Word Count in Apache Hadoop (MapReduce)
Due to rise and surge in the amount of data being generated nowadays is leading a major challenge to the software companies to handle and process the data. Scalability, Reliability and Cost effectiveness in storing and processing this data has become the cornerstone task for companies and organizations since the last decade.
MapReduce in Hadoop is a software framework for ease in writing applications of software, processing huge amounts of data. MapReduce provides the facility to distribute the workload (computations) among various nodes(analogous to commodity hardware). Hence, reducing the processing time as data on which the computation needs to be done is now divided into small chunks and individually processed. Through MapReduce you can achieve parallel processing resulting in faster execution of the job.

MapReduce Word Count is a framework which splits the chunk of data, sorts the map outputs and input to reduce tasks. A File-system stores the output and input of jobs. Re-execution of failed tasks, scheduling them and monitoring them is the task of the framework.
Figure below shows the architecture as well as working of MapReduce with an example:
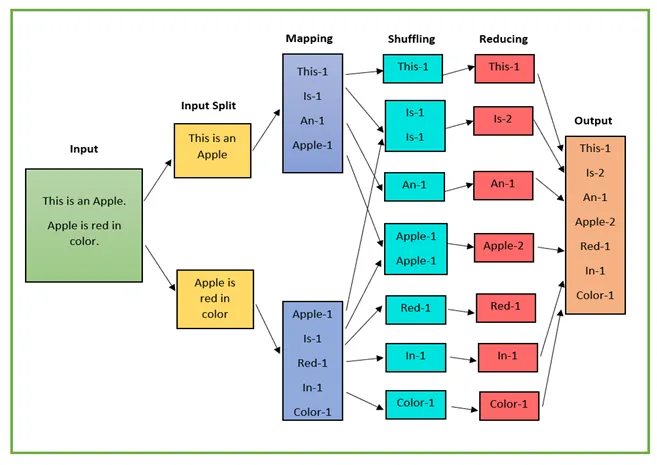
Splitting: The parameter of splitter can be anything. By comma, space, by a new line or a semicolon.
Mapping: This is done as explained below.
Shuffle/Intermediate splitting: The process is usually parallel on cluster keys. The output of the map gets into the Reducer phase and all the similar keys of data are aligned in a cluster.
Reducing: This is done as explained below. Final result — All the data is clustered or combined to show the together form of a result.
For understanding the working of MapReduce and its architecture we will implement our own Mapper and Reducer codes.
Let’s dive into the implementation part.
First, we will import our dataset into the HDFS (Hadoop Distributed File System).
The dataset can be a simple txt file with some words or sentences written in it.
Please follow these steps to import the dataset:
Step 1. Download and extract the compressed file of the text-based dataset from a source and save it as a txt file in your local storage.
Step 2. Create a directory in the Hadoop HDFS by using the following command:
hdfs fs -mkdir /input_wordCountStep 3. Copy the txt file in the created directory from the local directory using -ls option. For example:
hdfs fs -put T:\Tirth\Documents\word_count.txtStep 4. To check whether file is present in the directory, run the following command:
hdfs fs -ls /input_wordCount
Now we will prepare the source code for word count. For this purpose it is strongly suggested to use an IDE (such as Eclipse or IntelliJ) which allows to create an executable JAR file for your project. Here we are using Eclipse IDE.
Step 1. Create a Java Project and declare a package within it.
Step 2. Create a class in the package.
Step 3. Insert this code in the class file.
WordCount.java
package com.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String [] args) throws Exception
{
Configuration c=new Configuration();
String[] files=new GenericOptionsParser(c,args).getRemainingArgs();
Path input=new Path(files[0]);
Path output=new Path(files[1]);
Job j=new Job(c,"wordcount");
j.setJarByClass(WordCount.class);
j.setMapperClass(MapForWordCount.class);
j.setReducerClass(ReduceForWordCount.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(j, input);
FileOutputFormat.setOutputPath(j, output);
System.exit(j.waitForCompletion(true)?0:1);
}
public static class MapForWordCount extends Mapper<LongWritable, Text, Text,
IntWritable>{
public void map(LongWritable key, Text value, Context con) throws
IOException, InterruptedException
{
String line = value.toString();
String[] words=line.split(" ");
for(String word: words )
{
Text outputKey = new Text(word.toUpperCase().trim());
IntWritable outputValue = new IntWritable(1);
con.write(outputKey, outputValue);
}
}
}
public static class ReduceForWordCount extends Reducer<Text, IntWritable, Text,
IntWritable>
{
public void reduce(Text word, Iterable<IntWritable> values, Context con)
throws IOException, InterruptedException
{
int sum = 0;
for(IntWritable value : values)
{
sum += value.get();
}
con.write(word, new IntWritable(sum));
}
}
}The code above extends the predefined framework classes provided by Hadoop for Mapper and Reducer. For the current scenario we are only focusing on Mapping and Reducing phases.
Initially you will be prompted multiple error messages in the import statements involving apache.hadoop package. This is because we need to import the utility classes provided by Hadoop to implement MapReduce. This classes are compressed into executable jar files which are provided in the installation folder of Hadoop.
These jar files must be included to run any MapReduce task in Hadoop. It can be done by following steps:
- Right Click on your project in the files navigator to the left.
- Select Build Paths and click on Configure Project.
- Head to Libraries Tab and select Add External Jar button.
- In the pop-up window, navigate through the ‘share’ folder in your Hadoop installation directory.
- You will notice some folders and JAR files.
- Include those JARfiles add jar files from all the folders as well. [For help, refer this Medium Article]
- Once, all the jar files are included, save and close the config window.
- You will notice that all the errors which were prompted are now gone. If not then you need to delete a fie (probably a config file automatically created in the same package while creating the package).
- After all the above steps are completed error-free, you need to create a JAR file of your project. To do this, Right click on you project and select Export.
- Select JAR from Java folder section.
- Browse the directory you want to save and give the name to the file.
The source code is now ready to be executed in the MapReduce environment.
We need to run the JAR file for which our input file will be the dataset txt file and output will be stored in another file. Our aim is to run the JAR file on the input file which is present in HDFS.
To do this, we have a command with following syntax:
hadoop jar <jar_path> <class_path> <input_file_path_in_hdfs> <output_file_path_in_hdfs>Note that the JAR file need not to be uploaded to HDFS, we can directly connect it from our local storage. The class path includes package name and class name since classes reside in a package. Example:
hadoop jar T:\Tirth\Documents\MapReduceWordCount.jar com.mapreduce.wc/WordCount /input_wordCount /output_dirAfter running this command, Mapper job start getting executed. After a while Reducer job starts consequently. The details of the job are being displayed in the command prompt.

Once the execution is finished, you need to access the output using ‘cat’ command. Note that the output will be stored in the file mentioned in the above command by you and it will be in HDFS. To access the output, write the following command:
hadoop dfs -cat /output_dir/*
As in Fig 1.3 we can see the format of output is Word Number. The number represents the total occurrence of that word in the entire text file. By using Map Reduce, we can reduce the computing time by a considerable amount. It is much faster than the traditional algorithm used in programming languages.
You can also access the application in Hadoop Dashboard. Head to a browser and open http://localhost:8088/clusters (make sure that all your Hadoop components are running).

Fig 1.4 shows highlighted field of Start Time and Finish Time, the difference of both the values equal to 23 seconds, which is considerably lower compared to traditional frequency counting algorithm applied on a big size file.
You can verify the presence of output file in the HDFS dashboard by visiting http://localhost:9870 and navigate to Utilities section.
References:
Source Code: https://dzone.com/articles/word-count-hello-word-program-in-mapreduce
So that’s all from me. Hope you learned through the process and assuming that you have completed the execution of MapReduce successfully. Congratulations, you have now learned how to run a MapReduce in Hadoop. With this, you are now capable enough to implement a long processing task through MapReduce which lowers the execution time to a great extent. Expecting that you have enjoyed the read. I felt that some steps might be missing but this could be enough to empower you to run your first MapReduce job. Do let me know about your views and suggestions on this article.
Thankyou for reading. Have a great day ahead (or night to ‘burn the midnight oil’ ;-) ). See you with my next article, this is Tirth Shah, signing off.