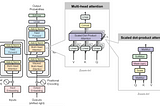
Tejaswi kashyapUnpacking Attention in Transformers: From Self-Attention to Causal Self-AttentionThis article will guide you through self-attention mechanisms, a core component in transformer architectures, and large language models…Sep 8Sep 8
Tejaswi kashyapMemory Optimization in LLMs: Leveraging KV Cache Quantization for Efficient InferenceQuantization shrinks the footprint of a large language model (LLM) by reducing the precision of its parameters, such as from 16-bit to…Jul 51Jul 51
Tejaswi kashyapTailoring Llama 3: Harnessing Fine-Tuning for Custom Language TasksLow-rank adaptation (LoRA) enables the straightforward adaptation of pre-trained large language models (LLMs) to new tasks by freezing the…Jun 41Jun 41
Tejaswi kashyapAccelerating AI: Exploring Speculative Decoding with Large Language ModelsIntroductionApr 271Apr 271
Tejaswi kashyapDeciphering Mixtral-8x7B: Navigating the Sparse Expert Model Ensemble by Mistral AIHow to Surpass the Capabilities of GPT-3.5 and Llama 2 70B with Personal Computing PowerMar 111Mar 111
Tejaswi kashyapinGoPenAILangChain and the Evolution of LLM: Why Memory MattersImage from Google Sep 5, 20231Sep 5, 20231
Tejaswi kashyapUnderstanding Large Language Models: Architecture and Self-Attention ExplainedLarge language models have revolutionized natural language processing, enabling computers to understand and generate human-like text. Based…Jul 30, 2023Jul 30, 2023
Tejaswi kashyapShot predictor using polynomial regressionThis project will use polynomial regressions to predict the shot.Mar 27, 2023Mar 27, 2023
Tejaswi kashyapParking space counterThis project is based on image processing to detect spaces in a parking lot.Mar 9, 2023Mar 9, 2023