Tony HajdariincdapioCI/CD and Change Management for Pipelines — Part 3Welcome to the third installment of this four part series. In the first article I discussed some of the concepts related to continuous…Apr 8, 20201Apr 8, 20201
Tony HajdariincdapioCI/CD and Change Management for Pipelines — Part 2Welcome to the second article in this four part series. In the first article I discussed some of the concepts related to continuous…Mar 16, 20202Mar 16, 20202
Tony HajdariincdapioCI/CD and Change Management for Pipelines — Part 1Welcome to my latest series on continuous integration of data pipelines with Cloud Data Fusion and/or CDAP (CDF/CDAP). This will be a 4…Mar 9, 20201Mar 9, 20201
Tony HajdariincdapioWrangler Functions Cheat SheetTo really become a Ninja with Wrangler Directives you have to get to know all the functions that Wrangler supports. In this article I’m…Feb 11, 20201Feb 11, 20201
Tony HajdariincdapioHow to debug your pluginIn a previous article I showed you how to get started with plugin development in CDAP. But, wouldn’t it be nice if we can attach a debugger…Jan 27, 2020Jan 27, 2020
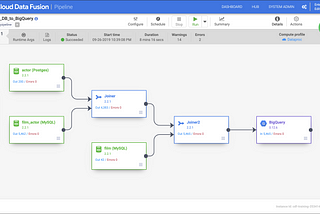
Tony HajdariincdapioDeploying and Running CDF pipelines with RESTBy now you probably know that you run CDAP pipelines on Cloud Data Fusion (CDF), but did you know that you can also control your CDF…Jan 13, 2020Jan 13, 2020
Tony HajdariincdapioGetting started with CDAP plugin developmentOne of my favorite features of CDAP is that the extensibility of the platform allows you to add new functionality yourself. If you need to…Dec 2, 2019Dec 2, 2019
Tony HajdariincdapioAdvanced CDAP DirectivesCDAP provides a number of ways to process data in a pipeline, and one of the most flexible ways to build advanced data processing logic is…Nov 18, 20191Nov 18, 20191