeat the process until no more confident predictions are found or a predefined number of iterations is reached.
2. Co-Training
Mechanism: Co-training uses two different classifiers, each trained on a different view (subset of features) of the data. The classifiers label the unlabeled data, and the most confident predictions from each classifier are added to the labeled dataset of the other classifier. This process is repeated iteratively.
Applications:
- Web page classification
- Document categorization
- Multimodal data analysis
Advantages:
- Leverages different feature sets to improve learning
- Reduces the risk of error propagation compared to self-training
Disadvantages:
- Requires sufficient and redundant views of the data
- Complex to implement compared to self-training
Example Process:
- Train two classifiers on two different views of the labeled data.
- Each classifier predicts labels for the unlabeled data.
- The most confident predictions from each classifier are added to the labeled dataset of the other classifier.
- Repeat the process until a stopping criterion is met.
3. Generative Adversarial Networks (GANs)
Mechanism: GANs consist of two neural networks: a generator and a discriminator. The generator creates fake data, while the discriminator tries to distinguish between real and fake data. The two networks are trained together in a game-theoretic manner until the generator produces data indistinguishable from real data.
Applications:
- Image generation
- Data augmentation
- Semi-supervised learning with GANs (e.g., improving classification models)
Advantages:
- Can generate high-quality synthetic data
- Effective for data augmentation
Disadvantages:
- Training can be unstable and difficult to converge
- Requires substantial computational resources
Example Process:
- Train the discriminator to distinguish between real and generated data.
- Train the generator to create data that the discriminator cannot distinguish from real data.
- Use the trained generator to create synthetic labeled data.
- Combine real labeled data and synthetic data to train a semi-supervised learning model.
Reinforcement Learning Algorithms
Reinforcement Learning (RL) is a branch of machine learning where agents learn to make decisions by interacting with an environment. The goal is to maximize cumulative reward over time. This guide delves into some of the most commonly used reinforcement learning algorithms, exploring their mechanisms, applications, advantages, and disadvantages.

1. Q-Learning
Mechanism: Q-Learning is a value-based algorithm that learns the value of taking a certain action in a given state. It uses a Q-table to store Q-values, which represent the expected future rewards for state-action pairs. The algorithm updates the Q-values iteratively using the Bellman equation.
Applications:
- Game playing (e.g., chess, tic-tac-toe)
- Robot navigation
- Resource management
Advantages:
- Simple and easy to implement
- Works well in discrete action spaces
Disadvantages:
- Requires a large amount of memory for large state spaces
- Can be slow to converge
2. Deep Q-Networks (DQN)
Mechanism: DQN extends Q-Learning to handle high-dimensional state spaces using neural networks. A deep neural network approximates the Q-values instead of using a Q-table. DQN also uses techniques like experience replay and target networks to stabilize training.
Applications:
- Video game playing (e.g., Atari games)
- Autonomous driving
- Real-time strategy games
Advantages:
- Handles high-dimensional state spaces
- Achieves human-level performance in complex tasks
Disadvantages:
- Computationally intensive
- Requires careful tuning of hyperparameters
3. SARSA (State-Action-Reward-State-Action)
Mechanism: SARSA is an on-policy algorithm that updates Q-values based on the action actually taken by the agent. It follows the same update rule as Q-Learning but uses the Q-value of the action taken in the next state for updating.
Applications:
- Game playing
- Robotics
- Adaptive control
Advantages:
- More stable than Q-Learning in certain scenarios
- On-policy nature can be beneficial in some tasks
Disadvantages:
- May converge to suboptimal policies compared to Q-Learning
- Slower convergence
4. Policy Gradient Methods
Mechanism: Policy gradient methods directly optimize the policy by adjusting the parameters of a neural network. They use gradient ascent to maximize the expected cumulative reward. The most common approach is the REINFORCE algorithm.
Applications:
- Continuous control tasks (e.g., robotics)
- Game playing
- Financial trading
Advantages:
- Can handle continuous action spaces
- Directly optimizes the policy
Disadvantages:
- High variance in gradient estimates
- Requires careful tuning of learning rates
5. Actor-Critic Methods
Mechanism: Actor-critic methods combine the strengths of value-based and policy-based methods. The actor updates the policy directly, while the critic estimates the value function to provide feedback for the actor. Common algorithms include A2C (Advantage Actor-Critic) and A3C (Asynchronous Advantage Actor-Critic).
Applications:
- Game playing
- Robotics
- Autonomous navigation
Advantages:
- Reduced variance in policy gradient estimates
- Efficient and stable training
Disadvantages:
- More complex to implement than pure policy or value-based methods
- Requires careful balance between actor and critic updates
6. Proximal Policy Optimization (PPO)
Mechanism: PPO is a policy gradient method that improves stability and performance by limiting the policy update size. It uses a clipped objective function to prevent large updates that can destabilize training.
Applications:
- Robotics
- Game playing
- Industrial automation
Advantages:
- Stable and efficient training
- Simple to implement
Disadvantages:
- Requires tuning of clipping parameters
- Still computationally intensive
7. Trust Region Policy Optimization (TRPO)
Mechanism: TRPO is a policy gradient method that ensures stable updates by optimizing a surrogate objective function subject to a trust region constraint. This constraint limits the change in the policy to prevent large, destabilizing updates.
Applications:
- Robotics
- Game playing
- Control systems
Advantages:
- Guaranteed monotonic improvement in policy performance
- Stable and efficient training
Disadvantages:
- Computationally expensive
- Complex implementation
Ensemble Learning Algorithms
Ensemble learning is a powerful machine learning technique that combines multiple models to improve overall performance. This blog will cover four key ensemble learning algorithms: Bagging, Boosting, Stacking, and Blending. For each, we will discuss the mechanism, applications, advantages, and disadvantages.

1. Bagging (Bootstrap Aggregating)
Mechanism: Bagging involves training multiple models (usually of the same type) on different subsets of the training data. Each subset is created by randomly sampling the data with replacement (bootstrap sampling). The predictions of all models are then averaged (for regression) or voted on (for classification) to make the final prediction.
Applications
- Decision trees (e.g., Random Forest)
- Classification and regression tasks
- Reducing variance in high-variance models
Advantages
- Reduces overfitting by averaging multiple models.
- Simple to implement and parallelize.
- Improves stability and accuracy of models.
Disadvantages
- Can be computationally intensive due to training multiple models.
- Less effective on models with low variance (e.g., linear models).
2. Boosting
Mechanism: Boosting sequentially trains models, each focusing on correcting the errors of its predecessor. Initially, all data points are weighted equally. In each iteration, the weights of misclassified points are increased, so subsequent models focus more on those points. The final prediction is a weighted sum of the predictions from all models.
Applications
- Decision trees (e.g., AdaBoost, Gradient Boosting, XGBoost)
- Classification and regression tasks
- Improving performance on imbalanced datasets
Advantages
- Often achieves higher accuracy than bagging.
- Effective for reducing both bias and variance.
- Can handle a variety of weak learners.
Disadvantages
- More prone to overfitting if not properly regularized.
- Sequential nature makes it harder to parallelize.
- Can be sensitive to noisy data and outliers.
3. Stacking
Mechanism: Stacking involves training multiple base models (level-0) and then using their predictions as input features for a higher-level meta-model (level-1). The meta-model learns to combine the predictions of the base models to make the final prediction.
Applications
- Combining different types of models (e.g., decision trees, neural networks, linear models)
- Complex prediction tasks where a single model type may not suffice
- Competitions and challenges (e.g., Kaggle)
Advantages
- Can capture more complex patterns by leveraging diverse model types.
- Often leads to improved performance over individual models.
- Flexible and adaptable to various base models.
Disadvantages
- Can be difficult to tune and optimize.
- Requires careful validation to avoid overfitting.
- Computationally expensive due to training multiple models and a meta-model.
4. Blending
Mechanism: Blending is similar to stacking but simpler. It involves splitting the training data into two parts. Base models are trained on the first part, and their predictions on the second part are used to train a meta-model. The meta-model combines the predictions to make the final decision.
Applications
- Quick and simple ensemble methods
- Initial experiments to gauge ensemble potential
- Situations with limited computational resources
Advantages
- Easier to implement than stacking.
- Reduces risk of overfitting compared to stacking.
- Requires fewer data transformations and less computational power.
Disadvantages
- May not be as powerful as stacking in capturing complex patterns.
- Performance depends on the choice of data split.
- Limited by the smaller training set for the meta-model.
Deep Learning Algorithms
Deep learning has revolutionized the field of machine learning, providing state-of-the-art performance in various domains. In this blog, we will explore six fundamental deep learning algorithms: Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Long Short-Term Memory Networks (LSTMs), Generative Adversarial Networks (GANs), Autoencoders, and Transformer Networks. For each algorithm, we will discuss the mechanism, applications, advantages, and disadvantages.

1. Convolutional Neural Networks (CNNs)
Mechanism : CNNs are designed to process and analyze grid-like data, such as images. They use convolutional layers with filters to detect features in the input data. These filters slide over the input to create feature maps, which are then passed through activation functions and pooling layers to reduce dimensionality while preserving important information.
Applications
- Image classification (e.g., AlexNet, VGG, ResNet)
- Object detection (e.g., YOLO, Faster R-CNN)
- Image segmentation (e.g., U-Net, Mask R-CNN)
- Video analysis
Advantages
- Excellent at capturing spatial hierarchies in data.
- Reduced number of parameters compared to fully connected networks.
- High accuracy in image-related tasks.
Disadvantages
- Requires large amounts of labeled data for training.
- Computationally intensive, requiring powerful hardware.
- Less effective for non-visual data.
2. Recurrent Neural Networks (RNNs)
Mechanism : RNNs are designed for sequential data, where the output depends on previous elements in the sequence. They have internal memory (hidden states) that captures information about previous inputs, allowing them to maintain temporal dependencies. The same weights are used at each time step, making them suitable for variable-length sequences.
Applications
- Time series forecasting
- Natural language processing (NLP)
- Speech recognition
- Text generation
Advantages
- Can handle sequences of varying lengths.
- Maintains temporal dependencies in data.
- Suitable for tasks where context is important.
Disadvantages
- Prone to vanishing and exploding gradient problems.
- Difficult to train for long sequences due to memory limitations.
- Slower training compared to feedforward networks.
3. Long Short-Term Memory Networks (LSTMs)
Mechanism: LSTMs are a type of RNN designed to address the limitations of standard RNNs, particularly the vanishing gradient problem. They use a gating mechanism (input, forget, and output gates) to control the flow of information and maintain long-term dependencies. This allows them to remember important information over extended sequences.
Applications
- Language modeling
- Machine translation
- Speech synthesis
- Anomaly detection in time series data
Advantages
- Better at capturing long-term dependencies than standard RNNs.
- Effective in handling vanishing gradient issues.
- Robust performance in various sequence-based tasks.
Disadvantages
- Computationally expensive due to complex gating mechanisms.
- Requires careful tuning of hyperparameters.
- Slower training compared to simpler models.
4. Generative Adversarial Networks (GANs)
Mechanism: GANs consist of two neural networks: a generator and a discriminator. The generator creates synthetic data, while the discriminator evaluates whether the data is real or generated. The two networks are trained simultaneously in a game-theoretic framework, where the generator aims to fool the discriminator, and the discriminator aims to correctly identify real and fake data.
Applications
- Image generation (e.g., deepfake technology)
- Data augmentation
- Image-to-image translation (e.g., pix2pix, CycleGAN)
- Text-to-image synthesis
Advantages
- Capable of generating high-quality synthetic data.
- Encourages creativity in generating new data points.
- Useful for tasks with limited labeled data.
Disadvantages
- Difficult to train due to unstable dynamics between generator and discriminator.
- Prone to mode collapse, where the generator produces limited varieties of outputs.
- Requires extensive computational resources.
5. Autoencoders
Mechanism : Autoencoders consist of an encoder and a decoder. The encoder compresses the input data into a lower-dimensional latent space, while the decoder reconstructs the data from this compressed representation. They are trained to minimize the difference between the input and the reconstructed output.
Applications
- Dimensionality reduction
- Anomaly detection
- Image denoising
- Feature learning
Advantages
- Effective for unsupervised learning tasks.
- Can discover meaningful features in data.
- Useful for data compression and noise reduction.
Disadvantages
- Reconstructed outputs may be blurry or lack detail.
- Sensitive to the choice of architecture and hyperparameters.
- May struggle with capturing complex relationships in data.
6. Transformer Networks
Mechanism : Transformer networks use self-attention mechanisms to process sequences in parallel, rather than sequentially like RNNs. This allows them to capture long-range dependencies and contextual relationships more effectively. The architecture consists of encoder and decoder layers, each with multi-head attention and feedforward sub-layers.
Applications
- Machine translation (e.g., BERT, GPT)
- Text summarization
- Question answering
- Natural language understanding
Advantages
- Highly effective in capturing long-range dependencies.
- Parallel processing leads to faster training and inference.
- Achieves state-of-the-art performance in various NLP tasks.
Disadvantages
- Requires large amounts of training data and computational resources.
- Sensitive to the choice of hyperparameters.
- Can be challenging to interpret and debug.
Comparison of Machine Learning Algorithms
Supervised Learning Algorithms Key Differences
- Requires labeled data for training.
- Direct feedback from the labeled data improves model accuracy.
Unsupervised Learning Algorithms Key Differences
- Works with unlabeled data.
- Focuses on discovering hidden patterns or structures in the data.
Semi-Supervised Learning Algorithms Key Differences
- Utilizes both labeled and unlabeled data.
- Bridges the gap between supervised and unsupervised learning by leveraging a small amount of labeled data.
Reinforcement Learning Algorithms Key Differences
- Focuses on learning from interactions with an environment.
- Uses rewards and penalties to guide learning.
Ensemble Learning Algorithms Key Differences
- Combines multiple models to enhance performance.
- Helps in reducing variance and bias, leading to more robust predictions.
Deep Learning Algorithms Key Differences
- Employs multi-layered neural networks.
- Requires large datasets and computational resources.
- Capable of learning high-level abstractions and complex patterns.
Conclusion
Machine learning algorithms are diverse, each suited for different types of tasks and data structures. Understanding the categories and specific algorithms within each category helps practitioners select the most appropriate methods for their particular use cases. The ultimate goal is to develop models that can generalize well to new data and perform accurately in real-world applications.
Get in touch
As I believe “If you want to go fast, go alone. If you want to go far, go with others.” let’s connect and grow together . Don’t hesitate to ask your question, if you have one.
Linkedin: https://www.linkedin.com/in/suraj-agrahari-1622aa18a/
Instagram : https://www.instagram.com/surraj_._agrahari/
Facebook : https://www.facebook.com/suraj.agrahari.01/
Gmail : surajagrahari330@gmail.com
Happy learning !!