🚀pgvector-remote : A pgvector fork with the performance of Pinecone
TLDR: By leveraging the combined strengths of pgvector and Pinecone, pgvector-remote is setting a new standard for vector similarity search, marrying convenience with cutting-edge performance. ✨
When handling high-dimensional data — crucial for recommendation engines, image search, and natural language processing — vector similarity search is indispensable. Vector databases help perform similarity searches efficiently.
There are traditionally two approaches to creating a Vector Store:
- Extend a relational database (e.g., pgvector) 🛠️
- Build a native Vector Database (e.g., Pinecone) 🌲

Let’s dive into these options and dissect their strengths and weaknesses.
Pinecone: Pinecone is a fully managed cloud Vector Database that is purpose-built for vector data — everything from its architecture to vector indexing algorithms to functionality was designed and built specifically for working with vector embeddings. As a result, it delivers superior performance and cost-efficiency at scale, which are challenging to achieve with add-on solutions.
pgvector: pgvector is a PostgreSQL extension that allows you to store, query, and index vectors. Postgres does not support native vector capabilities yet (as of PG16) and pgvector is designed to fill this gap.
This approach enables you to store vector data together with other data in Postgres and perform vector similarity search, all while leveraging Postgres’s full range of features.
Trade-Offs: 🤔
While both the options seem like great choices at first glance, the devil lies in the details.

Vector indexes are memory-intensive, often requiring dedicated servers, which is not feasible when integrated into a standard database server. Furthermore, while the development team behind pgvector is amazing, it is still a bit challenging to keep pace with the dedicated research teams behind Pinecone, Weaviate, etc. pgvector currently lacks some critical features like metadata-filtering that makes Pinecone more useful for AI applications. Also, pgvector typically has higher latency and lower throughput compared to Pinecone.


While pgvector lacks the performance and cost benefits of dedicated vector stores like Pinecone, the primary bottleneck with closed-source solutions like Pinecone is network latency, not the search operation itself. Moreover, Pinecone’s simplistic design is deceptive due to several hidden complexities, particularly in integrating with existing data storage solutions. For example, its restrictive metadata storage capacity makes it troublesome to manage data-intensive workloads. The approach also has the severe disadvantage of lacking data synchronization with the primary data source. This article goes into more detail on why Pinecone’s performance benefits are insufficient to warrant a dedicated vector database.
We would ideally like to have a solution that can provide the benefits of both worlds — be convenient to integrate while providing a performant similarity search solution. However, the two paradigms for vector indexing described above prevent such a solution from existing ……. or do they?
A Novel Paradigm: Remote Indexing with pgvector-remote 🔄
pgvector-remote is an extension which seamlessly integrates remote vector stores(Pinecone) into pgvector. Using pgvector-remote, you can use a remote (Pinecone) index just like you would use ivfflat or hnsw. This extension is being developed by the Georgia Tech Database Group.

pgvector-remote lets you keep your metadata in postgres and your embeddings in pinecone. This makes pgvector-remote elegant and convenient to use by hiding the complexity of maintaining and synchronizing vector stores from the user; and presenting a unified sql interface for creating, querying, and updating pinecone indexes.
With the motivation to think of vector stores as indexes not Databases.
pgvector-remote combines the elegance and convenience of pg vector with the power and performance of pinecone by exposing pinecone as just another index type. This provides 100x faster latencies under certain workloads, while keeping pgvector’s ease of use
-- AS EASY AS
CREATE INDEX ON items USING PINECONE (embedding);
Best of Both Worlds

pgvector-remote not only maintains the ease of a standard SQL interface but also upholds essential database integrity features, such as ACID compliance and robust transaction management. Its compatibility with more than ten client-side programming languages and ability to integrate with remote vector stores expands its versatility, providing a scalable solution for environments demanding high throughput and optimized latency.
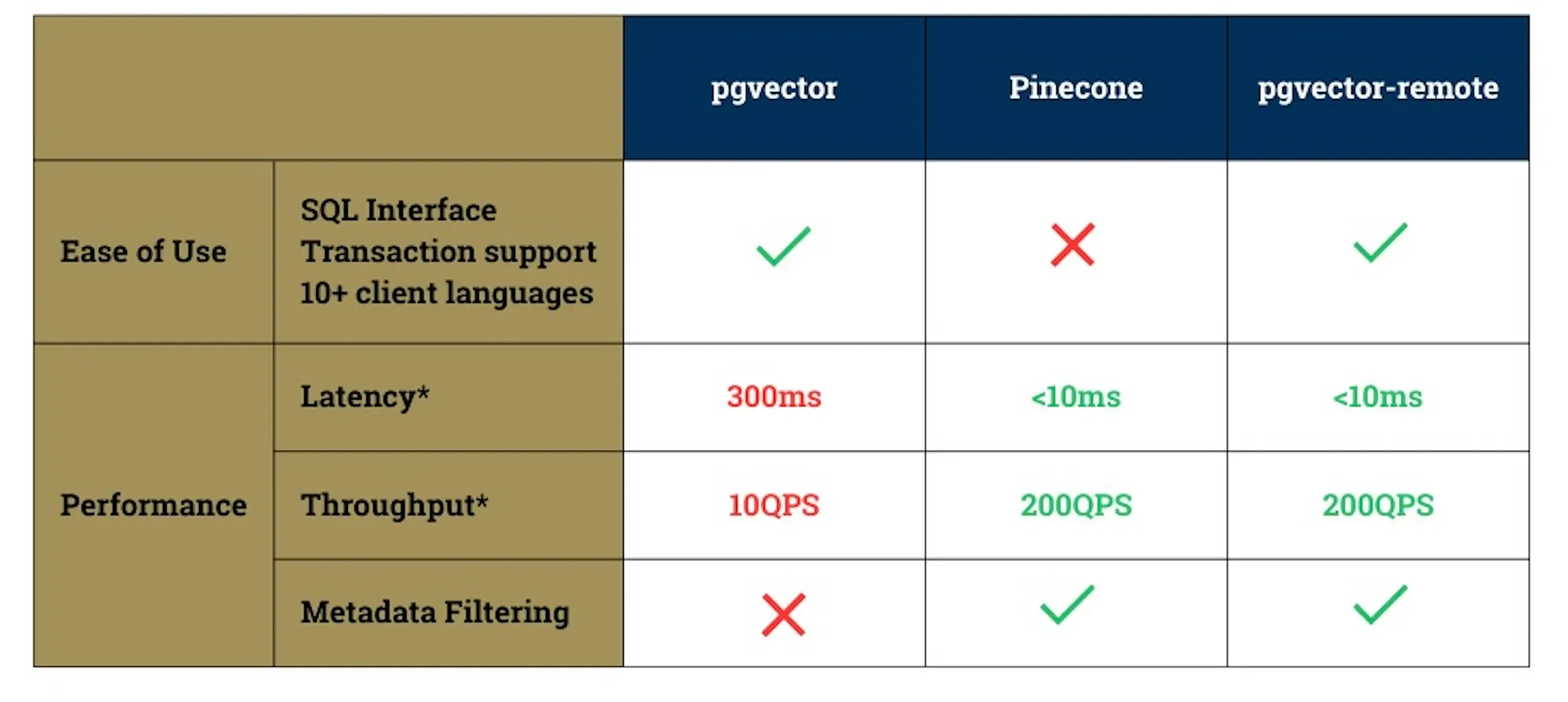
Conclusion: Vector databases like Pinecone aren’t designed to handle documents directly — they’re not meant to be document databases. So your document and its embedding need separate database systems. If you’re looking to perform vector search on an existing, single-source database, while maintaining a scalable and performant similarity search infrastructure, consider utilizing pgvector-remote in your application. Get the combined benefits of faster vector search along with an easy-to-use and familiar interface.
Stay tuned as we expand support to more native vector stores, including Milvus.
