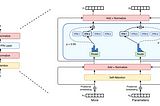
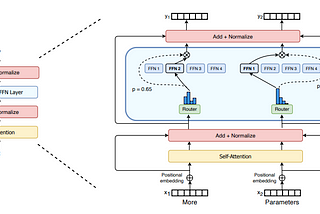
Anya TrivediScaling with SparsityHow Switch Transformers Scale to a Trillion Parameters using Sparsely-Activated Expert ModelsNov 28, 2021Nov 28, 2021