Matt MillerVariants: Comparing LCSH alt labels and Wikipedia redirectsHow does Wikipedia redirects compare to Library of Congress Subject Heading alternative labels.Sep 25, 2019Sep 25, 2019
Matt Milleranaphora.govThe new sample data set from the web archives of the Library of Congress consists of 1000 audio files archived from various government…May 17, 20191May 17, 20191
Matt MillerWarhol RepetionI was excited to see the digitization and posting of some of the 130,000 Warhol exposures given to the Cantor Arts Center. Many of the…Oct 27, 2018Oct 27, 2018
Matt MillerPatented ScreenshotsI came across quite a few screenshots included in patent application for early(ish) websites/technologies. I love being able to see the old…Jun 5, 2018Jun 5, 2018
Matt MillerEffect Bath — DissectionA look at the code behind a Twitter bot: https://twitter.com/effectbathMay 25, 2018May 25, 2018
Matt MillerEffect Bath — Collaging 16,000 BBC Sound EffectsGrowing up visiting the public library my siblings and I would always head over to the CD drawers looking for anything good. They were a…May 24, 2018May 24, 2018
Matt MillerAnalyzing DOI Citations in English WikipediaBuilding on my previous look at book (ISBN) citations used in English Wikipedia using the data recently released I turn to the other…Apr 20, 2018Apr 20, 2018
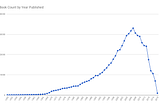
Matt MillerAnalyzing Books Cited in English WikipediaLooking at 600K books cited in english Wikipedia, looking at publish year, authors, subjects and institutional holdings.Apr 9, 2018Apr 9, 2018
Matt MillerLittle Lists Twitter BotMaking little lists of seemingly (un)related books held at the Library of CongressMar 19, 2018Mar 19, 2018