Tirthajyoti SarkarinHeartbeatHow to Write Test Code for Data Science PipelineHow to write Pytest code for reliably testing your data science pipelineFeb 14, 20223Feb 14, 20223
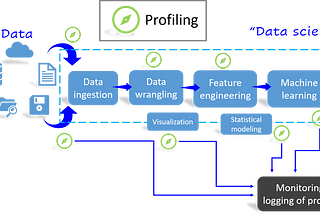
Tirthajyoti SarkarinHeartbeatTime-Profiling Data Science CodeWhy and how to profile your data science codeFeb 3, 2022Feb 3, 2022
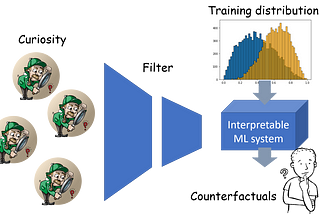
Tirthajyoti SarkarinTowards Data ScienceExplainable AI and the Focus on Human Curiosityand concentrating on the top few factors and counterfactualsJan 24, 2022Jan 24, 2022
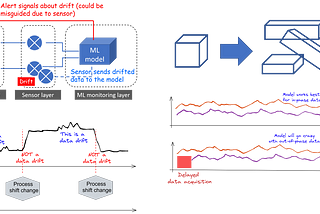
Tirthajyoti SarkarinTowards Data ScienceData drift: It can come at you from anywhereThe concept of data drift is illustrated visually in various shapes and forms.Jan 19, 20221Jan 19, 20221
Tirthajyoti SarkarinTowards Data ScienceThe Right Hardware for your AI workload —Unusual ConsiderationsWe point out a few less-mentioned and underrated features and inter-relationships to keep in mind while designing the best hardware…Jan 17, 2022Jan 17, 2022
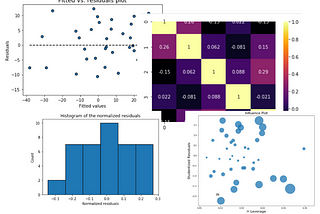
Tirthajyoti SarkarinTowards Data ScienceDon’t just fit data, gain insights tooA lightweight Python package can give you a lot of insights into your regression problems.Jan 13, 2022Jan 13, 2022
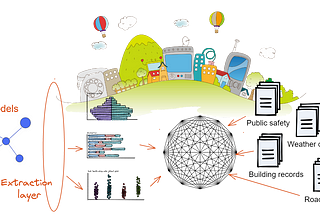
Tirthajyoti SarkarinTowards Data ScienceHow AI can help smart city initiativesSome ideas for helping smart city initiatives, based on AI perception and citizen data sourcing.Jan 10, 20221Jan 10, 20221
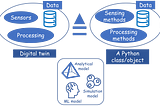
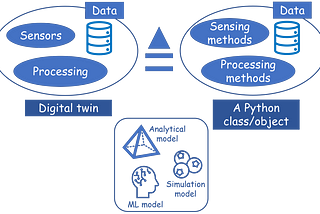
Tirthajyoti SarkarinTowards Data Science“Digital Twin” with Python: A hands-on exampleA step-by-step guide to building a digital twin example of an electronic switch (transistor) with Python.Dec 15, 20214Dec 15, 20214
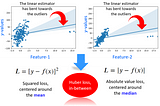
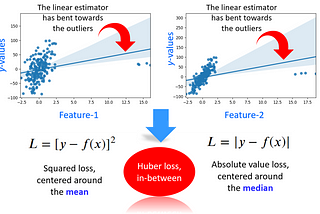
Tirthajyoti SarkarinTowards Data ScienceRegression in the face of messy outliers? Try Huber regressorOutliers in the data are ubiquitous, and they can mess up your regression problem. Try Hubber regressor to tackle this problem.Nov 4, 20211Nov 4, 20211
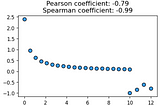
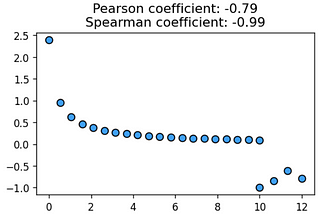
Tirthajyoti SarkarinTowards Data ScienceSpearman coefficient: Tool for a generalized correlation analysisLinear relationships are not all a correlation analysis can reveal. We discuss rank-based correlation that is more generalized and…Nov 1, 2021Nov 1, 2021