Sparkplug, the new lightning-fast V8 baseline JavaScript compiler

Wikipedia, “Spark plug”:
A spark plug (sometimes, in British English, a sparking plug, and, colloquially, a plug) is a device for delivering electric current from an ignition system to the combustion chamber of a spark-ignition engine to ignite the compressed fuel/air mixture by an electric spark, while containing combustion pressure within the engine.
You must be asking yourself what’s the connection between a spark plug and the compiler. The thing is that they’re both fast as lightning and they’re starting the process! But let’s get back to the moment when I started my compilers’ research.
Let the story begin
When I was refreshing my knowledge about the way V8 JavaScript compilers work, I ran into something interesting. It was a new non-optimising compiler that allows the V8 engine to start quickly and increases its real-life performance by 5–15%. This story I’m going to tell you will be about the combination of modern and old compilers. Also, l’ll do the mid-tier compiler investigation and explain why Full-Codegen (old non-optimising baseline compiler) is dead.
What we had before: the history of JavaScript V8 compilers
A long-long time ago, the JavaScript V8 compiler pipeline had a way different structure. It consisted of two different compilers and they did their job:
- Full-codegen — a very fast compiler that produced dirty and slow machine code;
- Crankshaft — a JIT optimising compiler.
Standards changed, technical debt grew, and mobile phones turned out to be more popular than desktops. Eventually, Chrome’s V8 was consuming too much RAM and failed to optimise both: basic old JavaScript stuff (like try, catch, and finally blocks) and new things from ES2015.
With the release of the V8 5.9 version, we got a new execution pipeline. The idea came out of the mobile-first paradigm with the focus on reducing V8’s memory consumption, meaning not only the visual design but also software architecture to suit mobile phones. It was about optimising memory and CPU usage on devices with a small amount of memory and lack of power, like Android. Also, the old pipeline had some gaps, like bad (non-layered, outdated) architecture that had to be filled in.
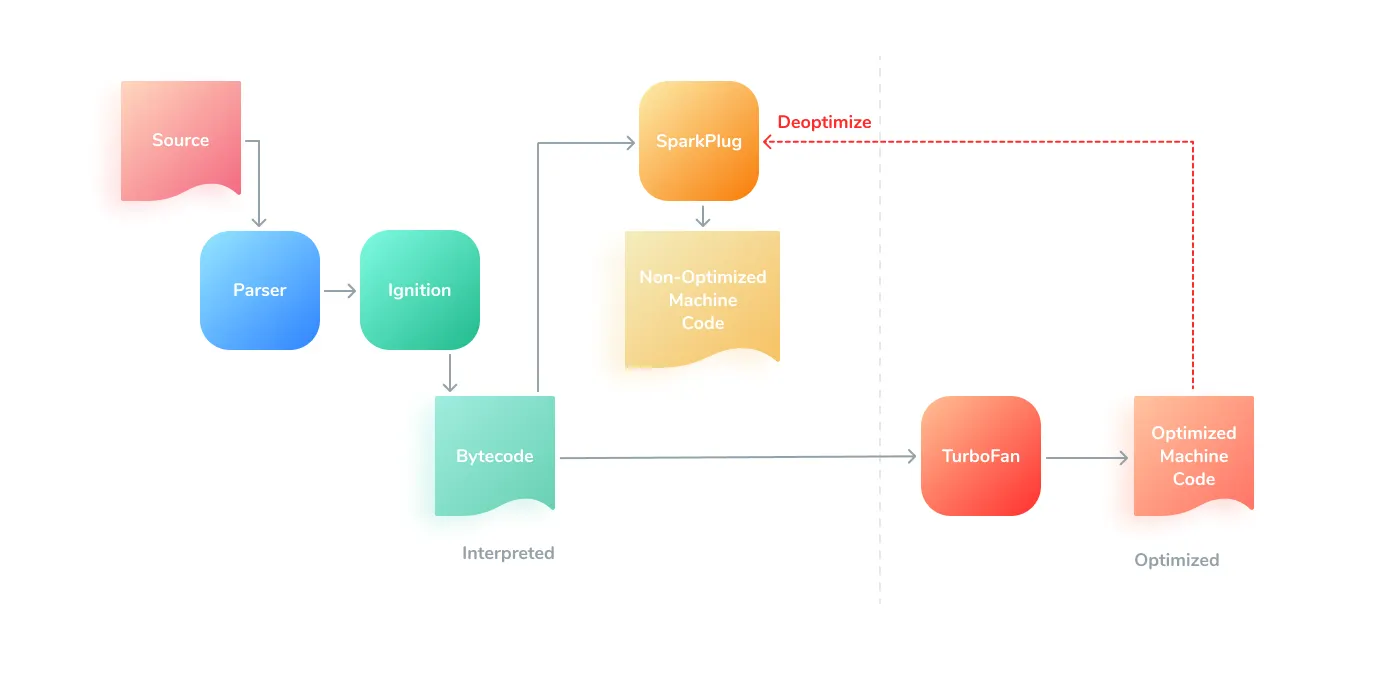
The new pipeline simplified and improved the deoptimisation mechanism which is necessary for V8’s adaptive optimisation, with fewer errors and roll-backs to non-optimised code.
The big simplification is that new Turbofan compiler doesn’t have to reconstruct Full-codegen stack frames, with their implicit stack state and operands. But instead it reconstructs Ignition stack frames with explicit bytecode register values.
Technopedia, “Stack Frame”:
A stack frame is a memory management technique used in some programming languages for generating and eliminating temporary variables. In other words, it can be considered the collection of all information on the stack pertaining to a subprogram call. Stack frames are only existent during the runtime process. Stack frames help programming languages in supporting recursive functionality for subroutines.
A stack frame also known as an activation frame or activation record.
The new execution pipeline involved the following:
Hm… Something is missing there. Where is good old non-optimised code?
The V8 team experimented with the combination of Ignition and TurboFan, Full-codegen, and Crankshaft.
There was actually a mode where TurboFan compiled from AST for tier-up from Full-Codegen. But, while it was in development, it still generated worse code than Crankshaft on things that Crankshaft still worked for, so the V8 team had this great situation with the “Frankenpipeline” where Ignition could tier-up to Full-Codegen.
Then it was dependent on what functionality the function had: this would tier up to either Crankshaft or to TurboFan, and TurboFan had to support both compiling from Ignition bytecode, or from Full-Codegen/AST. This had a lot of additional complexity in maintaining consistency between Ignition and FCG, e.g. labelling async/await suspension points or potential deoptimisation locations.
Sounds terrible!

This combination was called “Frankenpipeline” and even became part of the production of the V8 version. Here you can get more info from 2016 pipeline with baseline compilation.
Ross McIlroy. “Firing up the Ignition interpreter”:
The Ignition interpreter uses TurboFan’s low-level, architecture-independent macro-assembly instructions to generate bytecode handlers for each opcode. TurboFan compiles these instructions to the target architecture, performing low-level instruction selection and machine register allocation in the process.

The interpreter itself consists of a set of bytecode handler code snippets, each of which handles a specific bytecode and dispatches to the handler for the next bytecode. These bytecode handlers are written in a high level, machine architecture agnostic form of assembly code, as implemented by the CodeStubAssembler class and compiled by Turbofan (or Sparkplug, but we’ll talk a little bit later about it).
To compile a function to bytecode, the JavaScript code is parsed to generate its AST (Abstract Syntax Tree). The BytecodeGenerator walks this AST and generates bytecode for each of the AST nodes as appropriate.
TurboFan has a layered architecture. It is much more general and has a smaller codebase with abstraction layers and without spaghetti code, allows for easy improvements (for new ES standards), and it’s simpler to add machine-specific code generators there (like a code for IBM, ARM, Intel architectures). The main idea of TurboFan is sea-of-nodes intermediate representation (IR). TurboFan takes instructions from Ignition, optimises them, and produces platform-specific machine code.
Crankshaft had a more specialised JS-specific IR that stayed pretty high-level, and it stored a CFG (control-flow graph) with explicit operation ordering, which is what made it fast to compile but also hard to add new functionality.
Turbofan has more layers of IR to move from JS operations through abstract operations to machine operations, and the Sea-of-Nodes allows free re-scheduling without being that tightly coupled to the control flow, but that genericity comes which runtime cost.
Find more about the idea behind from the “Launching Ignition and TurboFan” article
Also check the Ignition interpreter article, and the V8 Ignition and TurboFan story.
Do we always need the optimised result?
Optimisation is a process that requires time and computing power. Thus it’s not worth the effort for short JavaScript sessions like loading websites or using some command-line tools. As bytecode decoding in TurboFan is way too expensive and time-consuming for such cases, you can increase performance and speed up the application start only by removing the optimisation step (or simplifying it).
The idea of a V8 mid-tier compiler came to the V8 Core Team some years ago (~2016). They tried to implement prototypes at the V8 Mobile London Hackathon when the team experimented with including it in the compilation process between Ignition and TurboFan.
They developed four potential implementations:
- SparkPlug — a single-pass non-optimising baseline compiler;
- SparkPlugOpt — a single-pass baseline compiler with speculative optimisation of certain monomorphic operations;
- TurboFan-Lite — TurboFan with inlining disabled;
- TurboProp — an optimising compiler that uses a cut-down variant of the TurboFan pipeline with an attempt to approximate the impact of a different backend for TurboFan.
You can learn more about the idea of Mid-Tier Compiler from the analysis document.
And, after some investigation, the V8 team decided to implement TurboProp. TurboProp is a faster and lighter version of TurboFan with some heavy optimisations turned off. It’s a mid-tier optimiser. But they decided to take a different path because, in some cases, optimisations are not at all needed. The solution is right there, in the V8’s source code, and there is a flag to turn it on:
DEFINE_BOOL(turboprop, false, "enable experimental turboprop mid-tier compiler")Or it‘s even possible to replace TurboFan with TurboProp completely:
DEFINE_BOOL(
turboprop_as_toptier, false,
"enable experimental turboprop compiler without further tierup to turbofan")Find more V8 flags here.
It seems that Ignition and TurboFan are on the different sides of the compilation-time-to-quality spectrum. By test results, TurboProp was slightly closer to the TurboFan full-powered optimiser.
So, the choice was made not to waste time optimising functions that aren’t actually hot (meaning not optimising a potential hot spot when it’s not hot yet), or even waste time on deoptimisation of optimised functions.
Yes, deoptimisation happens for example when you’re changing a variable that was constant for a long time in your code, or using 32/64-bit doubles instead of 31/32-bit integers, called Smi (depending on 32/64-bit platform). Check an interesting deep-diving article.
Wikipedia. “Hot spot (computer programming)”:
A hot spot in computer science is usually defined as a region of a computer program where a high proportion of executed instructions occur or where most time is spent during the program’s execution (not necessarily the same thing since some instructions are faster than others).
The team reduced this huge gap in compilation-time-to-quality spectrum with a simple, fast, non-optimising compiler that can quickly and cheaply run through the bytecode, spitting machine code out of it.
Did they take a step back to Full-codegen? — No (and Yes, a little bit)
Anyway, now it’s time for us to meet a new baseline compiler — Sparkplug!
An old-new step — Sparkplug, a non-optimising compiler
Sparkplug is a transpiler/compiler that converts Ignition bytecode into machine code shifting JS code from running in a VM/emulator to running natively.
We can describe Sparkplug as an interpreter accelerator which compiles bytecode in the simplest way possible: converts it into a series of builtin calls mixed with control flow.
Builtins in V8 stand for chunks of code that are executable by the machine/VM at runtime. Commonly you can implement the functions of builtin objects (such as RegExp or Promise), but builtins can also be used to provide different internal functionality. Learn more from the CodeStubAssembler builtins document.
Sparkplug compiles from bytecode (created by Ignition, as we found out before) by iterating bytecode and emitting machine code for each bytecode as visited/flagged.
Control flow: simple operations (reference comparison or typeof) can be done directly. More complex operations (e.g. arithmetic) are redirected to builtins. This makes Sparkplug a VERY fast compiler. Most of the work is already done by Ignition, so Sparkplug can go through the generated bytecode and do its job.
Sparkplug doesn’t generate any intermediate representation (IR) like most compilers do. Instead, it compiles directly to machine code in a single linear pass over the bytecode, emitting code that matches the execution of that bytecode. The entire compiler is a switch statement inside a for loop, dispatching to fixed per-bytecode machine code generation functions.
“Sparkplug — a non-optimizing JavaScript compiler”:
The lack of IR (Intermediate representation) means that the compiler has limited optimization opportunities, beyond very local peephole optimizations. It also means that we have to port the entire implementation separately to each architecture we support, since there’s no intermediate architecture-independent stage. But, it turns out that neither of these is a problem: a fast compiler is a simple compiler, so the code is pretty easy to port; and Sparkplug doesn’t need to do heavy optimization, since we have a great optimizing compiler later on in the pipeline anyway.
Technically, we currently do two passes over the bytecode — one to discover loops, and a second one to generate the actual code. We’re planning on getting rid of the first one eventually though.
Additionally, Sparkplug maintains the interpreter’s stack layout, so the on-stack replacement stays simple.
As for the Sparkplug’s stack frames, they’re almost 1:1 compatible with the Ignition stack frames. Find more about the way Sparkplug uses stack frames from the Sparkplug article.
Performance
Sparkplug does its job really-really fast. It’s 10–1000 times faster than TurboFan/TurboProp. It comes right after the bytecode compilation (the Ignition phase). And it’s tested both on Octane and real-life examples (facebook.com test). Also, the Sparkplug machine code is 5–6 times larger than Ignition bytecode. Here’s more about performance and more about benchmarks.
Haven’t V8 used a fast compiler before, which is Full-codegen? — Yes, and it was removed in favor of Ignition.
The big difference between Full-codegen and Sparkplug is that the last one compiles from bytecode, not from source or AST.
Back in the Full-codegen days, the Crankshaft had to re-parse the source code to AST and compile from there. Or even worse, to be able to deoptimise code back to Full-codegen, it had to kind of replay back Full-codegen compilation to get the deoptimised stack frame right.
Yes, Turbofan deoptimises to Sparkplug now, not to Ignition.
In V8 9.3 they introduced the batch compilation. I’ll tell about the batch compilation below.
Have Sparkplug gone live?
It’s a “yes” for V8 9.2.x-9.4.x
#if V8_TARGET_ARCH_IA32 || V8_TARGET_ARCH_X64 || V8_TARGET_ARCH_ARM64 || \
V8_TARGET_ARCH_ARM || V8_TARGET_ARCH_RISCV64 || V8_TARGET_ARCH_MIPS64 || \
V8_TARGET_ARCH_MIPS
#define ENABLE_SPARKPLUG trueYes, but not for all architectures. Nevertheless, most desktop architectures have true flag:
But it’s still disabled on Android.
#if ENABLE_SPARKPLUG && !defined(ANDROID)
// Enable Sparkplug by default on desktop-only.
#define ENABLE_SPARKPLUG_BY_DEFAULT true
#else
#define ENABLE_SPARKPLUG_BY_DEFAULT false
#endifAnd more code. It turns on Sparkplug for special conditions, baseline.cc file:
If Sparkplug is enabled for the platform, it will be used to compile code by 4kb batches (packages). It was introduced in V8 9.3: instead of compiling each function individually, it compiles multiple functions in a batch. Yes, for security reasons, V8 write-protects the code memory that it generates, requiring it to flip permissions between writable (during compilation) and executable (and this is an expensive operation and can be a bottleneck).
This amortises the cost of flipping memory page permissions by doing it only once per batch. The medium compilation time (Ignition + Sparkplug) is reduced to 44%.
Read more on this topic from the blog, and find more flags on GitHub.
Here’s an interesting piece code from runtime-internal.cc, it is about batch compilation and marking code for optimisations:
So, at first, the V8 is compiling code using Sparkplug, then it is marking the code for optimisation, and the time for Turbofan comes!
Summary
Now, V8 has a new fast non-optimising mid-tier compiler. It’s enabled in desktop Chrome for many architectures. Even though it is still disabled on Android (V8 9.4.x). What’s the most important is that having a mid-tier compiler increased the overall real-world performance by 5–15%.
Probably, in the near future, we’ll see another mid-tier compiler since the team has an internal document named “The Case For Four Tiers”. It means, we’ll meet a new step in the compilation process called TurboProp.
Also, I want to mention SpiderMonkey here, the Firefox JavaScript Engine. It has a Baseline Interpreter as a mid-tier step in JS compilation. I must say, SpiderMonkey does a really good job there! And you can find out more from the article.
And JavaScriptCore, the Safari’s JS compiler, has a baseline compiler too. Of course, you can read more here about the speculative compilation in JavaScriptCore!
Let’s stay tuned! From my side, I promise to keep you posted on the new developments regarding the V8 JS engine.
Ping me on Twitter if you have any questions or thoughts!
Or LinkedIn
Useful links:
– Mid-tier Compiler Investigation
– Ignition doc file: bytecode generation (You need it to understand Sparkplug)
Special thanks to
Diana Volodchenko for all illustrations to this article!
And to
Leszek Swirski, V8 contributor for some insides, review and ideas!
