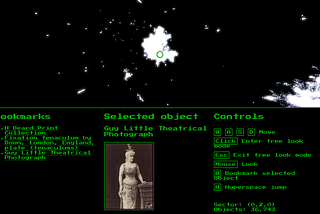
Tristan Roddisincogapp3D space curatorFor the recent hack day with the Heritage Connector project I teamed up with Iain to create a “game” where you fly through space exploring…Dec 2, 2021Dec 2, 2021
Tristan RoddisincogappWrist-mounted art-appreciation computer (AKA QArtCode)Explore the V&A’s collection via a nerdy watchAug 9, 2021Aug 9, 2021
Tristan RoddisincogappArtGIF: animate collection images for fun and profitEasily create animated GIFs from the Art Institute of Chicago’s collection using the online editor at https://artgif.netlify.app/Mar 2, 20211Mar 2, 20211
Tristan RoddisincogappBot to the FutureUsing machine learning to develop the ultimate MuseWeb paperJul 5, 2019Jul 5, 2019
Tristan RoddisincogappVisualising words across timeSummary: we created an interface to query search terms from the Qatar Digital Library, and you can play around with it yourself using the…May 3, 2019May 3, 2019
Tristan RoddisincogappEverything You Always Wanted to Know About IIIF* (*But Were Afraid to Ask)Hello and welcome.Nov 10, 20171Nov 10, 20171
Tristan RoddisincogappPlaying ancient music without an instrumentHow we took an archive of sheet music and used software to turn it into sound.Nov 8, 20171Nov 8, 20171
Tristan Roddisincogapp#Coghack: creating a bike-mounted pollution sensorPart of the Coghack Hackathon seriesMar 29, 2017Mar 29, 2017