Building Multi-Layer GRU from Scratch
In this article, We are making a Multi-layer GRU from scratch for tasks like discussed in RNN and LSTM article. Referring to them you can model them in any way you want.
First here is the code for a single GRU Cell in Pytorch:
This choice of standard deviation (std) for weight initialization is based on mathematical considerations and is known as “Xavier initialization”. There are good reasons for this approach, one of them is Variance Preservation.
Variance preservation: The goal is to maintain the variance of activations and gradients as they flow through the network. This helps prevent the vanishing or exploding gradient problem.
This initialization helps ensure that the input to each neuron has unit variance, which is particularly important at the start of training. It helps the network converge faster and avoid issues with very large or very small activations.
Need for non-linearity
The non-linearity is crucial because:
- It allows the GRU to learn and represent complex, non-linear relationships in the data.
- Without it, the GRU would only be capable of learning linear combinations of its inputs.
- It helps in preventing the vanishing/exploding gradient problem, especially when using tanh.
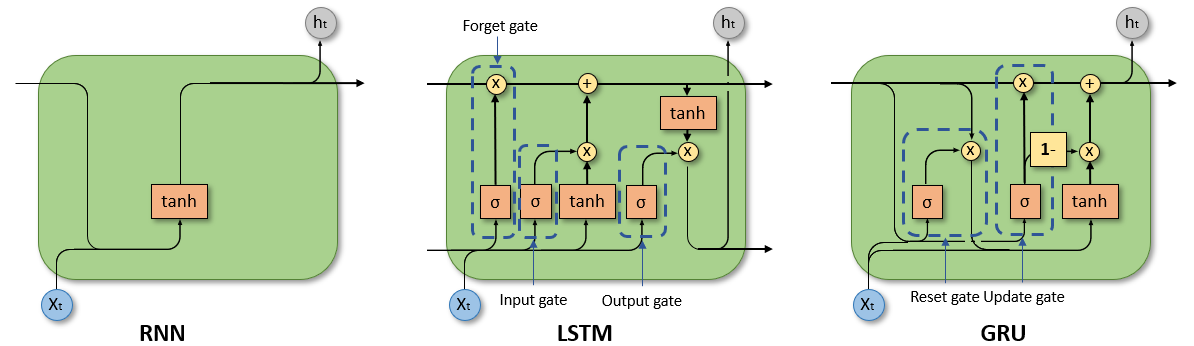
Here is a flowchart showing how Data goes through a multi-layer GRU.


Note : Point-Wise Multiplication is just multiplying respective elements. Its not Matrix Multiplication.
Will publish similar article for Transformers soon…
Thank you for reading, I hope this article keeps you updated.

{kind=link}