Building a Recommendation Engine Using Neo4j Hands-On — Part 1
From Data Model to Loading Data to Making Recommendations
A recommendation system plays a critical role in solving one of the most complex problems we face when we want to decide and that is a dilemma.

What food item do I order? Which movie should I watch? Which shirt should I buy? Recommendations help us explore products. In this article, we will:
- Explore collaborative and content-based filtering.
- Build up an intuition regarding on what basis a recommendation is to be made and how it is to be made.
- Design the appropriate data model incrementally.
In part 2 of this hands-on series, we will be implementing the same, starting with loading existing data from CSV, tracking new orders, and then making recommendations — all using Cypher query language. We will also discuss the deployment of the Neo4j database and serve our recommendations.
Two Types of Recommendation Systems
As you may already know, recommendation engines generally fall into two types: Collaborative Filtering and Content-Based Filtering. These two are the extremes and your solution will most likely be a hybrid approach. Let’s discuss them in short.
Collaborative Filtering
“Collaboration” can’t take place if there is only a single person working on a task (excluding human-robot collaboration). Similarly, in collaborative filtering, when users collaborate on a single entity, i.e., order the same item(s), watch the same movie(s), etc. You can consider them similar based on the fact that they are interested in the same things and have some similar interests. Based on this, you can recommend something to a user who is liked by other users who also like other things liked by the concerned user.

Simplifying with a simple example (in reality, you would weigh by the number of common interests), if User Ishan likes both Item A and Item B, and User Shalaka likes Item A, then there is a possibility that Shalaka may also like Item B.
Content-Based Filtering
Content-based filtering is all about making recommendations based on the fact that people have specific likings. People generally prefer to eat food belonging to specific cuisine(s) or like to watch movies of a specific genre(s).
In simple words, if a user has liked a comedy movie, then there is a possibility that the user will like another movie that also belongs to the comedy genre.

Say Tanay likes Item A, which belongs to Category S, then he may also like Item B, which also belongs to Category S.
Enough concepts about recommendation systems. Let’s get into some hands-on.
Problem Statement
There is a popular restaurant named “NeoRestro,” which wants to recommend items from the menu to its users when they order online. The task is to build a recommendation engine using the Neo4j database.
Data Model
Before designing the data model, we should list out the questions we want to answer. Our data model should be robust enough to answer the current questions, as well as questions that may arise in the future, with little to no modifications. We won’t be storing all the data in Neo4j, as in a real product, multiple databases should be used, one of which would be Neo4j for powering recommendations.
Questions
- What does a user generally order most frequently?
- Once a particular item (denoted as X) has been added to the cart, which other items have been previously ordered by the user with item X?
- Once a particular item (denoted as X) has been added to the cart, which items are frequently ordered along with X amongst all the users?
Keeping the above questions in mind, let’s design our data model incrementally. In case you are not familiar with Property Graph Model or want to refresh your knowledge, here is a super short explanation.
Property Graph Model

Individual records are represented as nodes with attached labels. Think of labels as similar to table names such as User or Menu Item. However, a node can have multiple labels. Information about the record is stored in key-value pairs in the form of properties. Relationships among nodes are represented by “Relationships” :) Relationships can be of different user-defined types and can also have associated information with the help of properties. Relationships can be classified as either being directed or undirected. Though while adding data in Neo4j, it is mandatory to specify a direction while querying the graph, you can traverse it both ways if you want.
Let’s tackle the questions one by one and design the data model.
Tackling Question 1
What does a user generally order most frequently ?

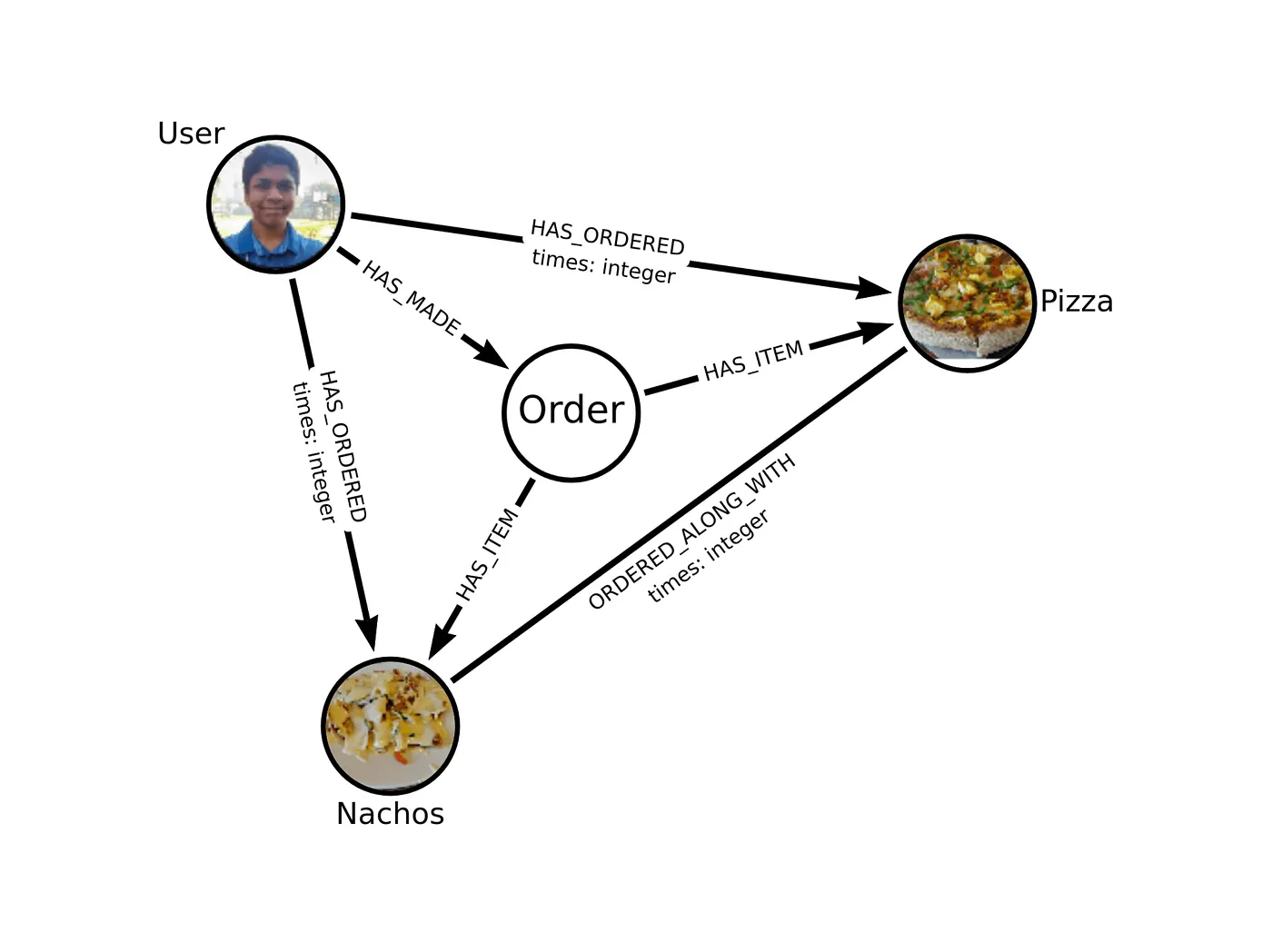
It can’t be simpler than this, it is what it looks like, which is the beauty of the property graph model. Here we have a User identified by a property named db_id with an integer as the data type of the value. Though Neo4j has node IDs for its internal usage, since it’s for internal use and we would have more information associated with this user, it’s best to keep a separate id and not use the node id. We also have an Item that represents a menu item identified by the db_id property.
There is a simple relationship of HAS_ORDERED signifying that the user has ordered that item. Notice that we haven’t used “ORDERED” but we used “HAS_ORDERED.” We prefixed the action with “HAS” to signify that there can be multiple items that can be ordered by a user. We also keep track of the count as to how many times that particular item has been ordered by that user till now via the times property.
Using this, we can find what all the user has ordered till now, along with how many times each item has been ordered. We can use this to recommend the most frequently ordered items to the user based on his / her order history, as shown below.

Here the most frequent item ordered by user Vaishnavi is pizza. So whenever she opens the website/app, we can recommend her pizza along with nachos (in a carousel ?). Anyways, getting back to data modeling, let’s answer the second question.
Tackling Question 2
Once a particular item (denoted as X) has been added into the cart, which other items have been previously ordered by the user with item X ?

In order to keep track of items ordered together, we add the concept of an Order in our data model. Whenever a user checkouts, we create an order and link the items in that order. Since an order can contain multiple items, we name the relationship as HAS_ITEM. The below-shown example illustrates how this will work out.

Say we have a user named Clint who has till now made two orders. In one of the orders, he bought pizza and nachos. And in the second one, he only ordered pasta. Now say tomorrow he adds pizza to his cart. Hopping through his orders, we can find out which item(s) had he previously also ordered when he had ordered pizza. As per the above example, we would recommend Nachos to him.
Tackling Question 3
Once a particular item (denoted as X) has been added into the cart, which items are frequently ordered along with X amongst all the users ?

Though we can answer this question by hopping over all the orders in which item X is present and, from there, counting the number of times each menu item is encountered upon each request, it’s much better to explicitly define the implicit “ordered along with” notation and use that for answering the question. Hence we add an ORDERED_ALONG_WITH relationship from an item to an item which appears as a kind of a self joins (pointing to itself) in our data model. Also, unlike “User HAS_MADE Order” in the case of “Pizza ORDERED_ALONG_WITH Nachos” since the order of source and destination doesn’t matter, we use an undirected relationship instead of a directed one.
We also keep track of how many times the concerned pair of items have been ordered together via the times property. The below-shown example illustrates how this will work out.

Say we have a user named Ajinkya who has, till now, made two orders. In one of them, he ordered Nachos, Pasta, and Pizza. In the second one, he ordered Nachos and Pizza, but he did not order Pasta. As you can see, Nachos and Pizza appear together among all orders twice, while all other pairs appear once. Now say tomorrow when Vaishnavi adds Pizza to her cart, along with the recommendation based on her order history, utilizing pair-wise occurrences based on all orders placed by all users till now, we will recommend Nachos to her.
Summing It Up
- When a user opens the app/website, we will recommend his / her most frequently ordered item.
- When a particular item is added to the cart, we will use both the user’s order history as well as information as to which other items have co-occurred in the past for all the users to rank the items to be recommended.
Conclusion
That’s it for now, folks. If you enjoyed reading this post and learned something, do give a clap. It helps Medium’s recommendation system to recommend such blogs to other users who might benefit from them. You can find part 2 here.
Credits
- Oven Fresh located at Dadar, Mumbai, India for making Pizza, Penne Pasta and Nachos and presenting them beautifully (The pictures are captured by me)
- arrows.app for their awesome graph drawing tool
