Vitor TeixeirainTowards Data ScienceDelta Lake — Type wideningWhat is type widening and why does it matter?Apr 29Apr 29
Vitor TeixeirainTowards Data ScienceDelta Lake — Partitioning, Z-Order and Liquid ClusteringHow are different partitioning/clustering methods implemented in Delta? How do they work in practice?Nov 8, 20235Nov 8, 20235
Vitor TeixeirainTowards Data ScienceDelta Lake — Deletion VectorsHow are deletion vectors related to DML commands and how can they improve write performance?May 25, 20231May 25, 20231
Vitor TeixeirainTowards Data ScienceDelta Lake — Automatic Schema EvolutionWhat happens and what you can/can’t do when merging evolutive DataFramesMar 10, 2023Mar 10, 2023
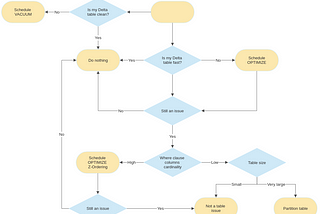
Vitor TeixeirainTowards Data ScienceDelta Lake— Keeping it fast and cleanEver wondered how to improve your Delta tables’ performance? Hands-on on how to keep Delta tables fast and clean.Feb 15, 20235Feb 15, 20235
Vitor TeixeirainTowards Data ScienceCustom Kafka Streaming metrics using Apache Spark Prometheus SinkA detailed tutorial on how to create and expose custom Kafka Consumer metrics in Apache Spark’s PrometheusServletFeb 2, 20231Feb 2, 20231