Introducing Unibase DA++: A Web3 + AI Native On-chain DA Solution

We are thrilled to introduce Unibase, the first AI-native data availability (DA) and storage layer. It features high performance and infinite scalability, enabling anyone to build on-chain AI apps securely and cost-effectively.
In this article, we will cover:
- P1: Challenges Faced by Traditional AI in Data Storage and Economic Models
- P2: Unibase’s DA++ Solution
- P3: Unibase Architecture
- P4: Advantages of Unibase
- P5: Unibase Use Cases
P1: Challenges Faced by Traditional AI in Data Storage and Economic Models
Data Storage:
- Data Silos: Traditional AI applications rely on centralized data storage, making it difficult to integrate data from different sources.
- Data Privacy and Security: Centralized servers pose risks of data breaches and privacy violations.
- Data Authenticity and Credibility: High-quality data is crucial for training AI models, and traditional storage methods often fail to guarantee data authenticity and credibility.
Economic Model:
- Lack of Incentives: There is a lack of effective incentive mechanisms between data providers and model trainers, resulting in little motivation for data providers to share high-quality data.
- High Costs: The costs associated with AI training and storage are prohibitively high, especially with large data volumes.
- Resource Monopoly: Centralized platforms monopolize resources, making it difficult for small enterprises and individual developers to access fair resource allocation.
P2: Unibase’s DA++ Solution
To address these challenges, Unibase introduces the DA++ concept, providing a native on-chain DA solution from the perspectives of decentralized and trustworthy DA and economic models. Our goal is to create a global decentralized AI-native DA network that resolves data silos, ensures data privacy and security, and enhances data authenticity and credibility.
P3: Unibase Architecture
Unibase effectively tackles data storage challenges through three key features:
Comprehensive On-chain Verification:
- RS Coding Accuracy: Ensures data integrity through on-chain verification of Reed-Solomon coding accuracy.
- Data Availability: Verifies data availability over specific time periods on-chain, ensuring data persistence.
- Dual ZK Proof Aggregation: Reduces verification costs with fixed-size zero-knowledge proof aggregation.
- Optimistic Verification: Minimizes on-chain computational overhead by allowing offline verification and enabling any party to initiate on-chain verification challenges if discrepancies or missing proofs are detected.
High-performance Decentralized DA Network:
- High-speed Data Ingestion: Supports large-scale data ingestion at rates up to 100GB/s, meeting the data demands for AI model training.
- Efficient Offline Proof Generation: Achieves coding performance of 100MB/s, improving data processing efficiency.
- Minimal Online Verification Impact: Conducts challenges and verification only upon detecting erroneous proofs, ensuring smooth system operation.
Full-chain DA Abstraction:
- Support for ZK Verification Module Multi-chain Deployment: Provides native DA storage and on-chain verification capabilities for various L1 and L2 chains.
- Self-developed DA Account Abstraction: Aggregates Web3 multi-chain data and traditional Web2 social data.
- Real Data Assetization (RDA): Allows data in Unibase to be traded on-chain as real assets.
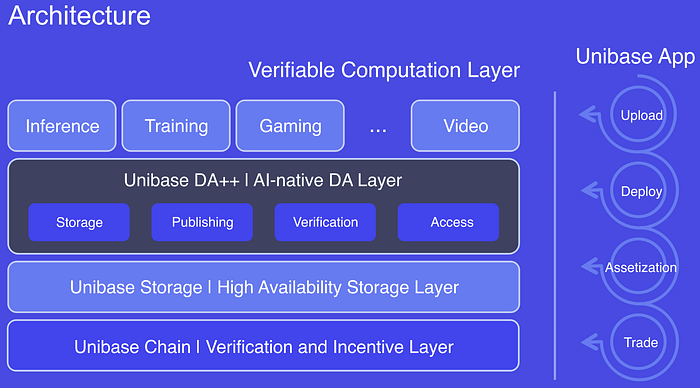
As shown in the diagram above, the architecture design of Unibase includes the following core components:
- Unibase DA++: A highly secure and scalable AI-native DA solution.
- Unibase Storage: A highly available and programmable storage network.
- Unibase Chain: An Ethereum Layer 2 solution based on the OP Stack.
P4: Advantages of Unibase
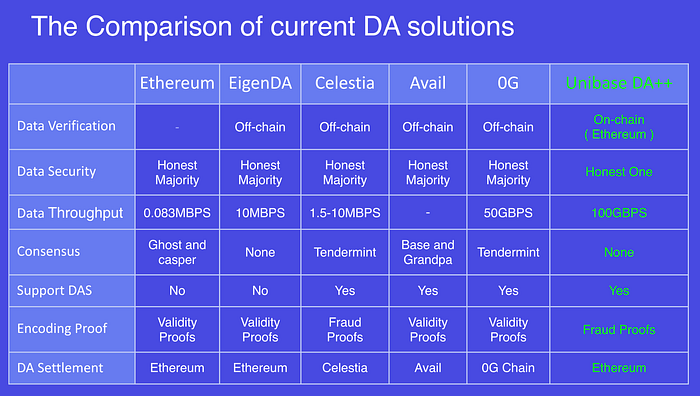
Compared to other DA solutions, Unibase, as the first on-chain DA solution, offers significant advantages in performance, security, and verification efficiency.
To incentivize nodes to provide higher quality data and a more efficient DA network, Unibase implements periodic rewards and storage node rewards. Periodic issuance rewards encourage node participation in data storage, with issuance amounts determined by the total data stored across the network. Storage nodes earn income by staking tokens to become storage nodes and storing data (user payments), alongside receiving additional rewards. Reward distribution is based on the total value of data stored by each node during the period, ensuring fair compensation.
P5: Unibase Use Cases

Unibase has already realized three significant AI applications:
- Decentralized AI Development Platform (Unibase App): Allows any developer to develop, deploy, and monetize their AI without permission.
- AI-driven Depin: Provides high-availability storage and verifiable inference services to ensure the intelligence and efficiency of devices (Smart Depin 2.0).
- Super AI Agent: A self-evolving AI with its own ID and wallet, capable of self-upgrading by earning income.
As Unibase Infra continues to improve, secure multi-chain data exchange and sharing will become possible, enhancing data integration and utilization efficiency. This will facilitate AI developers’ access to comprehensive data, promoting data circulation and utilization. With advancements in privacy computing technology, Unibase will also support privacy-preserving AI model training and inference, addressing data privacy and security issues.
Conclusion
Unibase’s economic model and decentralized storage technology effectively address the challenges faced by traditional AI in data storage and economic models. By leveraging a distributed storage network, token incentive mechanisms, and decentralized autonomous organization, Unibase enhances data utilization efficiency and security, creating a more equitable and incentivized economic ecosystem. This integration of AI and blockchain paves the way for the continued development of a decentralized intelligent ecosystem.
Unibase Chief Researcher, Richard
About Unibase
Unibase is the first AI-native data availability (DA) and storage layer designed to support large-scale trustless AI and DePIN native application capabilities with on-chain verification. Our cutting-edge technology ensures efficient and secure data flow, making data accessible when needed.







