Twitter is a great place to gather data and assess various trends. Many analytics teams have used this source for their models.
In February 2023, Twitter set unrealistic prices for its API, giving away crumbs of data for big bucks. Some started using libraries such as snscrape, which used web public APIs. But in April 2023, Twitter closed that option as well — making search only for authorized accounts.
But data can still be collected in much the same way as before using the authorised account approach.
Introduction to twscrape
Released in May 2023, it is a tool for scraping data from tweets. It collects data such as user profiles, follower lists and follower lists, likes and retweets, as well as keyword searches.
Getting Started with twscrape
0. Requirements:
- Python 3.10 or higher
1. Installing twscrape:
pip install twscrapeOr development version with latest features:
pip install git+https://github.com/vladkens/twscrape.git2. Adding working accounts:
Twscape needs Twitter accounts to work. Each account has a rather small limit on the use of APIs.
Twscape needs Twitter accounts to work. Each account has a rather small limit on the use of APIs, after which some time is no way to make requests through that account. twscrape is designed to switch accounts when one of them is not available. In this way the data flow looks continuous to the user, although in fact the requests come from different accounts internally.
Accounts can be added in two ways, via software API or CLI command.
Let’s use the CLI command:
# twscrape add_accounts <file_path> <line_format>
# line_format should have "username", "password", "email", "email_password" tokens
# tokens delimeter should be same as an file
twscrape add_accounts accounts.txt username:password:email:email_passwordNote: It is possible to register a new account or buy on special websites, e.g. here.
You then have to go through the login procedure to get the tokens to request the API. It’s not a quick process, but it’s needed once after adding new accounts. Then the token is stored in the SQLite database and reused for subsequent queries.
twscrape login_accountsNote: Not all accounts can pass authorisation because of the antifraud system. You can try logging into these accounts again later.
Using twscrape
You can use twscape in two ways.
- Using an CLI (terminal) and receive JSON object
- Using Python API (usuful for custom data collection scripts)
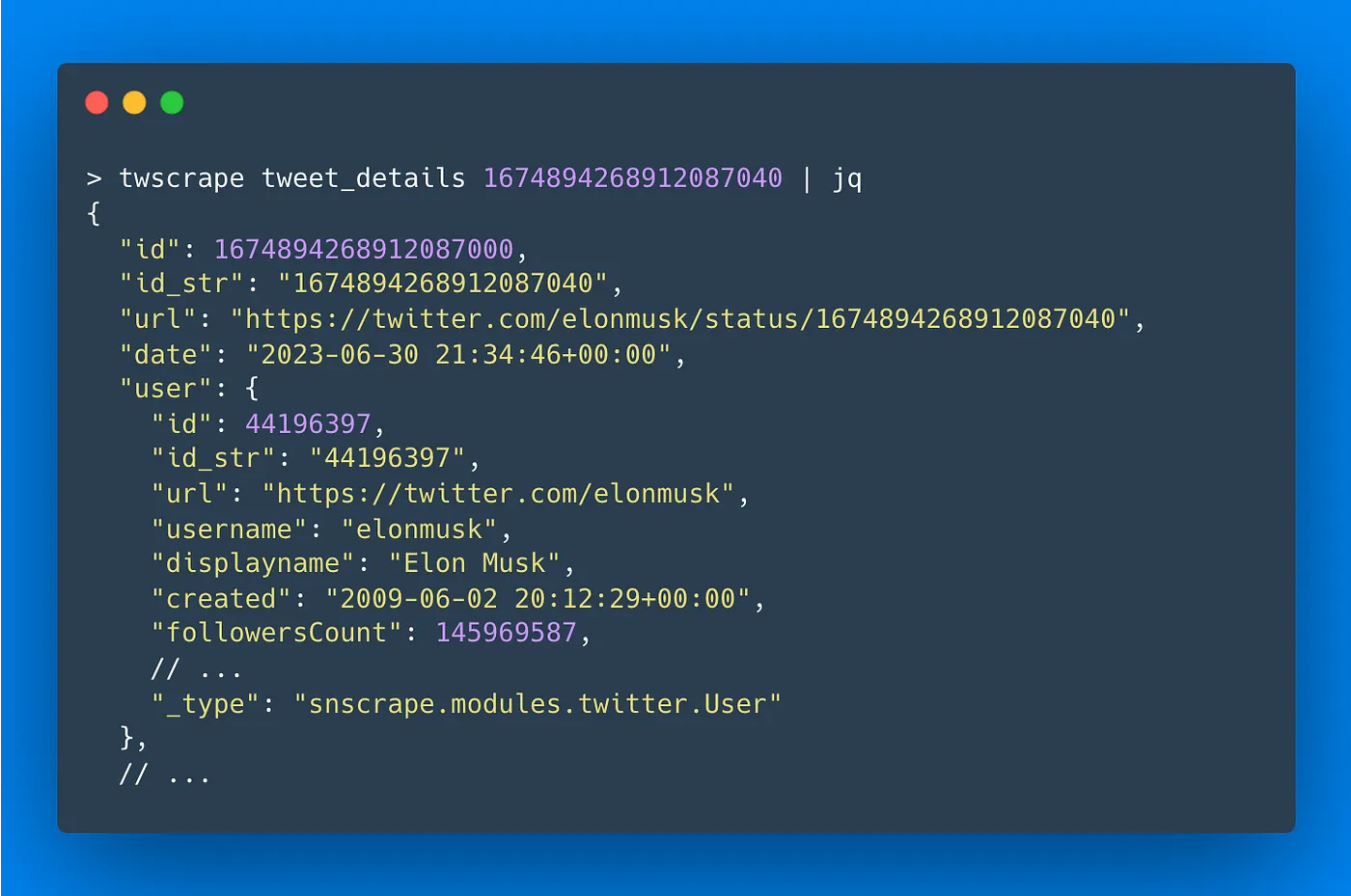
Lets get some tweet details from CLI:
twscrape tweet_details 1674894268912087040Result:
{
"id": 1674894268912087000,
"id_str": "1674894268912087040",
"url": "https://twitter.com/elonmusk/status/1674894268912087040",
"date": "2023-06-30 21:34:46+00:00",
"user": {
"id": 44196397,
"id_str": "44196397",
"url": "https://twitter.com/elonmusk",
"username": "elonmusk",
"displayname": "Elon Musk",
"created": "2009-06-02 20:12:29+00:00",
// ...
"_type": "snscrape.modules.twitter.User"
},
"lang": "en",
"rawContent": "This platform hit another all-time high in user-seconds last week"
// ...
}It’s that simple. The data format is almost the same as it was in snscrape. So if you already have some scripts to process the data, you can continue to use them without too much trouble.
Scrapping tweets from a text search query by Python API
Using the code below, we are scraping 5000 tweets between January 1, 2023, and May 31, 2023, with the keywords “elon musk”. Then printing in console tweet id, tweet author and content.
import asyncio
from twscrape import API, gather
from twscrape.logger import set_log_level
async def main():
api = API()
q = "elon musk since:2023-01-01 until:2023-05-31"
async for tweet in api.search(q, limit=5000):
print(tweet.id, tweet.user.username, tweet.rawContent)
if __name__ == "__main__":
asyncio.run(main())A general execution time for the entire code could be anywhere between 5 mins — 10 mins, depending on the number of tweets fetched by your username or keyword query.
Working with raw API reponses
If you don’t have enough data provided by Tweet & User objects or want to get more insights from the data, then there is an option to use raw Twitter responses. Each method has a _raw version that returns the original data.
import asyncio
from twscrape import API, gather
from twscrape.logger import set_log_level
async def main():
api = API()
q = "elon musk since:2023-01-01 until:2023-05-31"
async for rep in api.search_raw(q, limit=5000):
# rep is httpx.Response object
print(rep.status_code, rep.json())
if __name__ == "__main__":
asyncio.run(main())Or same from CLI:
twscrape search "elon musk since:2023-01-01 until:2023-05-31" --rawList of available functions
- search — just regular search by keywords
- tweet_details — information about specific tweet
- retweeters — list of users who retweet specific tweet
- favoriters — list of users who like specific tweet
- user_by_login — get user profile by login
- user_by_id — get user profile by id
- user_tweets — list of tweets of specific user (max 3200 tweets)
- user_tweets_and_replies — list of tweets and replies of specific user
- followers — list of followers of specific user
- following — list of users the user is subscribed to
- list_timeline — get all tweets of list
Found a bug or need new feature? Fill free to open an issues
More examples of use can be found on the project’s Github page:
That’s all for now. If this information was helpful to you, don’t forget to subscribe to receive notifications of new posts.
