Fundamentals of MLOps — Part 1 | A Gentle Introduction to MLOps

Ever wondered how organizations build, deploy, maintain, adapt, retrain and redeploy large-scale AI-powered applications? In today’s fast-paced industry, maintaining and deploying scalable applications while being able to adapt quickly to the changing consumer requirements is of utmost importance.
Through this 4-blog series on Fundamentals of MLOps, you will be introduced to some of the core ideas behind combining the long-established practices of DevOps with the emerging field of Machine Learning. You will be exposed to the various stages of an ML model lifecycle, including data versioning, experimentation, evaluation & monitoring. To consolidate these principles, you will also get an opportunity to build & deploy end-to-end ML pipelines by leveraging various ML Operations Management tools & frameworks such as DVC, PyCaret, MLFlow & FastAPI.
By the end of this series, you would also have trained, experimented with & deployed a production-ready ML model on AWS, & served it using FastAPI.
Contents
- Introduction
- The Rise & Adoption of DevOps Principles
- MLOps Demystified
- ML Workflow Lifecycle
- MLOps Principles
- Benefits of MLOps Solutions
- Challenges Associated with MLOps
- Tools & Infrastructure for MLOps
- Adoption of MLOps
- Concluding Remarks
- Additional References
Introduction
Machine learning (ML) is an Artificial Intelligence (AI) technology that allows a system to automatically learn and improve based on experience rather than explicit programming. ML has garnered significant interest in recent years, both in academia as well as a solution to real-world commercial challenges. ML is revolutionizing the world by modernizing industries like healthcare, education, transportation, food, entertainment, and various assembly lines, among others. However, some of the bitter truths of the ML world, when taken to production (that can easily be glossed over) are:
- It takes far longer to deploy ML models to production than it does to create them
- The actual ML code makes up just a small portion of real-world ML systems, while the surrounding infrastructure in the production environment is extensive and complicated
Historically, ~85 % of ML models that are built never reach production. Surveys & reports also suggest that only ~60% of projects make it from prototype to production — that too at organizations that have a decent experience with AI. Moreover, the delivery durations of such products & services are usually defined in months whereas ideally they should be measured in hours (or days, at max). According to the 2020 State of Enterprise Machine Learning report, the main challenges faced by people developing systems with ML capabilities are scale, version control, model reproducibility, and aligning stakeholders.
These studies should be enough to drive home the fact that straightforward as it may seem, bringing ML research in academia to build production-ready & usable ML systems requires far more considerations than one may otherwise imagine.
Ultimately, ML systems boil down to developing and implementing computer code. Thus, in spite of some stark contrasts, it should come as no surprise that the management of these systems is comparable to traditional software development. To understand how one can improve the operationalization (deployment & maintenance) of ML systems (through MLOps), we first need to understand some of the basic principles of DevOps, which have proved to increase an organization’s ability to deliver applications and services faster than traditional software development processes.
The Rise & Adoption of DevOps Principles
Since MLOps draws its roots from several DevOps principles, it is imperative to spend some time understanding the DevOps philosophy & some of its practices. This section is dedicated to providing a quick overview of the DevOps culture, practices, tools & adoption.
DevOps refers to a set of practices & tools that combine the development (Dev) & IT operations (Ops), with the primary goal of optimizing the flow of value from an idea to the end-user. This is usually achieved through:
- Shortening the software system development lifecycle
- Providing continuous delivery with high software quality
DevOps typically aims to overcome the institutional divide between the team that writes the code (Dev) and the team that manages the infrastructure and tools used to run and manage the product (Ops).
DevOps Practices & Tools
DevOps practices reflect the idea of continuous improvement and automation, which include:
- Continuous development
- Continuous testing
- Continuous integration (CI)
- Continuous delivery
- Continuous deployment (CD)
- Continuous monitoring
- Infrastructure as code
Followers of DevOps practices often use certain DevOps-friendly tools as part of their DevOps “toolchain”. The goal of these tools is to further streamline, shorten, and automate the various stages of the software delivery workflow. The image below clearly depicts the DevOps lifecycle stages & the important tools associated with each stage.
The DevOps Culture and Mindset

Although DevOps may refer to a lot of technical solutions, in order to do those practices, we need people. Hence, to implement such solutions, it is crucial to first focus on people, collaboration, and mindset for successful DevOps implementation. This could be a big shift in thinking. Following are some of the essential values for a DevOps mindset:
- Focus on our stakeholders and their feedback rather than simply changing for the sake of change
- Strive to always innovate and improve beyond repeatable processes and frameworks
- Inspire and share collaboratively instead of creating a silo
- Measure performance across the organization, not just in a line of business
- Promote a culture of learning through lean quality deliverables, not just tools and automation
Adoption of DevOps
Over the last 15 years, tens of thousands of organizations have adopted a DevOps way of working in order to adapt more effectively to business issues. Some of the companies that are killing it using the DevOps culture include Amazon, Walmart, Netflix, Facebook, Nordstrom, etc.
DevOps is here to stay — for very good reasons. Many believed it was impossible, yet DevOps has succeeded in bringing together business users, developers, test engineers, security engineers, and system administrators in a unified process focused on satisfying client needs.
Motivation for Combining ML & DevOps
In the world of AI/ML, data scientists (like software developers) must collaborate closely with various other teams, including business, engineering, and operations, to operationalize ML models. The challenges associated with ML model operationalization are quite similar to those of software production, where DevOps has shown its worth. The success of DevOps practices & their rapid adoption by several software development organizations has prompted the use of similar principles to streamline & improve the development, deployment & maintenance of Machine Learning systems as well.
MLOps Demystified
MLOps or Machine Learning Operations is a relatively new discipline that aims to bridge the gap between experimentation with ML models and their production by implementing fundamental concepts that make machine learning repeatable, collaborative, and continuous.
Wikipedia defines MLOps as:
MLOps is the process of taking an experimental Machine Learning model into a production system.
Although at first, it may seem as if MLOps = ML + DevOps (because it pulls heavily from the concept of DevOps), yet that isn’t the most accurate representation of MLOps. In spite of their similarities, there is a critical difference setting DevOps & MLOps apart: while software code is static (relatively), data is always changing, which means ML models must constantly be learning and adapting to newer inputs. The complexity of this environment, as well as the fact that machine learning models are composed of both code and data, is what distinguishes MLOps as a new and distinct field.
Since Data Engineering provides important tools and concepts that are indispensable to solving the puzzle of ML in production, MLOps can be defined as follows:
MLOps is a set of practices that lies in the intersection between ML, DevOps & Data Engineering, which aims to deploy and maintain ML systems in production reliably and efficiently
Some other ML-specific challenges that MLOps caters to are mentioned below:
- Data & Hyperparameter versioning
- Iterative experimentation & evaluation of models
- Production monitoring to ensure the performance of the model with new/unseen data
- Dynamic scaling of computing power (infrastructure) in production
With the plethora of tools & opportunities that it provides for building & deploying end-to-end ML systems, MLOps is gaining a lot of traction among Data Scientists, ML Engineers, and AI enthusiasts. While MLOps is relatively nascent, the data science community generally agrees that it is an umbrella term for best practices and guiding principles around machine learning & not a single technical solution.
ML Workflow Lifecycle
In order to appreciate the various principles underlying in MLOps, we first need to look at what a typical machine learning workflow lifecycle looks like so that that we can recognize the issues in each stage and how MLOps practices can address them. The following diagrams depict a high-level overview & a detailed representation of the core steps in a typical ML system:
It is evident that a classic ML workflow comprises 3 major phases, namely Data Preparation, Model Training & Tuning (this is the core of an ML workflow), and Deployment & Monitoring. Next, we move on to dive slightly deeper into the steps associated with each of these phases.
Before understanding the 3 major phases of ML workflows, it is imperative to first develop a thorough understanding of the business case & critically evaluate the requirement of ML to address the problem statement.
Data Preparation
- Data Ingestion & Aggregation: It is the collection of data from many sources to a storage repository from which it may be accessed, utilized, and analyzed. The most common kind of data ingestion is batch processing, which involves the collection of data periodically. On the other hand, real-time data is collected using stream processing.
- Exploratory Data Analysis: It refers to the essential process of conducting preliminary studies on data in order to unravel patterns, identify anomalies, test hypotheses, and validate assumptions using summary statistics and graphical representations.
- Data Wrangling: It is the act of cleansing and integrating chaotic and complicated data sets for easy access and analysis. It also involves the correction of errors in data such as missing value imputation & treatment of outliers.
- Data Labeling & Annotation: It is the act of adding one or more relevant and useful labels to raw data (pictures, text files, videos, etc.) and so as to offer context for the training of a machine learning model.
- Feature Engineering: It is the process of extracting features (characteristics, traits, and attributes) from raw data using domain expertise. It is an essential step for ML algorithms, while it may not be explicitly required for deep learning tasks (since in DL, essential features are expected to be automatically inferred & used by the layers of the neural network)
- Data Splitting: It involves splitting the data into training, validation, and test datasets to be used during the core machine learning stages to produce the ML model
Model Training & Tuning
- Algorithm Selection: It is a method for selecting an algorithm from a portfolio on an instance-by-instance basis. It is driven by the fact that various algorithms perform differently on many practical applications, i.e., although one algorithm works well in some circumstances, it performs badly in others, and vice versa.
- Model Training: It is the process of applying the machine learning algorithm on training data to train an ML model.
- Model Validation: It is the process of comparing model outputs to independent real-world observations systematically in order to assess the quantitative and qualitative correspondence with the reality, before serving it in production to the end-user.
- Hyperparameter Tuning: A hyperparameter is a model argument whose value is set before the learning process begins. Hyperparameter tuning involves the iterative approach of choosing a set of hyperparameters for a learning algorithm until optimality is achieved.
Deployment & Monitoring
- Model Testing: It is referred to as the process where the performance of a fully trained model is evaluated on a testing set.
- Model Packaging: It is the process of exporting the fully trained ML model into a specific format (like PMML, PFA, ONNX, etc.) so that it can be consumed by the end-user.
- Model Serving: It refers to the process of deploying the packaged ML model in a production environment. This can be achieved in 2 major ways:
- Model-as-a-Service: The model is deployed into a simple framework to provide a REST API endpoint that responds to requests in real-time
- Embedded Model: The model is packaged into an application & then published
- Performance Monitoring: It is the process of observing the ML model performance based on live and previously unseen data so as to capture signals that trigger the need for potential retraining of the model.
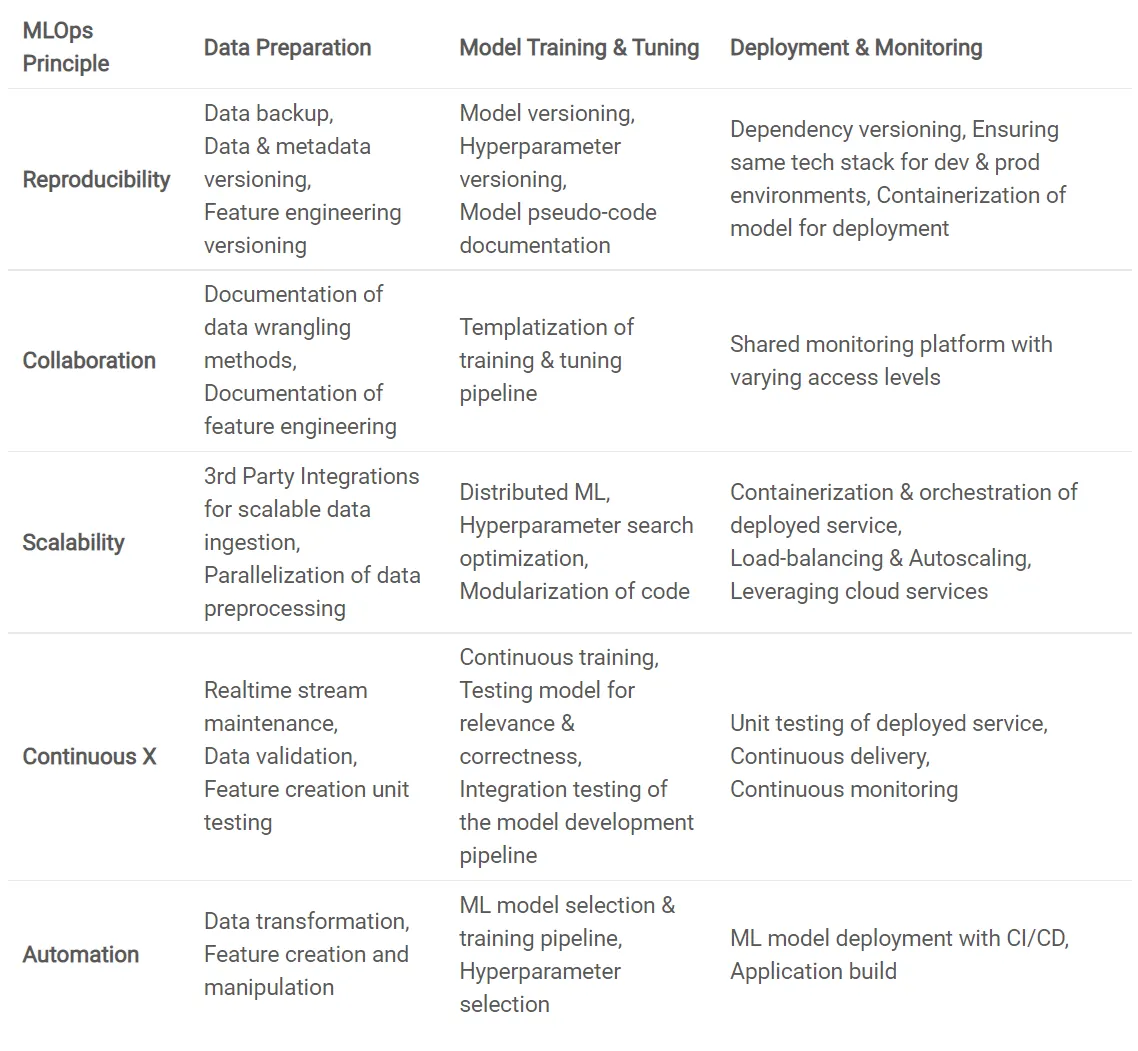
MLOps Principles
The core objective of MLOps is to circumvent the technical debt involved in developing & deploying ML systems. The paradigm of MLOps has certain pillars as guiding principles. These ensure that machine learning is reproducible, collaborative, scalable and continuous.
Reproducibility: It ensures that given the same input, each phase of data processing, ML model training, and ML model deployment should yield similar outputs. It involves versioning of not only the code but data, hyperparameters & other metadata as well, along with effective documentation at each of the stages of the workflow. This allows every production model to be audited & reproduced. Some of the key practices that ensure reproducibility are Versioning & Experiment Tracking
Collaboration: Successful implementation of MLOps, like DevOps, involves people working together — the collaboration is usually between data scientists, ML engineers, business analysts and IT operations professionals. MLOps encourages teams to make transparent the whole process of creating an ML model, from data extraction through model deployment and monitoring.
Scalability: MLOps enables organizations to scale in order to address critical issues by making ML initiatives more efficient and effective. This implies the enhancement in the ability to train a larger number of models & also use models with high-scale data in production.
Continuous X: The lifecycle of a trained model is fully determined by the use-case and the dynamic nature of the underlying data. Without continuous processes, data scientists will have to spend a lot of effort each time developing manual and ad-hoc models. MLOps encourages the following practices:
- Continuous Integration (CI) adds testing and validating data and models to the testing and validating code and components.
- Continuous Delivery (CD) refers to the delivery of an ML training pipeline that deploys another ML model prediction service automatically.
- Continuous Training (CT) is a characteristic specific to ML systems that automatically retrains ML models for re-deployment.
- Continuous Monitoring (CM) is concerned with the monitoring of production data as well as model performance indicators that are linked to business metrics of end-users
Automation: The objective of MLOps is to ensure reduced time & cost of pushing models into production. This translates to automating the end-to-end ML workflow pipeline without any manual intervention, which can be achieved in the form of automated triggers. Automated testing helps to discover problems quickly and in the early stages enabling fast fixing of errors.
The following table summarizes how the various principles of MLOps can be applied to the usual ML workflow lifecycle stages.
Benefits of MLOps Solutions
Having understood the key objectives & concepts of MLOps, we are now fully in a position to appreciate the benefits that it offers.
- Rapid innovation through robust machine learning lifecycle management
- Creation of reproducible workflows and models
- Clear direction & measurable benchmarks provided to data scientists
- Easy deployment of high precision models in any location
- Machine learning resource management system and control
- Open communication between data science teams and operations team, leading to opening up of bottlenecks
- Effective governance of data & process
- Improvement in quality of models due to continuous & focused feedback
- Rigorous automated testing & validation ensures that model bias is removed while improving the explainability
Evaluating the Effectiveness of MLOps
Following are some of the metrics (drawn from software delivery) that can be used to evaluate how MLOps impacts an organization:
- Deployment Frequency: It depends on model retraining requirements & level of automation of the deployment process
- Lead Time for Changes: It depends on the duration of exploratory data analysis, model selection & training, and the number of manual steps
- Mean Time to Restore (MTTR): It depends on the number and duration of manually performed model debugging & model deployment steps
- Change Failure Rate: It can be expressed as the difference between the currently deployed ML model performance metrics to the previous model’s metrics
Challenges Associated with MLOps Adoption
As exciting as ML may seem, the truth is that as this technological operational technique becomes more prevalent, an organization confronts a slew of problems stemming from how to correctly combine code and data to achieve predictions. Some of the challenges faced by organizations implementing MLOps are as follows:
- Organizations being hesitant to incorporate machine learning into processes since it is difficult to rely on models in locations where people used to operate in the past.
- The assessment and consideration of model risks when implementing a machine learning model
- Lack of specialists in the existing training market who are equally well versed in competencies at the intersection of Data Science, DevOps and IT
- Dependence on the various tools might cause people to get addicted to those tools which provide with short-term benefits over those that provide long-term benefits
- Negligence of test automation and more focus on CI/CD deployments
The key to overcoming these issues is to be aware of them in order to build a solid knowledge base, a broad perspective, and to learn to use MLOps principles and practices, which will aid in the implementation of a fully automated integrated framework and, as a result, enhance business verticals.
Tools & Infrastructure for MLOps
Ideally, MLOps must be language-, framework-, platform-, and infrastructure-agnostic in practice. There are tons of tools & approaches to address MLOps problems, ranging from adopting off-the-shelf machine-learning platforms in the cloud to implementing in-house solutions by combining open-source libraries. A great open-source MLOps tool provides users with a platform with full operational flexibility on a cheap budget and access to all necessary resources. It gives organizations greater space to cooperate and more freedom on a single platform.
Here is a curated list of MLOps tools & frameworks that cater to the various portions of the MLOps landscape. While browsing through the list, it is important to note that the MLOps landscape is rapidly evolving, with newer & more advanced tools being developed for specialized applications. The image below summarizes some of the most popular MLOps frameworks currently adopted in the industry to develop the ML infrastructure:
In the upcoming parts of this series, we will dig deep into some of these tools (DVC, PyCaret & MLFlow) to gains hands-on exposure & use them for our own projects.
MLOps Technology Stack Template
Given the plethora of tools available in the wild, to facilitate & streamline the consideration of tools that an organization could use to adopt MLOps practices, the template (courtesy: Henrik Skogström) given below can be used. Clearly, it breaks down the entire workflow into components, where one can jot down the requirements & select appropriate tools to come up with a customized technology stack.
Towards the end of this series, we will be in a position to revisit this template & fill it up with the various tools that we learn along the way.
You can download this template for personal use as well.
Adoption of MLOps
In spite of being in its infancy, the MLOps trend became more visible in the last few years due to a number of well-known companies & open-source frameworks who started sharing information about their in-house ML stack & the way they have adopted MLOps practices to boost their productivity. Some examples of such companies are:
- Netflix: It uses an in-house ML framework-agnostic library called Metaflow to rapidly experiment by training machine learning models and effectively managing data. Using the Metaflow API, their ML workloads seamlessly interact with AWS Cloud infrastructure services. It also uses an internal tool called Runway to manage all models in production & automatically alert the ML teams for models that are stale in production.
- Uber: Teams at Uber operationalize their ML models through an internal ML-as-a-service platform called Michelangelo, which enables them to seamlessly build, deploy, and operate ML solutions at scale. They also use Manifold — a model-agnostic visual debugging tool.
- Facebook: It has developed a brand-new platform, FBLearner Flow, that is capable of effortlessly reusing algorithms across products, scaling to perform thousands of concurrent custom experiments, and organizing experiments with simplicity. It can ingest trillions of data points every day, trains thousands of models (either offline or in real-time) and then deploys them to the server fleet for live predictions.
- Carbon: Carbon use DataRobot to create comprehensive credit risk models, saving them a whole end-to-end process and allowing the firm to focus on sourcing the correct data and making other decisions that assist drive their business ahead.
MLOps demands the understanding of data biases as well as a strict discipline within the company that decides to adopt it. As a result, each organization should build its own set of practices for adapting MLOps principles to its AI development and automation.
MLOps-Related Conferences
The academic & industrial research in the field of MLOps is growing in leaps & bounds, with newer & more efficient approaches being developed to solve research problems in MLOps. Most of this research is actively showcased at public conferences & with the traction that MLOps has gained over the years, there are some conferences dedicated to MLOps research. Here are some conferences dedicated specifically towards MLOps, for interested learners:
Concluding Remarks
That completes the first part of this Fundamentals of MLOps blog series. This has been a rather theory-intensive blog, with the major focus on building a strong conceptual foundation in order to use the MLOps tools effectively in the future. I hope that you now have a fair understanding of the core principles & some of the practices of MLOps (& DevOps) & are keen to actually implement some of these in your own ML projects.
In the next parts, we will get our hands dirty by implementing some of the MLOps practices that we saw in this post, using various tools & frameworks.
Following are the other parts of this Fundamentals of MLOps series:
- Part 2: Data & Model Management with DVC
- Part 3: ML Experimentation using PyCaret
- Part 4: Model Tracking with MLFlow & Deployment with FastAPI
Thank you & Happy Coding!
Additional References
Research Papers
- Mäkinen, S. et al. “Who Needs MLOps: What Data Scientists Seek to Accomplish and How Can MLOps Help?” WAIN (2021)
- Sculley, D. et al. “Hidden Technical Debt in Machine Learning Systems.” NIPS (2015)
- Breck, E. et al. “What’s your ML Test Score? A rubric for ML production systems.” NIPS (2016)
- Goyal, A. “Machine Learning Operations.” IJITIT (2020) Vol 4
Articles & Blogs
- What is DevOps? The Ultimate Guide
- Motivation & Evolution of MLOps
- ML Ops: Machine Learning as an Engineering Discipline
- MLOps Principles
- A Beginner’s Guide to Machine Learning Operations
- How These 8 Companies Implement MLOps: In-Depth Guide
- The Evolution of DevOps
- 10 Companies Killing it at DevOps
- Best Practices for ML Engineering
- Machine Learning Life-cycle Explained
- MLOps Benefits that make it an Upcoming Industry Trend
Books
Miscellaneous
If you enjoyed this article, I’m certain that you’d love my brand-new FREE AI Products & Research newsletter, “The Vision, Debugged”.
Subscribe & join the bandwagon of enthusiastic readers across top companies like Microsoft, Google, Walmart, Deloitte & more to get cool AI products & research insights, cheat sheets & resources.
About the Author
Hey folks!
I’m Tezan Sahu, an Applied Scientist at Microsoft, an Amazon #1 Bestselling Author (for the book “Beyond Code: A Practical Guide for Data Scientists, Analysts & Engineers”), and co-author of “The Vision, Debugged” newsletter.
I am passionate about helping aspiring data scientists & software developers kickstart their careers, deliver consistent impact & become differentiated professionals in the field of AI & Data Science.
If you are interested in learning more about how you can leverage AI to stay ahead of the curve and boost your results, connect with me on LinkedIn & subscribe to my newsletter.
