Performing Sentimental Analysis on Twitter and Facebook (Part 2 — Data cleaning)
Bonjour! Ça va bien?
Welcome back, I assume that you now have a messy chunk of tweets in your Excel file (unstructured data), let’s clean ’em up!
This second part is lengthy, so I will break the codes up and explain their functions.
Objective: data cleaning, make a bag of words and filter out all non-sentimental items (“this”, “and”, “and”, “or”, and all the punctuation).
Libraries:
pandas: data manipulation and analysis.
nltk: natural language toolkit for text processing, mainly to get rid of all the stop-words like “and”, “this”, “that”, “or”, “i”, words that don’t have any sentimental value, unlike “great”, “bad”, and “awesome”, which we do keep.
string: to get rid of all the punctuations, because commas, periods, and exclamation points don’t present any emotion.
matplotlib: to make fancy graphs
Cool, now that you know how to use these tools, let’s get to #werk
Step 1: import pandas and the excel files
import pandas as pdhashtag1 = pd.read_excel(‘clarkU.xlsx’, names=[‘tweet’])
hashtag2 = pd.read_excel(‘clarkuniversity.xlsx’, names=[‘tweet’])
hashtag3 = pd.read_excel(‘ClarkUcapitalC.xlsx’, names = [‘tweet’])
hashtag4 = pd.read_excel(‘ClarkUniversity both CU capitalized.xlsx’, names = [‘tweet’])
Explanation:
So I found that there are 4 hashtags that people use the most when they tweet about Clark University: #ClarkUniversity, #ClarkU, #clarkuniversity, and #clarku. I have tried #cougar (our mascot), or #clarkie (how we call ourselves), both didn’t make the cut since there are so many irrelevant results.
I copied all the tweets from these 4 hashtags to 4 Excel files, then I used pandas to read them into Jupyter Notebook. There will be 2 columns in each Excel file, the first column is the ID, the second one I named “tweet”. Now we need to convert these 4 Excel files into pandas dataframes so we can mess around with ’em (you cannot use Python code on Excel files).
hashtag1 = pd.DataFrame(hashtag1)
hashtag2 = pd.DataFrame(hashtag2)
hashtag3 = pd.DataFrame(hashtag3)
hashtag4 = pd.DataFrame(hashtag4)See how I am using pandas to work with the data?
Sweet, now we have 4 dataframes. If you call one out, it will look like this:

Now we will combine (concatenate) all these dataframes together.
frames = [hashtag1,hashtag2,hashtag3,hashtag4]df = pd.concat(frames)
You will have to put all the dataframes into a list [] in order to concatenate them. Now I have close to 3000 tweets.

nltk has a list of stopwords, and string has a list of punctuations. You can see them by typing:
stopwords.words(‘english’)
string.punctuationWhich you should get something like this:
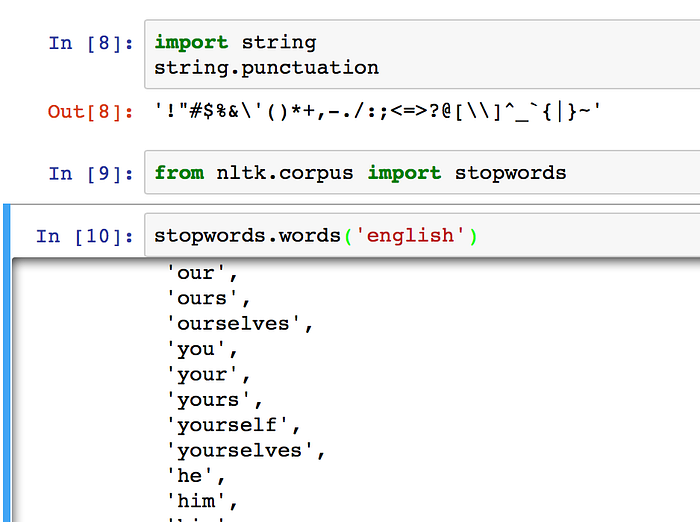
These words and punctuation don’t really say anything about people’ emotions, so we need to get rid of them if they are in the tweets.
def text_processing(line):
nopunc = [char for char in line if char not in string.punctuation]
nopunc = ‘’.join(nopunc)
return [word for word in nopunc.split() if word.lower() not in
stopwords.words(‘english’)]good_words = df[‘tweet’].apply(text_processing)
This part is a bit complicated. Here we have a function named text_processing, and we are processing lines/tweets. You can name them anything. Ex: bake(pizza). A line/pizza is a input, and we process/bake it. At this point, this is just a raw function. Think of it as y = ax + b. Now we do something with it.
nopunc = [char for char in line if char not in string.punctuation]
This is a for loop in Python, and it basically says: for character in line, if character is not in the punctuation list, take it.
So if I have a line: “Hi! My name is Hung “William” Mai, and I am from Vietnam.” This “sub-function” will take everything that is not a punctation and put them in a list.
So you should have nopunc = [Hi, My, name, is, Hung, William, Mai, and, I, am, from, Vietnam]. All the punctuations were deleted, and you are left with a list of words.
nopunc = ‘’.join(nopunc)
return [word for word in nopunc.split() if word.lower() not in
stopwords.words(‘english’)]Now that we have a list with all the elements separated by a comma, we would want to put them all again to be processed/joined again so that it can be processed with another sub-function to get rid of all the unimportant words.
From “Hi My name is Hung William Mai and I am from Vietnam”, we would get “Hi name Hung William Mai Vietnam”, then a list that has [Hi, name, Hung, William, Mai, Vietnam].
In general, we only take what we need.
good_words = df[‘tweet’].apply(text_processing)Then I applied this function to the “tweet” column of my dataframe, which I called df. After the function is applied to df, df will change, and I call this new/modified dataframe good_words.
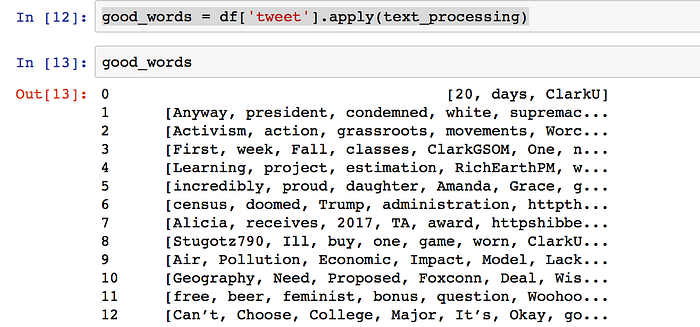
So now the rows of data have become lists of words. I wanted the words to look uniform, so I will “de-capitalize” them.
flat_list = [item for sublist in good_words for item in sublist]lower_list = [word.lower() for word in flat_list]
What does flat_list mean?
As you can see, we have a collection of broken-down-to-words tweets, or a bunch of lists within a list.
This is the big list, with 12 items:

This is a sublist (a list within a list).
flat_list = [item for sublist in good_words for item in sublist]It’s saying:
for sublist in good_words:
for item in sublist:
return item
for sublists within the big list, take all the items within these sublists and put all these words into a bag-of-words called flat_list. Then you make all of them lower-cased.
lower_list = [word.lower() for word in flat_list]It’s saying:
for word in flat_list:
return word.lower()
Pretty cool right?
We went from this:
… to this:
This is the end of part 2 on cleaning data. I hope the explanations have been easy to follow. In part 3 we will use clean up the data further and do sentimental analysis on a special web platform and data visualization on Tableau.

