RAG for Vision: Building Multimodal Computer Vision Systems
We explore what Visual RAG is, why it matters, and how it’s supercharging a Computer Vision Pipeline 2.0.

This article explores the exciting world of Visual RAG, exploring its significance and how it’s revolutionizing traditional computer vision pipelines.
From understanding the basics of RAG to its specific applications in visual tasks and surveillance, we’ll examine how this technology is paving the way for more advanced and efficient AI systems.
🔥 Learn more about Segment Anything Model 2 (SAM 2):
- 🆕 SAM 2 + GPT-4o — Cascading Foundation Models via Visual Prompting — Part 1
Table of Contents
- What is Retrieval Augmented Generation (RAG)?
- Visual RAG: How is RAG used in Computer Vision
- Multimodal RAG
- What’s next
1. What is Retrieval Augmented Generation (RAG)?
1.1 Before we start: what is (visual) prompting?
To better understand Retrieval-Augmented Generation (RAG) [1], it’s useful to first define “prompting”.
RAG combines the principles of prompting with information retrieval. [2]
Prompting is a technique to guide foundation models, such as Multimodal Large Language Models (MLLMs), to perform tasks by providing specific instructions or queries.
In the vision domain, Visual Prompting [3] uses visual inputs (such as images, lines or points) to instruct large-scale vision models to perform specific tasks, often including tasks the model wasn’t explicitly trained on.
Figure 1 shows how promptable models can be used as building blocks to create larger systems, where the 🔑 key insight is that models can be connected (or chained together) via visual prompting: YOLO-World outputs can be used as visual prompts for SegmentAnything.

So, it turns out that prompting provides the foundation on which more advanced techniques like RAG are built.
1.2 What is RAG?
When you prompt a GenAI model, such as GPT-4 or LLaVA [5], the answer you obtain comes from a (zero-shot) model [4] that is limited by its information cutoff (or by its own training data, both in quantity and quality). As a result, the model’s knowledge is static and not updated beyond a certain point.
Retrieval-Augmented Generation (RAG) enables a system to retrieve relevant context that is then combined with the original prompt. This augmented prompt is used to query the model, providing data that would otherwise be unavailable to it.
1.3 Understanding how RAG works
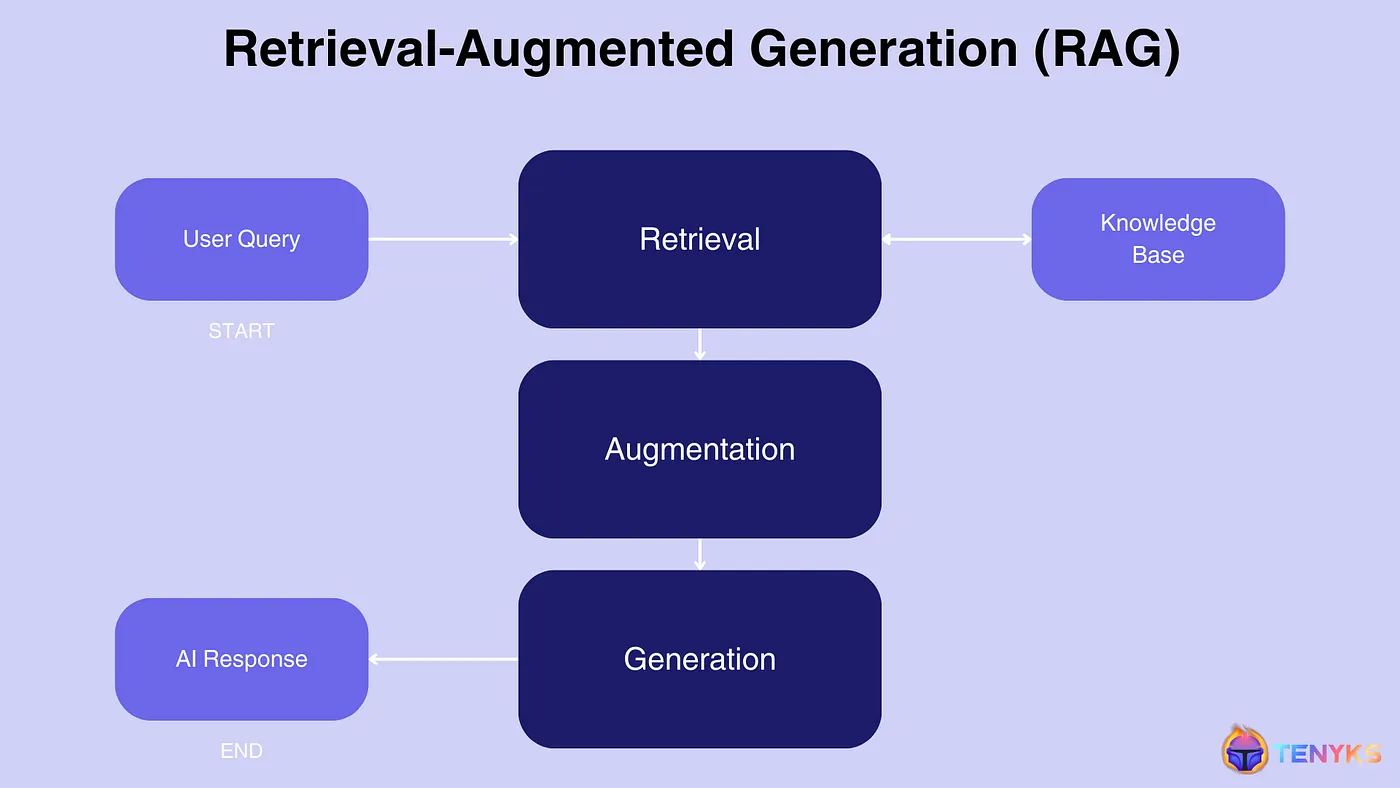
Now, let’s look at Figure 2 to break down a typical RAG workflow:
- Retrieval: When given a query or prompt, the system first retrieves relevant information from a knowledge base or external data source.
- Augmentation: The retrieved information is then used to augment or enhance the input to the model.
- Generation: Finally, the model generates a response based on both the original query and the retrieved information.
2. How is RAG used in Computer Vision
2.1 Traditional (text) RAG vs Visual RAG
As illustrated in Figure 3, Visual RAG adapts the concept of Retrieval-Augmented Generation (RAG) to vision tasks.
While traditional RAG processes text inputs and retrieves relevant textual information, Visual RAG works with images, sometimes accompanied by text, and retrieves visual data or image-text pairs.
The encoding process shifts from text encoders to vision encoders (sometimes foundation models such as CLIP [6] are used for this purpose), and the knowledge base (i.e., a vector database) becomes a repository of visual information rather than text documents.
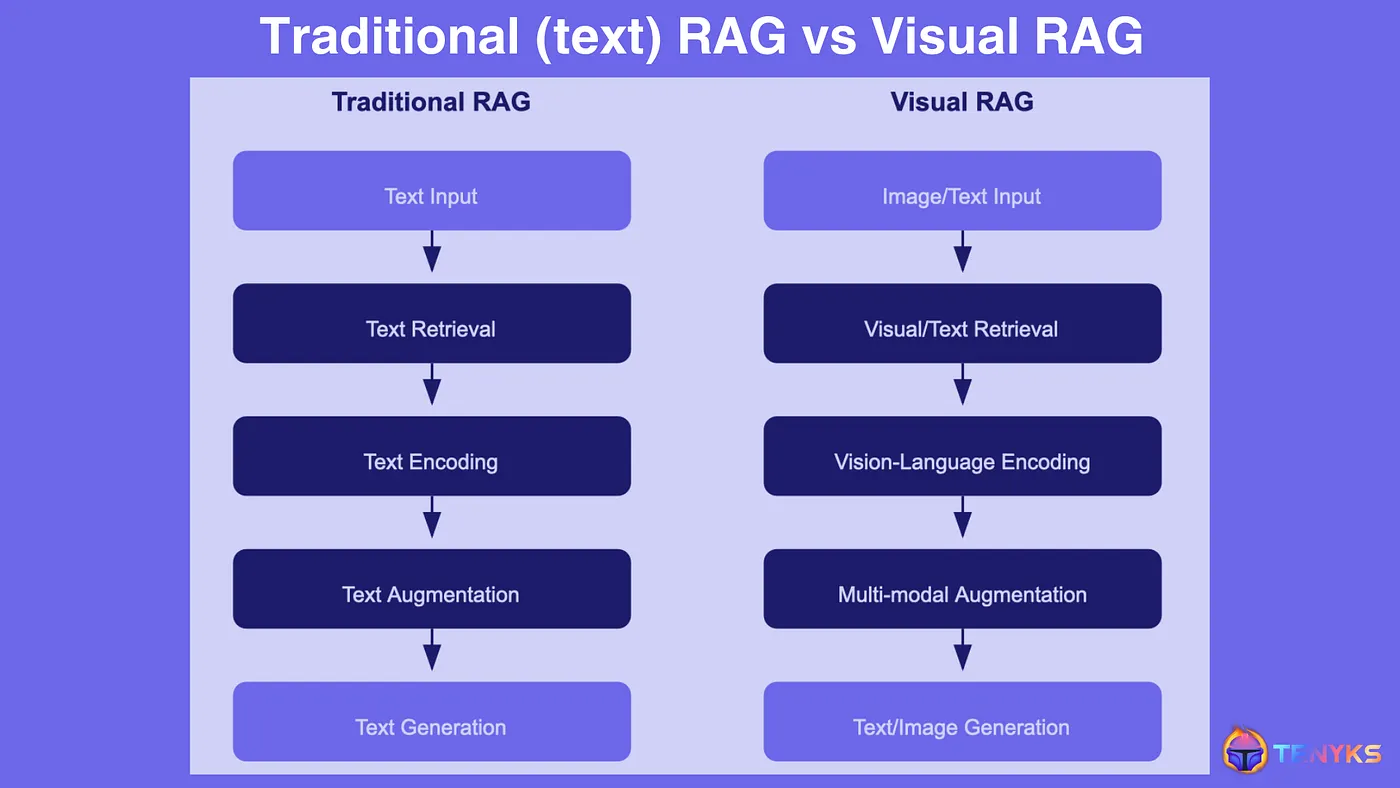
Finally, Visual RAG’s augmentation combines retrieved visual data with the input, enabling it to generate diverse outputs including text descriptions, modified images, or multimodal content.
Visual RAG is particularly powerful 💪 for tasks that require combining visual understanding with external knowledge. For example, it could help a vision system identify rare objects by retrieving relevant visual and textual information of these edge case from its knowledge base.
2.2 Visual RAG or Fine-tuning

A common question when building a vision system in production is to decide between RAG and fine-tune [7]. As shown in Figure 4, the answer is not binary, instead it depends on many factors such as:
- Budget: fine-tuning involves retraining the model, which is more expensive.
- Inference: RAG requires more compute during inference.
- Time: since the weights are updated, fine-tuning requires more time commitment in the beginning but might be less time intensive in the long run.
💡 As a rule of thumb, RAG is an ideal strategy to start with. After that, if the task for the model becomes too narrow or specific, fine-tuning might be the next step.
So, why not both? 🤔
For some use-cases, the two approaches can be combined:
- Evolving domains with core tasks: For instance, in medical imaging where there are standard diagnostic procedures (handled by fine-tuning) but also rapidly evolving research and new case studies (addressed by Visual RAG).
- E-commerce and product recognition: A fine-tuned model could recognize product categories, while Visual RAG could retrieve up-to-date product information or similar items from a dynamic inventory.
- Content moderation systems: Fine-tuning can handle common violation types, while Visual RAG can adapt to emerging trends or context-dependent violations.
3. Multimodal RAG
3.1 Multimodal Visual RAG for Video Understanding
Let’s explore a specific implementation of a multimodal Visual RAG pipeline for video understanding (shown in Figure 5). This example demonstrates how these technologies can work together to extract meaningful insights from video data.
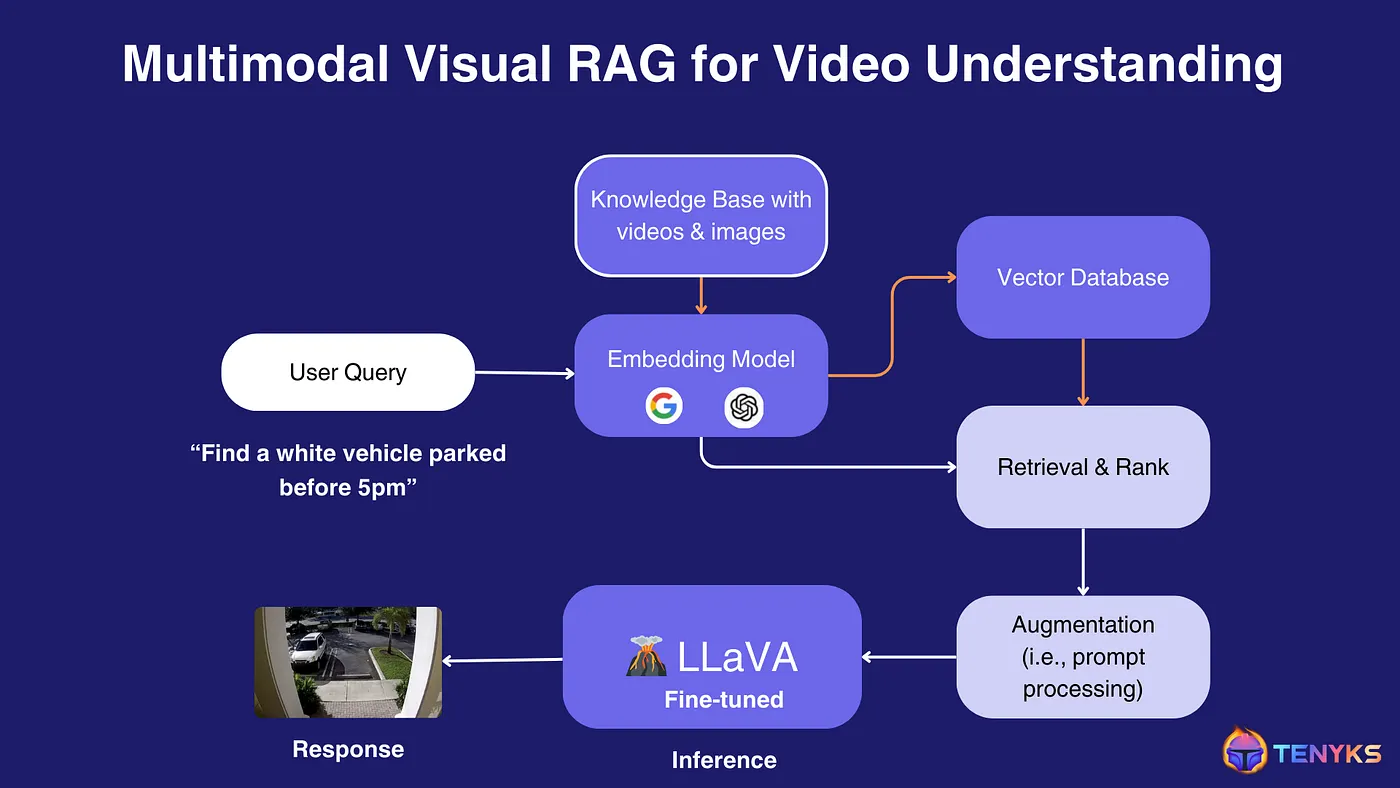
Let’s break down the system components and their interactions:
- 1. Knowledge Base: The system starts with a knowledge base containing videos and images. This serves as the foundation for understanding visual content.
- 2. Embedding Model: An embedding model, such as CLIP (Contrastive Language-Image Pre-training), is used to convert both the knowledge base content and user queries into a common vector space. This allows for comparison between different modalities (text and visual data).
- 3. Vector Database: The embedded representations of the knowledge base are stored in a vector database, enabling efficient similarity searches.
- 4. User Query: A user inputs a query, such as “Find a white vehicle parked before 5pm”.
- 5. Query Processing: The user’s query is passed through the embedding model to convert it into the same vector space as the knowledge base content.
- 6. Retrieval & Rank: The system retrieves relevant information from the vector database based on the similarity between the query embedding and the stored embeddings. It then ranks the results to find the most pertinent matches.
- 7. Augmentation: The retrieved information undergoes prompt processing or augmentation to refine the context and prepare it for the language vision model.
- 8. LLaVA Fine-tuned: A fine-tuned version of LLaVA (Large Language and Vision Assistant) processes the augmented information. LLaVA is a multimodal model capable of understanding both text and visual inputs.
- 9. Inference: The LLaVA model performs inference on the processed data to generate a response that addresses the user’s query.
- 10. Response: The final output is a visual response — in this case, an image showing a white car parked on a street, which matches the user’s query.
The system shown in Figure 5 is an example of how foundation models in computer vision can be connected or chained together.
At Tenyks, we believe that a paradigm shift is about to occur in the field of Vision, giving rise to a Computer Vision Pipeline 2.0, where some traditional stages (e.g., labelling) are replaced by promptable foundation models.
4. What’s next
4.1 Visual RAG in production
While the system in section 3.1 presents an impressive framework for video understanding, in practice the figure above describes a prototype.
For a production grade system, some considerations should be addressed for successful deployment:
- Scalability: The system must be able to handle large volumes of video data and concurrent user queries efficiently.
- Error handling and edge cases: The pipeline should gracefully manage scenarios where visual content is ambiguous or queries are unclear.
So, what can we do in these cases? 🤔
- One option is to simply build the end-to-end system, especially if your core competence relies on it. However, what about the hidden costs of handling large scale datasets? And what about the maintenance costs?
- Another option is to find a production ready system that is scalable, handles edge cases, and adheres to relevant regulations of the industry.
One of the best solutions for option (2), a battle tested system for querying and extracting insights from large scale visual data sources, is Tenyks.
Figure 6 shows how Tenyks excels at searching for general and abstract concepts, as well as objects. By using visual prompting, Tenyks’ proprietary technology can refine queries to extract very specific details from large-scale visual data repositories (e.g., videos and large datasets).
🔥 Learn more about the cutting edge of multimodality and foundation models in our CVPR 2024 series:
- Image and Video Search & Understanding (RAG, Multimodal, Embeddings, and more).
- Top Highlights You Must Know — Embodied AI, GenAI, Foundation Models, and Video Understanding.
🔥 Learn more about Segment Anything Model 2 (SAM 2):
- 🆕 SAM 2 + GPT-4o — Cascading Foundation Models via Visual Prompting — Part 1
References
[1] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
[2] Large Language Models for Information Retrieval: A Survey
[3] Exploring Visual Prompts for Adapting Large-Scale Models
[4] An embarrassingly simple approach to zero-shot learning
[5] Visual Instruction Tuning
[6] Learning Transferable Visual Models From Natural Language Supervision
[7] Fine-tuning Language Models for Factuality
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan
If you would like to know more about Tenyks, sign up for a sandbox account.

