Keras ile Derin Öğrenme Modeli Oluşturma
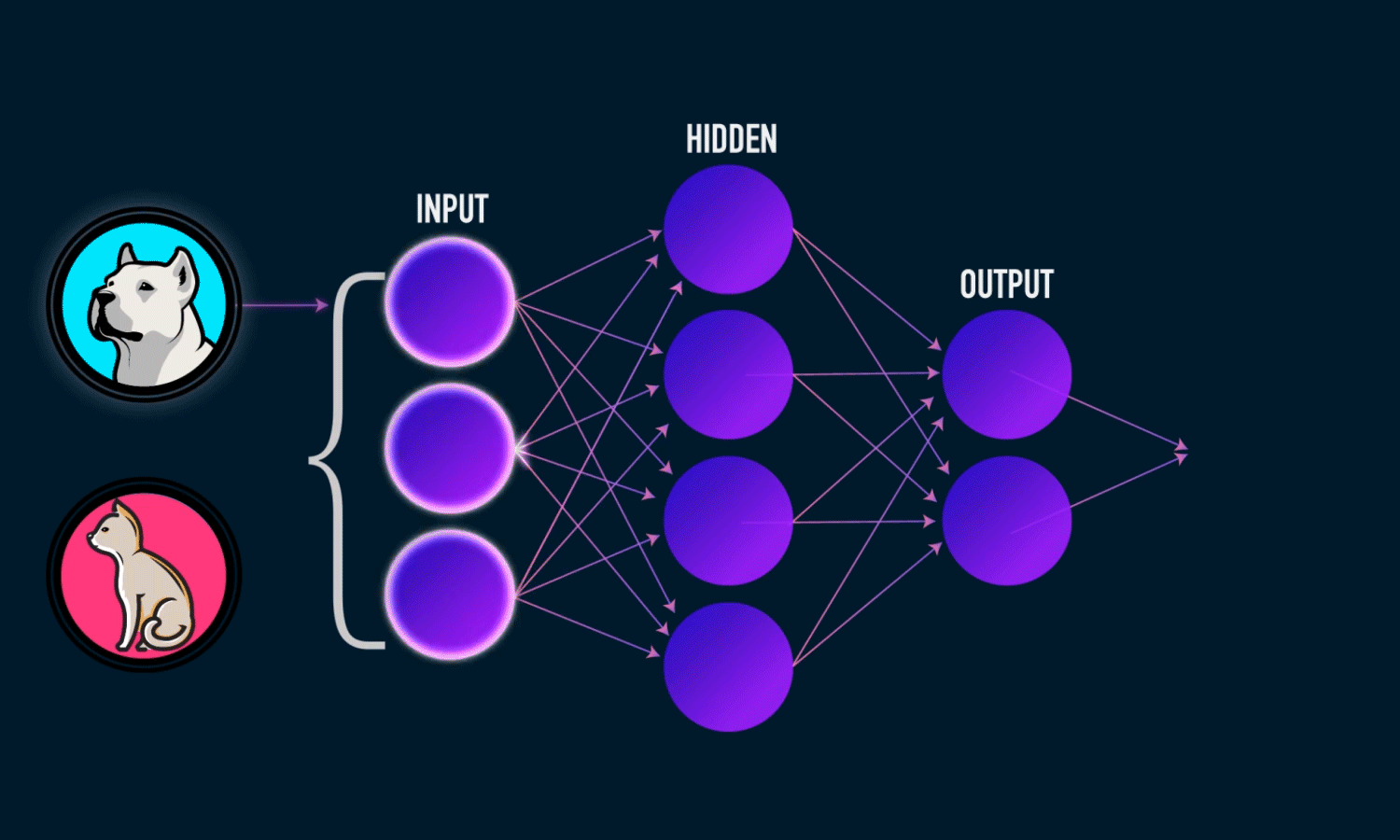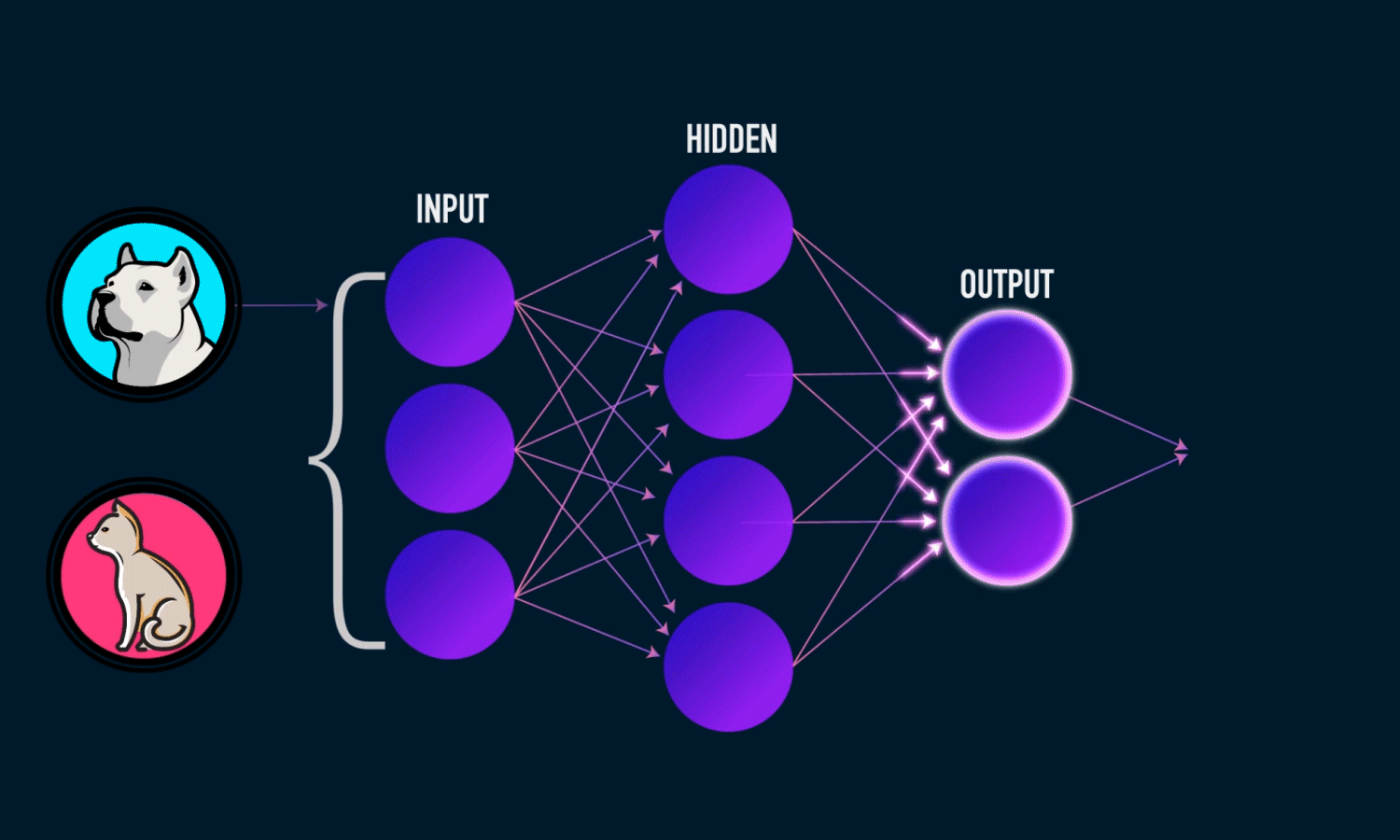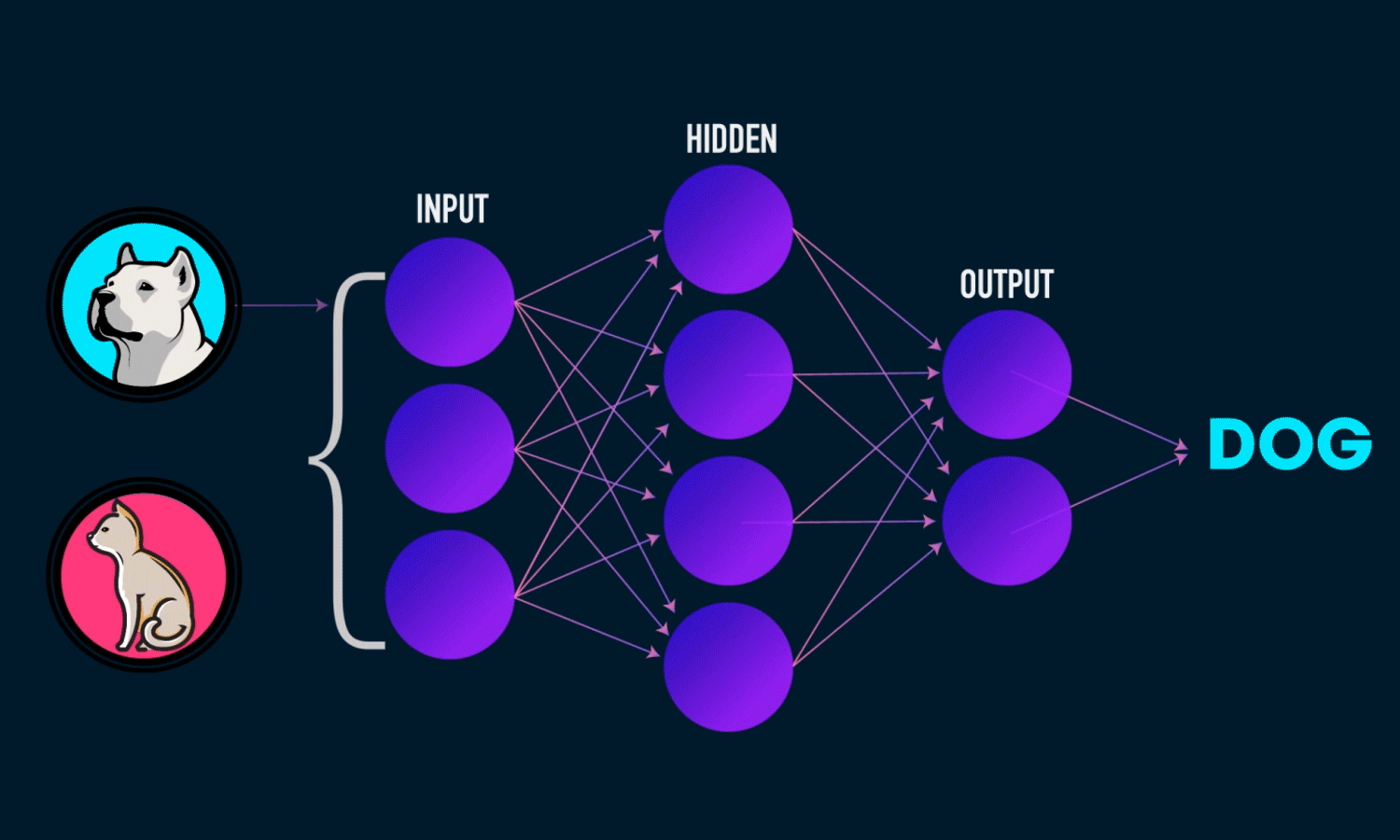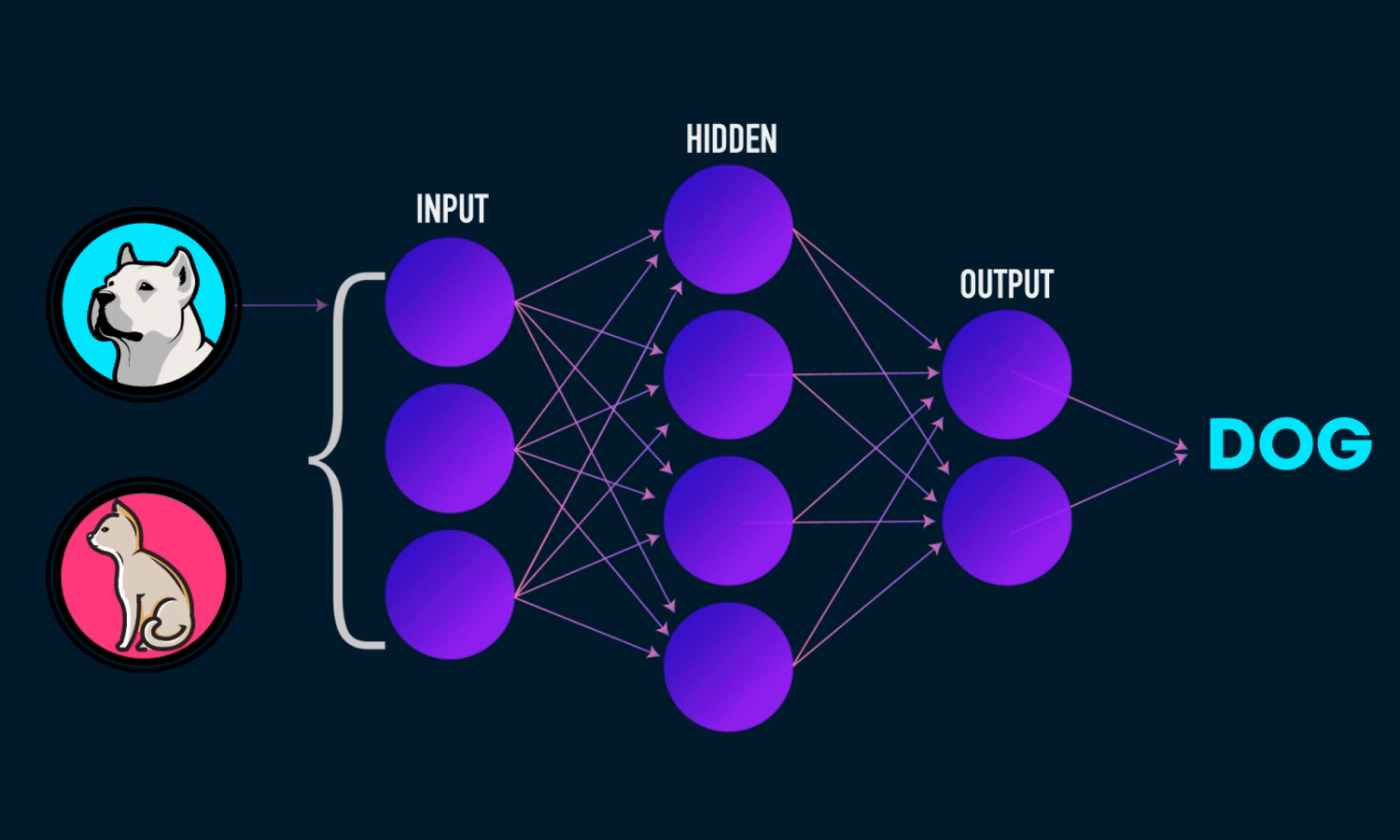
Derin öğrenme, makine öğreniminin giderek popülerleşen bir alt kümesidir. Derin öğrenme modelleri yapay sinir ağları kullanılarak inşa edilmiştir. Bir sinir ağı, gizli katmanlarda eğitim sırasında ayarlanan ağırlık değerleri ile eğitilecek girdi değerleri alır. Eğitim tamamlandıltan sonra modele verilecek yeni girdi değerinden bir tahmin çıkarır. Gizli katmanlardaki ağırlıklar, daha iyi tahminler yapmak ve modelin başarımını geliştirmek için eğitim back propagation (geri besleme) yöntemi ile ağorlıkları güncellenir.
Keras, Python’da yazılmış kullanıcı dostu bir sinir ağı kütüphanesidir. Bu derste, Keras kullanarak bir derin öğrenme modeli geliştireceğiz.
Not: Kullanacağımız veri setleri nispeten temizdir, bu nedenle verilerimizi modellemeye hazır hale getirmek için herhangi bir veri ön işlem gerçekleştirmeyeceğiz. Gelecekteki projelerde kullanacağınız veri kümeleri çok temiz olmayabilir — örneğin, değerleri eksik olabilir — bu nedenle daha doğru sonuçlar elde etmek için veri kümelerinizi değiştirmek için veri önişleme tekniklerini kullanmanız gerekebilir.
Bu veriseti beyin tümörlerinden çıkarılmış glcm(alt uzay metrikleri) ve diğer özelliklerden oluşmaktadır. Resimler .mat şeklinde verildiği için özellikler matlab ortamında çıkartılıp kerasta kullanmak için csv şeklinde kaydedilmiştir.
Verisetindeki diagnosis stünu hastalığın türünü diğer 16 stün bir resimden çıkarılan özellikleri belirler. Type sütunundaki 1=Glioma, 2=Meningioma ve 3=Patiutary tümör türünü göstermektedir.
Verilerin okunması
Sınıflandırma derin öğrenme modelimiz için ilk adım, girdi olarak kullanacağımız veriyi okumaktır. Bu örnekte, “Beyin Tümörü” veri kümesini kullanıyoruz. Başlamak için verileri okumak için Pandas kütüphanesini kullanacağız. Pandas üzerinde ayrıntıya girmeyeceğim, ancak veri bilimi ve makine öğrenimi konusunda daha fazla bilgi sahibi olmak istiyorsanız aşina olmanız gereken bir kütüphane olduğunu belirmek isterim.
‘Df’, veri çerçevesi anlamına gelir. Pandas, csv dosyasında bir veri çerçevesi olarak okur. ‘head ()’ işlevi, veri çerçevesinin ilk 5 satırını gösterecektir, böylece verilerin doğru bir şekilde okunup okunmadığını kontrol edebilir ve verilerin nasıl yapılandırıldığına dair ilk bir göz atabilirsiniz.
Veri kümesinin input ve target olarak ayrılması
Ardından, veri kümemizi girdiler (train_X) ve hedefimiz (train_y) olarak bölmemiz gerekiyor. Girişimiz “Type” hariç diğer sütunlar olacak, çünkü model eğitildikten sonra tahmin etmeye çalışacağımız değer type stünundaki tümör türleri olacak . Bu nedenle, “type” output yani çıkış olacaktır.
Veritabanımızdaki “type” sütununun dışındakileri “train_X” değişkeninde saklamak için pandas kütüphanesinin “drop” işlevini kullanacağız. Bu bizim giriş değerimiz olacak.
type sütununu hedef değişkenimize (train_y) ekleyelim.
Veri setinin eğitim ve test veri seti olarak ikiye bölünmesi
Toplamda 3049 adet verimiz var. Bu verilerin %15’ini test, geri kalan %85’ini eğitim verisi olarak ayıralım, bunun için sklearn kütüphanesinin train_test_split fonksiyonunu kullanacağım.
Bizim projemiz bir sınıflandırma projesi olduğundan dolayı çıktı olarak belirlediğimiz y_test ve X_test verilerinin 2 boyutlu olması gerekir fakat bizde bunlar tek boyutlu. bunun için one hot label şeklinde isimlendirilen yöntemi kullanmamız gerekir.
Kısaca tek bir stunda tutulan 1,1,1,1,…2,2,2,…3,3,3…3 şeklinde tutulan verileri
[[1,0,0],
[1,0,0],
…
[0,1,0],
[0,1,0],
…
[0,0,1],
[0,0,1],
…
[0,0,1]]
Şekline çevirmemiz gerekli.
Bu işlemiçin şu kadlar yeterli olacaktır.
Modelin oluşturulması
Ön hazırlık adımları tamam. Şimdi modeli oluşturalım.
Kullanacağımız model tipi sequential. Sequential, Keras’ta bir model oluşturmanın en kolay yoludur. Katman ile bir model katman oluşturmanıza izin verir. Her katmanın aşağıdaki katmanı gösteren ağırlıklara sahiptir.
Modelimize katman eklemek için ‘add ()’ işlevini kullanıyoruz. Bir girdi iki gizli katman ve bir çıkış katmanı ekleyeceğiz.
‘Dense’, katman türüdür. Dense, çoğu durumda çalışan standart bir katman türüdür. Yoğun bir katmanda, önceki katmandaki tüm düğümler mevcut katmandaki düğümlere bağlanır.
Giriş katmanında 16 düğüm yani nöron var. Bir katmandaki nöron sayısı yüzlerce veya binlerce olabilir. Her katmandaki düğüm sayısını arttırmak, model kapasitesini arttırdığı gibi modelin eğitim süresini ve diskte kapladığı alan artar bu durum istenmeyen bir durumdur. Bu sebepte ötürü optimum nöron ve gizli katman sayısı bulunulmaya çalışır. Kaç tane gizli katman olacağı hakkında net birşey söylemek mümkün değildir fakat küçük bir veriseti için arka arkaya onlarca veya yüzlerce katman eklemek faydadan ziyade zarar getir. Bir gizli katmanda kaç tane nöron olacağını kestirmek pek mümkün değildir fakat literatürde bu konu hakkında farklı yaklaşımlar mevcuttur, örneğin benimde kullandığım ve tavsiye ettiğim (giriş+çıkış)/2 formülünü tavsiye ederim. Ben birinci gizli katmanda (16+3)/2=9 tane nöron kullandım. İkinci gizli katmanı ise tamamen kendi isteğimle modelin performansını arttırmak için kullandımı söylemek isterim.
Bazı kaynaklarda gizli katmanlarda kullanılan nöron sayısının√(giriş+çıkış) formülü ile kullanılması tavsiye edilir. Seçim size ait
‘Aktivasyon katmanı nın ne anlama geldiğini ve nasıl çalıştığını daha önceki bu blog yazısında Non-linearity başlığı altıda paylaşmıştım. İsterseniz bir göz atın.
Kullanacağımız aktivasyon fonksiyonu ReLU veya Rectified Linear Activation. Bu aktivasyon fonksiyonu sıfırdan küçük olan değerleri sıfır olarak, sıfırdan büyük olan değerleri olduğu gibi alır. formül olarak f(x)=max(0,x) şeklinde yazabiliriz.
Batch normalization ve Dropout bir önceki blog yazısında paylaşıldığı için burada tekrar yazmak istemiyorum. Dilerseniz o yazıya bir göz atın.
Modelin Derlenmesi
Ardından, modelimizi derlememiz gerekiyor. Modelin derlenmesi model.compile() fonksiyonu ile yapılır. Bu fonksiyon optimizer, kayıp ve metrik olmak üzere üç parametre alır. Aslında birçok parametre alır fakat biz üç tanesini kullanacağız. Diğer parametreleri kerasın kendi sayfasında bulabilirsiniz.
Optimizer, öğrenme oranını kontrol eder. Optimizer olarak “adam” kullanıyoruz. Adam genellikle birçok durumda kullanmak için iyi bir optimizasyon algoritmasıdır. Adam algoritması, eğitim boyunca öğrenme oranını ayarlar.
Öğrenme oranı, model için optimal ağırlıkların ne kadar hızlı hesaplandığını belirler. Daha küçük bir öğrenme oranı daha kesin ve iyi ağırlıklara (belirli bir noktaya kadar) yol açabilir, bu modelin daha iyi öğrenmesi anlamına gelir ancak ağırlıkların hesaplanması için gereken süre daha uzun olacağından dolayı eğitim süresi uzayacaktır.
Kayıp fonksiyonumuz için ‘categorical_crossentropy’ kullanacağız. Bu, sınıflandırma problemleri için en yaygın kullanılan fonksiyon türüdür.
Eğitim sırasında modelin nasıl bir performans gösterdiğini yorumlamak için her bir epoch sonunda validation seti ile elde edilen doğruluk ve loss miktarını görmek için “accuracy” metriğini kullanırız.
Modelin Eğitilmesi
Şimdi modelimizi eğitelim. Eğitim için, modelimizdeki ‘fit ()’ işlevini aşağıdaki yedi parametre ile birlikte kullanacağız: eğitim verileri (X_train), hedef veriler (y_train), doğrulama seti(validation_data), aynı anda eğitilecek veri miktarı(batch_size), her bir epoch’ta verilerin yerlerinin değişmesi için suffle, eğitim sırasında çıktıları görebilmek için verbose ve veri setinin kaç kez model üzerinden geçerek eğitileceğini belirleyen epoch sayısı.
Doğrulama veriseti ile, eğitim sırasında modelimizin cross etropy ile hesaplanan doğrulama kaybını görebileceğiz yani eğitim sırasında model performansının test edilmesi için kullanılacağı anlamına gelir diyebiliriz.
Batch sayısı modelin eğitilmesi aşamasında aynı anda kaç adet verinin işleneceği anlamına gelir. Bizim modelimizde batch size=16 olarak ayarlandı. yani 16 adet veri aynı anda eğitime girecek daha sonra optimizaston fonksiyonu ile hata oranı hesaplanacak ve sonraki 16 adet veriye geçecek. Bu işlem tüm veriler işleninceye kadar devam eder. Tüm vriler işlendikten sonra bir sonraki epoch’a geçer. Epoch ile batch size karıştırılmamalıdır dikkat edin. Batch size’ın düşük olması data fazla optimizasyon hesaplaması gerektireceğinden eğitim süresi uzun olur. bu sayının büyük olması ise eğitim süresini nispeten kısa tutarken modelin performasını etkileyebilir. Bu sayı genellikler ikinin üssel katları yani 2,4,8,16,32… gibi sayıların olması tavsiye edilir.
Suffle boolean değer alır ve her bir epoch’tan önce verilerin yerlerinin değiştirilmesi için kullanılır. Eğitimin daha doğru olması için kullanılması tavsiye edilir.
Verbose 0,1 ve 2 değerlerinden birisini alır. 0 eğitim sırasında ekranda bir sonuç göstermezken 1 progres bar gibi anlık olarak güncellenen sonçları gösterir. 2 ise her bir epoch sonunda tek bir satır olarak çıktı verir.
Epoch sayısı, model eğitilirken verilerin modelden kaç kez geçiş yapacağını belirtir. Bu değerin küçük bir sayı olması eğitim süresini kısa tutarken modelin performansı tam gelişmemiş olabilirken büyük bir sayı olması ise eğitim süresi çok uzun olur ve model gelişimini çoktan tamamlamış olabilir. yani gereksiz eğitim yapılmış olabilir optimumm noktayı bulmakta zorlanabilirsiniz bunun için en iyi yöntem büyük bir sayı belirlenmesi ve modelin gelişimini tamamladığı noktada eğitimi durdurmaktır, buna early stopping deniyor. Ben bu yöntemi bu eyiğimde kullanmadım. dilerseniz siz küçük bir araştıma ile nasıl kullanıldığını öğreip kullanabilirsiniz.
Şimdi eğitilmiş olan modelin eğitim boyunca başarım oranını gösteren başarım grafiğini çizdirelim.
Yeni veriler ile tahmin yapmak
Bu modeli yeni verilerle ilgili tahminlerde bulunmak için kullanmak istiyorsak, model.predict () fonksiyonunu kullanmamız gerekir. girdi olarak test verilerinden istediğimiz bir tanesini seçip verebiliriz. Ben 1. satırda bulunan veriyi alıp tahminde bulunmasını istedim. Sonuç olarak %60 oranında meningioma tümörü çıktı. Bodelin başarı oranına göre gayet başarılı bir sonuş olduğunu söyeyebilirim.
Daha sonra bu çıktıları çubuk grafiği şeklinde göstermek istedim.
Tebrikler! Keras’ta derin bir öğrenme modeli oluşturdunuz! Tabi bu modelin başarım oranı pekteiyi değil. modelin performansını arttırmak için modelin ayarları ile oynamak, daha fazla katman veya nöron eklemek, verileri çoğaltmak veya daha güzel veriler seçmek gerekebilir.
Kodların tamamını github üzerinden indirebilirsiniz.
