Using LangChain ReAct Agents with Qdrant and Llama3 for Intelligent Information Retrieval

Introduction
In the world of natural language processing (NLP) and information retrieval, combining cutting-edge tools and models is crucial for delivering efficient query handling and insightful responses. This tutorial explores how three powerful technologies — LangChain’s ReAct Agents, the Qdrant Vector Database, and the Llama3 large language model (LLM) from the Groq endpoint — can work together to supercharge intelligent information retrieval systems.
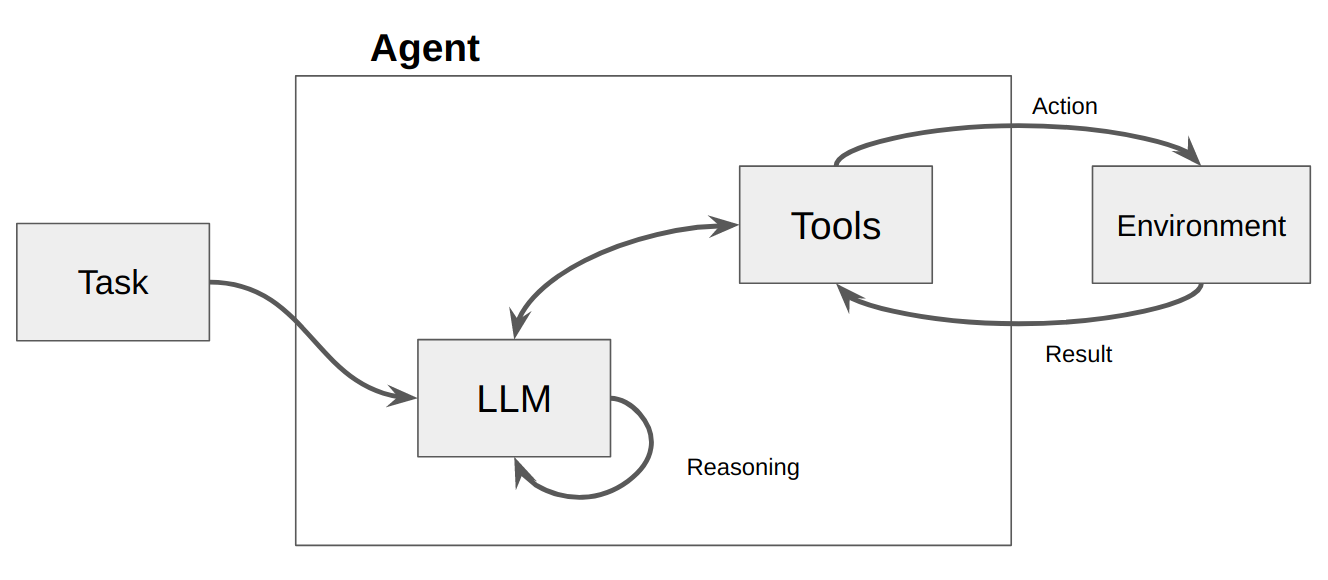
Fact: Agents are nothing but LLMs with a complex prompt.

The documents I will be referring to in this article include:
- https://policies.google.com/terms?hl=en-US
- https://openai.com/policies/terms-of-use/
- https://www.facebook.com/legal/terms?paipv=0&eav=AfYU7-7Cf-zij8FiJxMbZUIw3eF6mj9sXRTd01_PiZSBjEuKOE3VHDVPzP31EkYsVZk&_rdr
- https://students.ucsd.edu/_files/sls/handbook/SLSHandbook-Contract_Law.pdf
Let’s Code
For the code, refer to this GitHub link: https://github.com/yash9439/Qdrant-LangChainReActAgents-Groq
Setting Up the Environment
These are the necessary packages we will use.
Tech Used:
- PyPDF2 -> Extracting Text from PDFs
- Qdrant -> Using Qdrant as Vector Database
- LangChain -> For Agents’ Creation and Text Processing
- ChatGroq -> For Providing API Endpoint for LLMs by Groq for Lightning Fast Inference
- Gradio -> UI for the Chat Interface
import os
from PyPDF2 import PdfReader
import numpy as np
from langchain_community.vectorstores import Qdrant
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
import numpy as np
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import Tool
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.llms import OpenAI
from langchain_groq import ChatGroq
import gradio as gr
from fuzzywuzzy import fuzz
from fuzzywuzzy import processWe need Groq API for inference. Right now they are free in beta version with a rate limit. Link: https://console.groq.com/keys
You can use Qdrant locally or Qdrant Cloud. Its API is also free and you can access it here: https://cloud.qdrant.io/login
Data Preparation
Once the environment is set up, the next step is Data Extraction. We start by extracting text from PDF documents stored in a specified directory. The extracted text is then processed and stored for further use.
def extract_text_from_pdf(pdf_path):
"""
Extract text content from a PDF file.
Args:
- pdf_path (str): The path to the PDF file.
Returns:
- str: The extracted text content.
"""
reader = PdfReader(pdf_path)
extracted_text = ""
for page in reader.pages:
extracted_text += page.extract_text()
return extracted_text
def extract_text_from_pdfs_in_directory(directory):
"""
Extract text content from all PDF files in a directory and save as text files.
Args:
- directory (str): The path to the directory containing PDF files.
"""
for filename in os.listdir(directory):
if filename.endswith(".pdf"):
pdf_path = os.path.join(directory, filename)
extracted_text = extract_text_from_pdf(pdf_path)
txt_filename = os.path.splitext(filename)[0] + ".txt"
txt_filepath = os.path.join(directory, txt_filename)
with open(txt_filepath, "w") as txt_file:
txt_file.write(extracted_text)
# Specify the directory containing PDF files
directory_path = "Docs/"
# Extract text from PDFs in the directory and save as text files
extract_text_from_pdfs_in_directory(directory_path)Storing the document’s data file wise:
directory_path = "Docs"
txt_files = [file for file in os.listdir(directory_path) if file.endswith('.txt')]
all_documents = {}
for txt_file in txt_files:
loader = TextLoader(os.path.join(directory_path, txt_file))
documents = loader.load()
# Step 2: Split documents into chunks and add metadata
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100, separator="\n")
docs = text_splitter.split_documents(documents)
for doc in docs:
doc.metadata["source"] = txt_file # Add source metadata
all_documents[txt_file] = docs
Storing the Data in Qdrant Vector DB Using Custom Embeddings
The Qdrant Vector Database provides powerful capabilities for efficient storage and retrieval of high-dimensional vectors. Here, we used the embedding model “all-mpnet-base-v2” from HuggingFace and used Qdrant as our Vector DB.
# Initialize the TextEmbedding model
from langchain.embeddings import HuggingFaceEmbeddings
# Step 3: Initialize the TextEmbedding model
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)We are making separate collections for each document so that the agents based on the query will decide which documents it needs based on the query.
# Step 4: Create Qdrant vector store collections for each document
qdrant_collections = {}
for txt_file in txt_files:
qdrant_collections[txt_file] = Qdrant.from_documents(
all_documents[txt_file],
embeddings,
location=":memory:",
collection_name=txt_file,
)For the documents mentioned above, I have 4 collections right now:
Collection: Facebook Terms of Usage.txt
Collection: SLSHandbook Contract Law.txt
Collection: Google Terms of Service_en_in.txt
Collection: OPENAI Terms of use.txt
Now we’ll make a retriever for each collection, which will integrate with LangChain Agents to enable advanced information retrieval functionalities.
retriever = {}
for txt_file in txt_files:
retriever[txt_file] = qdrant_collections[txt_file].as_retriever()Setting ReAct Agents
Here we are going to make functions that the agents can choose to call and get additional information for making decisive conclusions.
Below are the functions that we are using:
- For getting the relevant document (Retriever to be exact):
def get_relevant_document(name : str) -> str:
# String name for fuzzy search
search_name = name
# Find the best match using fuzzy search
best_match = process.extractOne(search_name, txt_files, scorer=fuzz.ratio)
# Get the selected file name
selected_file = best_match[0]
selected_retriever = retriever[selected_file]
global query
results = selected_retriever.get_relevant_documents(query)
global retrieved_text
total_content = "\n\nBelow are the related document's content: \n\n"
chunk_count = 0
for result in results:
chunk_count += 1
if chunk_count > 4:
break
total_content += result.page_content + "\n"
retrieved_text = total_content
return total_content2. For summarizing any text:
def get_summarized_text(name : str) -> str:
from transformers import pipeline
summarizer = pipeline("summarization", model="Falconsai/text_summarization")
global retrieved_text
article = retrieved_text
return summarizer(article, max_length=1000, min_length=30, do_sample=False)[0]['summary_text']3. For getting today’s date:
def get_today_date(input : str) -> str:
import datetime
today = datetime.date.today()
return f"\n {today} \n"4. For getting age information of a person from any database:
def get_age(name: str, person_database: dict) -> int:
"""
Get the age of a person from the database.
Args:
- name (str): The name of the person.
- person_database (dict): A dictionary containing person information.
Returns:
- int: The age of the person if found, otherwise None.
"""
if name in person_database:
return person_database[name]["Age"]
else:
return None
def get_age_info(name: str) -> str:
"""
Get age and health information for a person.
Args:
- name (str): The name of the person.
Returns:
- str: A string containing age and health information for the person.
"""
person_database = {
"Sam": {"Age": 21, "Nationality": "US"},
"Alice": {"Age": 25, "Nationality": "UK"},
"Bob": {"Age": 11, "Nationality": "US"}
}
age = get_age(name, person_database)
if age is not None:
return f"\nAge: {age}\n"
else:
return f"\nAge Information for {name} not found.\n"Here we wrapped the Functions around “from langchain.agents import Tool” so that it can be used by agents.
# Define the Tool
get_age_info_tool = Tool(
name="Get Age",
func=get_age_info,
description="Useful for getting age information for any person. Input should be the name of the person."
)
get_today_date_tool = Tool(
name="Get Todays Date",
func=get_today_date,
description="Useful for getting today's date"
)
get_relevant_document_tool = Tool(
name="Get Relevant document",
func=get_relevant_document,
description="Useful for getting relevant document that we need."
)
get_summarized_text_tool = Tool(
name="Get Summarized Text",
func=get_summarized_text,
description="Useful for getting summarized text for any document."
)Setting Agent Prompts
Here we used the famous Agent Prompt from LangChain Hub:
from langchain import hub
prompt_react = hub.pull("hwchase17/react")
print(prompt_react.template)Output for this Prompt Template:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}ReAct Agent Creation
LangChain’s ReAct agents are instrumental in orchestrating the entire query handling process. By utilizing these agents, we can break down complex queries into manageable steps and execute them systematically. Below, we’ll create and configure a ReAct agent to facilitate intelligent query processing.
tools = [get_relevant_document_tool, get_summarized_text_tool, get_today_date_tool, get_age_info_tool]
retrieved_text = ""
# Load ReAct prompt
prompt_react = hub.pull("hwchase17/react")
# Initialize ChatGroq model for language understanding
model = ChatGroq(model_name="llama3-70b-8192", groq_api_key=GROQ_API_KEY, temperature=0)
# Create ReAct agent
react_agent = create_react_agent(model, tools=tools, prompt=prompt_react)
react_agent_executor = AgentExecutor(
agent=react_agent, tools=tools, verbose=True, handle_parsing_errors=True
)Executing Complex Queries
With the environment setup and the ReAct agent configured, we can now execute complex queries. Let’s explore a couple of examples:
1. query = “Give me the summary for the question : What age requirement is specified for using the OpenAI Services, and what provision applies if the user is under 18?”
react_agent_executor.invoke({"input": query})Output:
> Entering new AgentExecutor chain...
Thought: I need to find a relevant document that mentions the age requirement for using OpenAI Services.
Action: Get Relevant document
Action Input: OpenAI Terms of Service
Below are the related document's content:
[Document Content]
Thought: I have the relevant document, now I need to summarize the part that mentions the age requirement.
Action: Get Summarized Text
Action Input: The relevant document content
[Summarized Content]
Final Answer: The age requirement for using OpenAI Services is at least 13 years old or the minimum age required in your country to consent to use the Services. If you are under 18, you must have your parent or legal guardian's permission to use the Services.
> Finished chain.2. query = “Give me summary of What resources does Google offer to users for assistance and guidance in using its services?”
react_agent_executor.invoke({"input": query})Output:
> Entering new AgentExecutor chain...
Thought: I need to find a relevant document that provides information on the resources Google offers to users for assistance and guidance in using its services.
Action: Get Relevant document
Action Input: Google user resources
Below are the related document's content:
[Document Content]
Thought: I need to summarize the content of the document to get a summary of what resources Google offers to users for assistance and guidance in using its services.
Action: Get Summarized Text
Action Input: The document content
[Summarized Content]
Final Answer: Google offers various resources to users for assistance and guidance in using its services, including terms of service, privacy policy, security checkup, and service-related communications. These resources help establish what users can expect from Google and what Google expects from users, including rules for using services, intellectual property rights, and content management. Additionally, Google provides resources for organizations using its services, such as assigning Google Accounts and requiring additional rules.
> Finished chain.3. query = “I am Bob. Will i be eligible in 2027 for the age requirement specified for using the OpenAI Services by OpenAI Terms?”
react_agent_executor.invoke({"input": query})Output:
> Entering new AgentExecutor chain...
Thought: I need to know the age requirement specified in the OpenAI Terms and my current age to determine if I'll be eligible in 2027.
Action: Get Relevant document
Action Input: OpenAI Terms
Below are the related document's content:
[Document Content]
Thought: I have the OpenAI Terms document, now I need to know my current age to determine if I'll be eligible in 2027.
Action: Get Age
Action Input: Bob
Age: 11
Thought: I now know my current age, which is 11. I need to determine if I'll be eligible in 2027 for the age requirement specified in the OpenAI Terms.
Action: Get Todays Date
Action Input: None
2024-05-18
Thought: I have my current age and today's date. I need to calculate my age in 2027 to determine if I'll be eligible for using the OpenAI Services.
Action: Calculate age in 2027
..... And so on as per tools availableConclusion
In conclusion, the integration of LangChain’s ReAct Agents with Qdrant and Llama3 opens up exciting possibilities for intelligent information retrieval systems. By leveraging advanced NLP techniques and tools, we can enhance query handling efficiency and provide insightful responses to user queries.
With these steps, you can build your own intelligent information retrieval system powered by LangChain, Qdrant, and Llama3.
You can also add a Gradio UI over the system:
import gradio as gr
from io import StringIO
import sys
import re
def generate_response(question):
"""
Generate a response based on the provided question using ChatGroq.
Args:
- question (str): The question input by the user.
Returns:
- str: The generated response based on the question.
"""
tools = [get_age_info_tool, get_health_info_tool]
model = ChatGroq(model_name="llama3-70b-8192", groq_api_key=GROQ_API_KEY, temperature=0)
# model = OpenAI(openai_api_key="<OPENAI_API>")
react_agent = create_react_agent(model, tools=tools, prompt=prompt_react)
react_agent_executor = AgentExecutor(
agent=react_agent, tools=tools, verbose=True, handle_parsing_errors=True
)
# Redirect stdout to capture text
with StringIO() as text_output:
sys.stdout = text_output
completion = react_agent_executor.invoke({"input": question})
sys.stdout = sys.__stdout__ # Reset stdout
# Get the captured text
text_output_str = text_output.getvalue()
# Remove ANSI escape codes
text_output_str = re.sub(r'\x1b\[[0-9;]*m', '', text_output_str)
return text_output_str
# Set up the Gradio interface
iface = gr.Interface(
fn=generate_response,
inputs=[gr.Textbox(label="Question")], # Pass input as a list
outputs=[gr.Textbox(label="Generated Response")], # Pass output as a list
title="Intellegent RAG with Qdrant, LangChain ReAct and Llama3 from Groq Endpoint",
description="Enter a question and get a generated response based on the retrieved text.",
)
iface.launch()References
Some articles you can later refer to:
Using Qdrant with AWS, Google Cloud for RAG: https://link.medium.com/BIUUY53GDJb
How to Use Qdrant with RAY for Parallel Distributed Faster RAG: https://link.medium.com/5020yDZGDJb
Thank you for reading

{kind=link}