PinnedSteve RobertsinTowards Data SciencePolicy and Value IterationAn Introduction to Reinforcement Learning: Part 3Jul 12, 20212Jul 12, 20212
PinnedSteve RobertsinTowards Data ScienceState Values and Policy EvaluationAn Introduction to Reinforcement Learning: Part 1Jan 4, 20212Jan 4, 20212
Steve RobertsinTowards Data ScienceMonte Carlo MethodsAn Introduction to Reinforcement Learning: Part 4Aug 26, 20231Aug 26, 20231
Steve RobertsState Values and Policy Evaluation in 5 minutesAn Introduction to Reinforcement LearningJan 11, 2023Jan 11, 2023
Steve RobertsinTowards Data ScienceCreating a Custom Gym Environment for Jupyter NotebooksPart 2: Rendering to Jupyter Notebook CellsJul 29, 20221Jul 29, 20221
Steve RobertsinTowards Data ScienceCreating a Custom Gym Environment for Jupyter NotebooksPart 1: Creating the frameworkJun 7, 20221Jun 7, 20221
Steve RobertsinTowards Data ScienceThompson Sampling using Conjugate PriorsMulti-Armed Bandits: Part 5bMar 9, 20214Mar 9, 20214
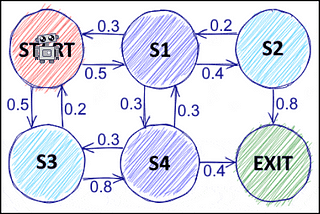
Steve RobertsinTowards Data ScienceMarkov Decision Processes and Bellman EquationsAn Introduction to Reinforcement Learning: Part 2Feb 5, 2021Feb 5, 2021
Steve RobertsinTowards Data ScienceA Comparison of Bandit AlgorithmsMulti-Armed Bandits: Part 6Nov 10, 20202Nov 10, 20202
Steve RobertsinTowards Data ScienceThompson SamplingMulti-Armed Bandits: Part 5Nov 2, 20209Nov 2, 20209