Last updated: Feburary 28, 2019.
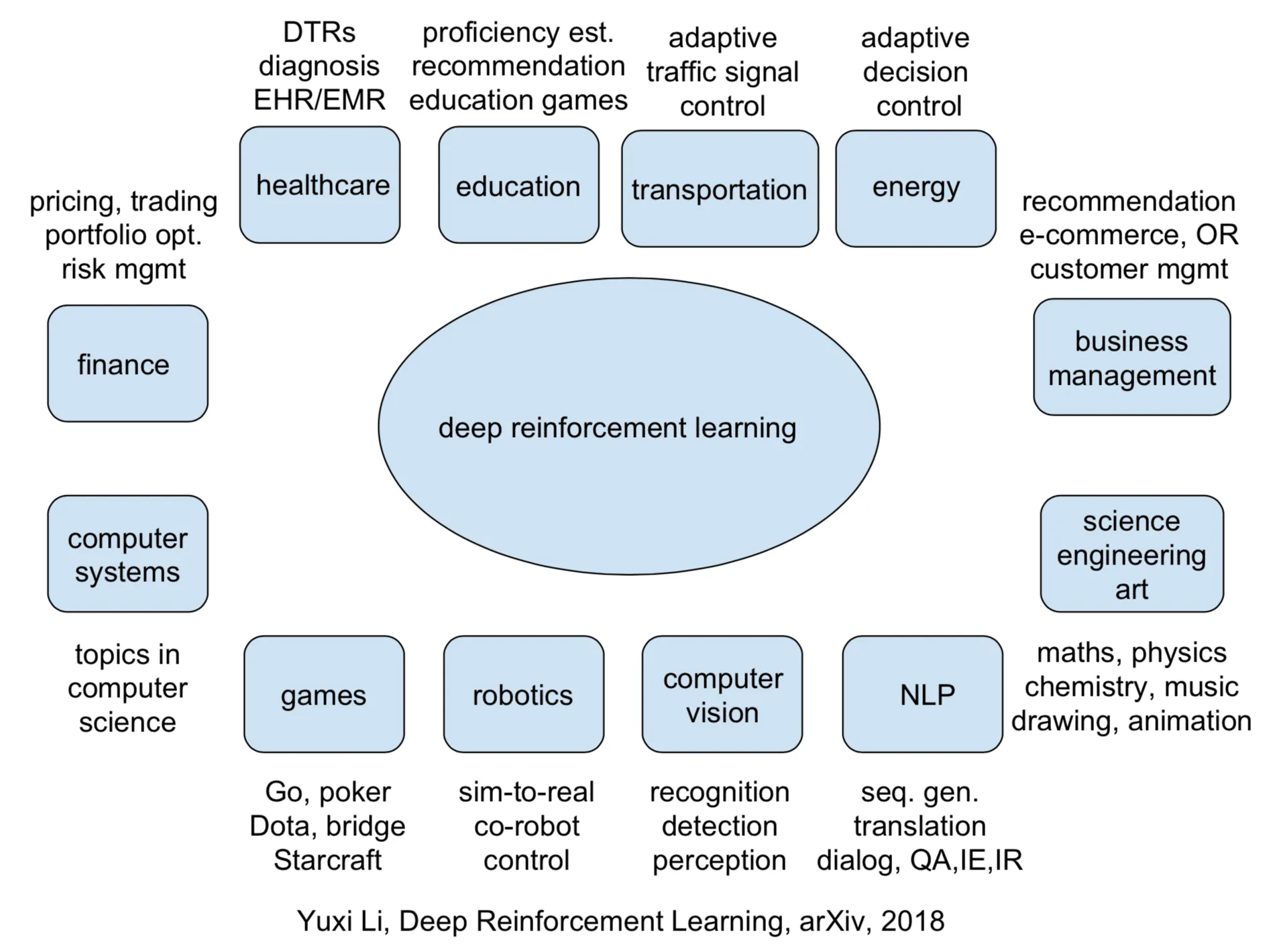
Reinforcement learning (RL) has made tremendous achievements, e.g., AlphaGo. Here I list (deep) RL applications in the following categories: production, autonomous driving, business management, computer systems, computer vision, education, energy, finance, games, healthcare, natural language processing (NLP), robotics, “science, engineering and arts”, and transportation. See Table of Contents.
I list “production” in the first place to highlight RL’s real life deployments, and list the rest alphabetically. I list only a few papers for games and robotics, since they are traditional RL application areas, and many people are familiar with them.
There are actually too many RL applications papers for me to update in this blog in a reasonble way. (I may update once more in one month or so.) I’d like to make some general comments as below:
- check references and citations of papers here
- check Google/Google Scholar
- keep track of recent papers, e.g., on arXiv and on conferences like ICML, NeurIPS, KDD, WWW, RecSys, etc.
- keep track of some authors
- check ICML 2019 RL for Real Life Workshop
I focus on recent work. This blog is complementary to Deep Reinforcement Learning: An Overview.
Previously, RL applications are discussed/listed in
- Reinforcement Learning: An Introduction, Chapter 16
- Csaba Szepesvári, RLApplications.bib
- Satinder Singh, Successes of Reinforcement Learning
See my previous blog, Resources for Deep Reinforcement Learning. It contains a section about Benchmarks and Testbeds.
Table of Contents
- Production Systems
- Autonomous Driving
- Business Management
- Business Management: Recommender Systems
- Computer Systems: Database, Hardware, Machine Learning, Networking, Program Synthesis, Scheduling, Security, Software Testing, WWW
- Computer Vision: Recognition, Scene Understanding, Interactive Perception, More Topics
- Education
- Energy
- Finance
- Games
- Healthcare
- Natural Language Processing (NLP): Captioning, Dialogue, Information Extraction, Information Retrieval, Linguistics, Question Answering (QA), Reasoning, Sequence Generation, Summarization, Translation, Text Games, Visual Dialog, More Topics
- Robotics: Dexterity, Sim-to-Real, Value-based Learning, Policy-based Learning
- Science, Engineering, and Art
- Science: Biology, Chemistry, Drug Design, Earth Science, Maths, Physics
- Art: Animation, Drawing, Music, Story Telling
- Transportation
Production Systems
I start with applications of RL in production systems, not just as research results, to highlight the practical importance of RL. There may be more cases I have not listed here. Please let me know them in comments. Thanks!
- Google Cloud AutoML
- Facebook Horizon
- Recommendation, advertisement, search (many successes with bandits; deep RL experiments in real systems: a survey)
Go to Table of Contents
Autonomous Driving
- O’Kelly, M., Sinha, A., Namkoong, H., Tedrake, R., and Duchi, J. C. (2018). Scalable end-to-end autonomous vehicle testing via rare-event simulation. In NIPS.
- Lange, S., Riedmiller, M., and Voigtla ̈nder, A. (2012). Autonomous reinforcement learning on raw visual input data in a real world application. In International Joint Conference on Neural Networks (IJCNN).
- Li, D., Zhao, D., Zhang, Q., and Chen, Y. (2019a). Reinforcement learning and deep learning based lateral control for autonomous driving. IEEE Computational Intelligence Magazine (to appear).
Go to Table of Contents
Business Management
- Cai, Q., Filos-Ratsikas, A., Tang, P., and Zhang, Y. (2018). Reinforcement mechanism design for fraudulent behaviour in e-commerce. In AAAI.
- Nazari, M., Oroojlooy, A., Snyder, L., and Takáč, M. (2018). Reinforcement learning for solving the vehicle routing problem. In NIPS
- Shi, J.-C., Yu, Y., Da, Q., Chen, S.-Y., and Zeng, A.-X. (2018). Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning. ArXiv.
- Silver, D., Newnham, L., Barker, D., Weller, S., and McFall, J. (2013). Concurrent reinforcement learning from customer interactions. In ICML.
Business Management: Recommender Systems
- Zhao, X., Xia, L., Tang, J., and Yin, D. (2018). Deep reinforcement learning for search, recommendation, and online advertising: A survey. ArXiv.
- Zhang, S., Yao, L., Sun, A., and Tay, Y. (2017). Deep Learning based Recommender System: A Survey and New Perspectives. ArXiv.
- Chen, S.-Y., Yu, Y., Da, Q., Tan, J., Huang, H.-K., and Tang, H.-H. (2018). Stabilizing reinforcement learning in dynamic environment with application to online recommendation. In KDD.
- Hu, Y., Da, Q., Zeng, A., Yu, Y., and Xu, Y. (2018). Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application. In KDD.
- Hu, Z., Liang, Y., Liu, Y., and Zhang, J. (2018b). Inference aided reinforcement learning for incentive mechanism design in crowdsourcing. In NIPS.
- Lattimore, T., Kveton, B., Li, S., and Szepesvári, C. (2018). Toprank: A practical algorithm for online stochastic ranking. In NIPS.
- Li, L., Chu, W., Langford, J., and Schapire, R. E. (2010). A contextual-bandit approach to personalized news article recommendation. In WWW.
- Jiang, N. and Li, L. (2016). Doubly robust off-policy value evaluation for reinforcement learning. In ICML.
- Theocharous, G., Thomas, P. S., and Ghavamzadeh, M. (2015). Personalized ad recommendation systems for life-time value optimization with guarantees. In IJCAI.
- Zhao, X., Xia, L., Zhang, L., Ding, Z., Yin, D., and Tang, J. (2018). Deep reinforcement learning for page-wise recommendations. In ACM RecSys.
- Zhao, X., Zhang, L., Ding, Z., Xia, L., Tang, J., and Yin, D. (2018). Recommendations with negative feedback via pairwise deep reinforcement learning. In KDD.
- Zheng, G., Zhang, F., Zheng, Z., Xiang, Y., Yuan, N. J., Xie, X., and Li, Z. (2018a). DRN: A deep reinforcement learning framework for news recommendation. In WWW.
Go to Table of Contents
Computer Systems
In this blog, there are also topics like games, robotics, computer vision, and natural language processing (NLP), which are subjects of computer science. This section is basically about “non-AI” topics in computer science. The “CS: Machine Learning” sub-section is about applying meta-learning techniques to machine learning problems.
CS: Database
- Krishnan, S., Yang, Z., Goldberg, K., Hellerstein, J., and Stoica, I. (2018). Learning to Optimize Join Queries With Deep Reinforcement Learning. ArXiv e-prints.
CS: Hardware
- Liu, J., Chen, Z.-X., Dong, W.-H., Wang, X., Shi, J., Teng, H.-L., Dai, X.-W., Yau, S. S.-T., Liang, C.-H., and Feng, P.-F. (2019). Microwave integrated circuits design with relational induction neural network. ArXiv.
CS: Machine Learning
- Fang, M., Li, Y., and Cohn, T. (2017). Learning how to active learn: A deep reinforcement learning approach. In EMNLP.
- Hsu, K., Levine, S., and Finn, C. (2018). Unsupervised Learning via Meta-Learning. ArXiv e-prints.
- Hu, Z., Yang, Z., Salakhutdinov, R., Qin, L., Liang, X., Dong, H., and Xing, E. (2018). Deep generative models with learnable knowledge constraints. In NIPS. (learn knowledge constraints with inverse RL)
- Negrinho, R., Gormley, M., and Gordon, G. (2018). Learning beam search policies via imitation learning. In NIPS.
- He, Y., Lin, J., Liu, Z., Wang, H., Li, L.-J., and Han, S. (2018). AMC: AutoML for model compression and acceleration on mobile devices. In ECCV.
CS: Networking
- Liu, N., Li, Z., Xu, Z., Xu, J., Lin, S., Qiu, Q., Tang, J., and Wang, Y. (2017). A hierarchical framework of cloud resource allocation and power management using deep reinforcement learning. In ICDCS.
- Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja Venkatakrishnan, Zili Meng, Mohammad Alizadeh, Learning Scheduling Algorithms for Data Processing Clusters, ACM SIGCOMM 2019
- Hongzi Mao, et al., Park: An Open Platform for Learning Augmented Computer Systems, ICML 2019 RL for Real Life Workshop
CS: Program Synthesis
- Balog, M., Gaunt, A. L., Brockschmidt, M., Nowozin, S., and Tarlow, D. (2017). Deepcoder: Learning to write programs. In ICLR.
- Faust, A., Aimone, J. B., James, C. D., and Tapia, L. (2018). Resilient Computing with Reinforcement Learning on a Dynamical System: Case Study in Sorting. ArXiv e-prints.
- Liang, C., Berant, J., Le, Q., Forbus, K. D., and Lao, N. (2017). Neural symbolic machines: Learning semantic parsers on freebase with weak supervision. In ACL.
- Liang, C., Norouzi, M., Berant, J., Le, Q. V., and Lao, N. (2018). Memory augmented policy optimization for program synthesis with generalization. In NIPS.
- Nachum, O., Norouzi, M., and Schuurmans, D. (2017). Improving policy gradient by exploring under-appreciated rewards. In ICLR.
- Parisotto, E., Mohamed, A.-r., Singh, R., Li, L., Zhou, D., and Kohli, P. (2017). Neuro-symbolic program synthesis. In ICLR.
- Reed, S. and de Freitas, N. (2016). Neural programmer-interpreters. In ICLR.
- Vinyals, O., Fortunato, M., and Jaitly, N. (2015). Pointer networks. In NIPS.
- Zaremba, W. and Sutskever, I. (2015). Reinforcement Learning Neural Turing Machines — Revised. ArXiv.
- Zhang, L., Rosenblatt, G., Fetaya, E., Liao, R., Byrd, W., Might, M., Urtasun, R., and Zemel, R. (2018). Neural guided constraint logic programming for program synthesis. In NIPS.
CS: Scheduling
- Gao, Y., Chen, L., and Li, B. (2018). Post: Device placement with cross-entropy minimization and proximal policy optimization. In NIPS.
- Mirhoseini, A., Pham, H., Le, Q. V., Steiner, B., Larsen, R., Zhou, Y., Kumar, N., and Mohammad Norouzi, Samy Bengio, J. D. (2017). Device placement optimization with reinforcement learning. In ICML.
CS: Security
- Anderson, H. S., Kharkar, A., Filar, B., Evans, D., and Roth, P. (2018). Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning. ArXiv.
- Havens, A., Jiang, Z., and Sarkar, S. (2018). Online robust policy learning in the presence of unknown adversaries. In NIPS.
- Huang, S., Papernot, N., Goodfellow, I., Duan, Y., and Abbeel, P. (2017). Adversarial attacks on neural network policies. In ICLR Workshop Track.
- Jun, K.-S., Li, L., Ma, Y., and Zhu, X. (2018). Adversarial attacks on stochastic bandits. In NIPS.
CS: Software Testing
- Reichstaller, A. and Knapp, A. (2017). Transferring context-dependent test inputs. In IEEE International Conference on Software Quality, Reliability and Security (QRS).
CS: WWW
- Nogueira, R. and Cho, K. (2017). Task-oriented query reformulation with reinforcement learning. In EMNLP.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., and Abbeel, P. (2016). Value iteration networks. In NIPS. (Wikipedia links navigation)
Go to Table of Contents
Computer Vision
CV: Recognition
- Caicedo, J. C. and Lazebnik, S. (2015). Active object localization with deep reinforcement learning. In ICCV.
- Jie, Z., Liang, X., Feng, J., Jin, X., Lu, W. F., and Yan, S. (2016). Tree-structured reinforcement learning for sequential object localization. In NIPS.
- Kong, X., Xin, B., Wang, Y., and Hua, G. (2017). Collaborative deep reinforcement learning for joint object search. In CVPR.
- Krull, A., Brachmann, E., Nowozin, S., Michel, F., Shotton, J., and Rother, C. (2017). Poseagent: Budget-constrained 6d object pose estimation via reinforcement learning. In CVPR.
- Mathe, S., Pirinen, A., and Sminchisescu, C. (2016). Reinforcement learning for visual object detection. In CVPR.
- Mnih, V., Heess, N., Graves, A., and Kavukcuoglu, K. (2014). Recurrent models of visual attention. In NIPS.
- Rao, Y., Lu, J., and Zhou, J. (2017). Attention-aware deep reinforcement learning for video face recognition. In ICCV.
- Welleck, S., Mao, J., Cho, K., and Zhang, Z. (2017). Saliency-based sequential image attention with multiset prediction. In NIPS.
- Rhinehart, N. and Kitani, K. M. (2017). First-person activity forecasting with online inverse reinforcement learning. In ICCV.
- Supancic, III, J. and Ramanan, D. (2017). Tracking as online decision-making: Learning a policy from streaming videos with reinforcement learning. In ICCV.
- Xu, M., Song, Y., Wang, J., Qiao, M., Huo, L., and Wang, Z. (2018). Predicting head movement in panoramic video: A deep reinforcement learning approach. TPAMI.
- Yun, S., Choi, J., Yoo, Y., Yun, K., and Young Choi, J. (2017). Action-decision networks for visual tracking with deep reinforcement learning. In CVPR.
CV: Scene Understanding
- Eslami, S. M. A., Rezende, D. J., Besse, F., Viola, F., Morcos, A. S., Garnelo, M., Ruderman, A., Rusu, A. A., Danihelka, I., Gregor, K., Reichert, D. P., Buesing, L., Weber, T., Vinyals, O., Rosenbaum, D., Rabinowitz, N., King, H., Hillier, C., Botvinick, M., Wierstra, D., Kavukcuoglu, K., and Hassabis, D. (2018). Neural scene representation and rendering. Science, 360:1204–1210.
- Wu, J., Lu, E., Kohli, P., Freeman, B., and Tenenbaum, J. (2017). Learning to see physics via visual de-animation. In NIPS.
- Wu, J., Tenenbaum, J. B., and Kohli, P. (2017). Neural scene de-rendering. In CVPR.
CV: Interactive Perception
- Bohg, J., Hausman, K., Sankaran, B., Brock, O., Kragic, D., Schaal, S., and Sukhatme, G. S. (2017). Interactive perception: Leveraging action in perception and perception in action. IEEE Transactions on Robotics, 33(6):1273–1291.
- Jayaraman, D. and Grauman, K. (2018). Learning to look around: Intelligently exploring unseen environments for unknown tasks. In CVPR.
CV: More Topics
- Bhatti, S., Desmaison, A., Miksik, O., Nardelli, N., Siddharth, N., and Torr, P. H. S. (2016). Playing Doom with SLAM-Augmented Deep Reinforcement Learning. ArXiv.
- Brunner, G., Richter, O., Wang, Y., and Wattenhofer, R. (2018). Teaching a machine to read maps with deep reinforcement learning. In AAAI.
- Cao, Q., Lin, L., Shi, Y., Liang, X., and Li, G. (2017). Attention-aware face hallucination via deep reinforcement learning. In CVPR.
- Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. (2018). AutoAugment: Learning Augmentation Policies from Data. ArXiv.
- Devrim Kaba, M., Gokhan Uzunbas, M., and Nam Lim, S. (2017). A reinforcement learning approach to the view planning problem. In CVPR.
- Liu, F., Li, S., Zhang, L., Zhou, C., Ye, R., Wang, Y., and Lu, J. (2017). 3DCNN-DQN-RNN: A deep reinforcement learning framework for semantic parsing of large-scale 3d point clouds. In ICCV.
- see captioning, visual dialog, visual QA, etc. in the section of NLP
- see games and robotics for computer vision issues
Go to Table of Contents
Education
- Liu, Y.-E., Mandel, T., Brunskill, E., and Popović, Z. (2014). Trading off scientific knowledge and user learning with multi-armed bandits. In Educational Data Mining (EDM).
- Mandel, T., Liu, Y. E., Levine, S., Brunskill, E.,and Popović, Z.(2014). Offline policy evaluation across representations with applications to educational games. In AAMAS.
- Upadhyay, U., De, A., and Rodriguez, M. G. (2018). Deep reinforcement learning of marked temporal point processes. In NIPS.
Go to Table of Contents
Energy
- Anderson, R. N., Boulanger, A., Powell, W. B., and Scott, W. (2011). Adaptive stochastic control for the smart grid. Proceedings of the IEEE, 99(6):1098–1115.
- Glavic, M., Fonteneau, R., and Ernst, D. (2017). Reinforcement learning for electric power system decision and control: Past considerations and perspectives. In The 20th World Congress of the International Federation of Automatic Control.
- Lazic, N., Boutilier, C., Lu, T., Wong, E., Roy, B., Ryu, M., and Imwalle, G. (2018). Data center cooling using model-predictive control. In NIPS.
- Ruelens, F., Claessens, B. J., Vandael, S., Schutter, B. D., Babuška, R., and Belmans, R. (2016). Residential demand response of thermostatically controlled loads using batch reinforcement learning. IEEE Transactions on Smart Grid, PP(99):1–11.
- Wen, Z., O’Neill, D., and Maei, H. (2015). Optimal demand response using device-based reinforcement learning. IEEE Transactions on Smart Grid, 6(5):2312–2324.
Go to Table of Contents
Finance
- Brandt, M. W., Goyal, A., Santa-Clara, P., and Stroud, J. R. (2005). A simulation approach to dynamic portfolio choice with an application to learning about return predictability. The Review of Financial Studies, 18(3):831–873.
- Deng, Y., Bao, F., Kong, Y., Ren, Z., and Dai, Q. (2016). Deep direct reinforcement learning for financial signal representation and trading. IEEE Transactions on Neural Networks and Learning Systems.
- Li, Y., Szepesvári, C., and Schuurmans, D. (2009). Learning exercise policies for American options. In AISTATS.
- Longstaff, F. A. and Schwartz, E. S. (2001). Valuing American options by simulation: a simple least-squares approach. The Review of Financial Studies, 14(1):113–147.
- Moody, J. and Saffell, M. (2001). Learning to trade via direct reinforcement. TNN, 12(4):875–889.
- Nevmyvaka, Y., Feng, Y., and Kearns, M. (2006). Reinforcement learning for optimized trade execution. In ICML.
- Prashanth, L., Jie, C., Fu, M., Marcus, S., and Szepesvári, C. (2016). Cumulative prospect theory meets reinforcement learning: Prediction and control. In ICML.
- Tsitsiklis, J. N. and Van Roy, B. (2001). Regression methods for pricing complex American-style options. IEEE Transactions on Neural Networks, 12(4):694–703.
Go to Table of Contents
Games
Computer games are the most popular testbeds for RL algorithms, e.g., The Arcade Learning Environment (ALE), OpenAI Gym, DeepMind Lab, DeepMind PySC2, ELF, etc. There are thus many papers applying RL to various games. I list several representative papers below. For more RL applications in games, refer to Deep Reinforcement Learning, or a survey and a book below.
- Justesen, N., Bontrager, P., Togelius, J., and Risi, S. (2017). Deep Learning for Video Game Playing. ArXiv.
- Yannakakis, G. N. and Togelius, J. (2018). Artificial Intelligence and Games. Springer.
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II
- Aytar, Y., Pfaff, T., Budden, D., Paine, T., Wang, Z., and de Freitas, N. (2018). Playing hard exploration games by watching YouTube. In NIPS.
- Bowling, M., Burch, N., Johanson, M., and Tammelin, O. (2015). Heads-up limit hold’em poker is solved. Science, 347(6218):145–149.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., and Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540):529–533.
- Moravčík, M., Schmid, M., Burch, N., Lisý, V., Morrill, D., Bard, N., Davis, T., Waugh, K., Johanson, M., and Bowling, M. (2017). Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science.
- Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489.
- Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., and Hassabis, D. (2017). Mastering the game of go without human knowledge. Nature, 550:354–359.
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D. (2018). A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144.
Go to Table of Contents
Healthcare
- Omer Gottesman, et al., Guidelines for reinforcement learning in healthcare, Nature Medicine 2019
- Deep reinforcement learning for medical imaging, tutorial at MICCAI 2018
- Goldberg, Y. and Kosorok, M. R. (2012). Q-learning with censored data. Annals of Statistics, 40(1):529–560.
- Kallus, N. and Zhou, A. (2018). Confounding-robust policy improvement. In NIPS.
- Komorowski, M., Celi, L. A., Badawi, O., Gordon, A. C., and Faisal, A. A. (2018). The artifi- cial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24:1716–1720.
- Li, Y., Liang, X., Hu, Z., and Xing, E. (2018). Hybrid retrieval-generation reinforced agent for medical image report generation. In NIPS.
- Ling, Y., Hasan, S. A., Datla, V., Qadir, A., Lee, K., Liu, J., and Farri, O. (2017). Diagnostic inferencing via improving clinical concept extraction with deep reinforcement learning: A preliminary study. In Machine Learning for Healthcare.
- Liu, Y., Gottesman, O., Raghu, A., Komorowski, M., Faisal, A. A., Doshi-Velez, F., and Brunskill, E. (2018b). Representation balancing MDPs for off-policy policy evaluation. In NIPS.
- Peng, Y.-S., Tang, K., Lin, H.-T., and Chang, E. (2018). Exploring sparse features in deep reinforcement learning towards fast disease diagnosis. In NIPS.
- Shortreed, S. M., Laber, E., Lizotte, D. J., Stroup, T. S., Pineau, J., and Murphy, S. A. (2011). Informing sequential clinical decision-making through reinforcement learning: an empirical study. MLJ, 84:109–136.
Go to Table of Contents
Natural Language Processing (NLP)
NLP is a relatively new application area for RL. However, there are already many papers in many sub-areas. See books and tutorials below.
- Jurafsky, D. and Martin, J. H. (2017). Speech and Language Processing (3rd ed. draft). Prentice Hall.
- Jianfeng Gao, Michel Galley, and Lihong Li, Neural approaches to Conversational AI. ACL 2018 Tutorial. arXiv, now
- William Wang, Jiwei Li, and Xiaodong He, Deep reinforcement learning for NLP. ACL 2018 Tutorial.
NLP: Captioning
- Pasunuru, R. and Bansal, M. (2017). Reinforced video captioning with entailment rewards. In EMNLP.
- Ren, Z., Wang, X., Zhang, N., Lv, X., and Li, L.-J. (2017). Deep reinforcement learning-based image captioning with embedding reward. In CVPR.
- Wang, X., Chen, W., Wu, J., Wang, Y.-F., and Wang, W. Y. (2018). Video captioning via hierarchical reinforcement learning. In CVPR.
- Xu, K., Ba, J. L., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R. S., and Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. In ICML.
NLP: Dialogue
- Lu Chen, Cheng Chang, Zhi Chen, Bowen Tan, Milica Gasic and Kai Yu, Policy Adaptation for Deep Reinforcement Learning-based Dialogue Management, ICASSP 2018
- Dhingra, B., Li, L., Li, X., Gao, J., Chen, Y.-N., Ahmed, F., and Deng, L. (2017). End-to-end reinforcement learning of dialogue agents for information access. In ACL.
- Li, J., Monroe, W., Ritter, A., Galley, M., Gao, J., and Jurafsky, D. (2016). Deep reinforcement learning for dialogue generation. In EMNLP.
- Su, P.-H., Gašić, M., Mrkšić, N., Rojas-Barahona, L., Ultes, S., Vandyke, D., Wen, T.-H., and Young, S. (2016). On-line active reward learning for policy optimisation in spoken dialogue systems. In ACL.
- Many more, check Deep Reinforcement Learning
NLP: Information Extraction
- Narasimhan, K., Yala, A., and Barzilay, R. (2016). Improving information extraction by acquiring external evidence with reinforcement learning. In EMNLP.
NLP: Information Retrieval
- Wang, J., Yu, L., Zhang, W., Gong, Y., Xu, Y., Wang, B., Zhang, P., and Zhang, D. (2017). IRGAN: A minimax game for unifying generative and discriminative information retrieval models. In SIGIR.
NLP: Linguistics
- Guu, K., Pasupat, P., Liu, E. Z., and Liang, P. (2017). From language to programs: Bridging reinforcement learning and maximum marginal likelihood. In ACL.
- Liang, C., Berant, J., Le, Q., Forbus, K. D., and Lao, N. (2017). Neural symbolic machines: Learning semantic parsers on freebase with weak supervision. In ACL.
- Yogatama, D., Blunsom, P., Dyer, C., Grefenstette, E., and Ling, W. (2017). Learning to compose words into sentences with reinforcement learning. In ICLR.
NLP: Question Answering (QA)
- Choi, E., Hewlett, D., Polosukhin, I., Lacoste, A., Uszkoreit, J., and Berant, J. (2017). Coarse-to-fine question answering for long documents. In ACL.
- Shen, Y., Huang, P.-S., Gao, J., and Chen, W. (2017). Reasonet: Learning to stop reading in machine comprehension. In KDD.
NLP: Reasoning
- Hudson, D. A. and Manning, C. D. (2018). Compositional attention networks for machine reasoning. In ICLR.
- Liang, X., Lee, L., and Xing, E. P. (2017). Deep variation-structured reinforcement learning for visual relationship and attribute detection. In CVPR.
- Xiong, W., Hoang, T., and Wang, W. Y. (2017c). Deeppath: A reinforcement learning method for knowledge graph reasoning. In EMNLP.
NLP: Sequence Generation
- Bahdanau, D., Brakel, P., Xu, K., Goyal, A., Lowe, R., Pineau, J., Courville, A., and Bengio, Y. (2017). An actor-critic algorithm for sequence prediction. In ICLR.
- Jaques, N., Gu, S., Bahdanau, D., Hernández-Lobato, J. M., Turner, R. E., and Eck, D. (2017). Sequence tutor: Conservative fine-tuning of sequence generation models with KL-control. In ICML.
- Ranzato, M., Chopra, S., Auli, M., and Zaremba, W. (2016). Sequence level training with recurrent neural networks. In ICLR.
- Yu, L., Zhang, W., Wang, J., and Yu, Y. (2017). SeqGAN: Sequence generative adversarial nets with policy gradient. In AAAI.
NLP: Summarization
- Paulus, R., Xiong, C., and Socher, R. (2018). A Deep Reinforced Model for Abstractive Summarization. In ICLR.
- Zhang, X. and Lapata, M. (2017). Sentence simplification with deep reinforcement learning. In EMNLP.
NLP: Text Games
- Microsoft TextWorld
- He, J., Chen, J., He, X., Gao, J., Li, L., Deng, L., and Ostendorf, M. (2016b). Deep reinforcement learning with a natural language action space. In ACL.
- Narasimhan, K., Kulkarni, T., and Barzilay, R. (2015). Language understanding for text-based games using deep reinforcement learning. In EMNLP.
NLP: Translation
- He, D., Xia, Y., Qin, T., Wang, L., Yu, N., Liu, T.-Y., and Ma, W.-Y. (2016a). Dual learning for machine translation. In NIPS.
NLP: Visual Dialog
- Das, A., Kottur, S., Moura, J. M. F., Lee, S., and Batra, D. (2017). Learning cooperative visual dialog agents with deep reinforcement learning. In ICCV.
- Strub, F., de Vries, H., Mary, J., Piot, B., Courville, A., and Pietquin, O. (2017). End-to-end optimization of goal-driven and visually grounded dialogue systems. In IJCAI.
NLP: More Topics
- He, J., Ostendorf, M., He, X., Chen, J., Gao, J., Li, L., and Deng, L. (2016). Deep reinforcement learning with a combinatorial action space for predicting popular reddit threads. In EMNLP.
- Wu, J., Li, L., and Wang, W. Y. (2018). Reinforced co-training. In NAACL.
Go to Table of Contents
Robotics
Robotics is a classical application area for RL. I list a few papers in the following categories: dexterity, sim-to-real, imitation learning, value-, policy-, and model-based learning. See surveys below. See Science Robotics. Watch a NIPS 2017 Invited Talk on Deep learning for robotics. See a recent work on glider soaring.
- Argall, B. D., Chernova, S., Veloso, M., and Browning, B. (2009). A survey of robot learning from demonstration. Robotics and Autonomous Systems, 57(5):469–483.
- Deisenroth, M. P., Neumann, G., and Peters, J. (2013). A survey on policy search for robotics. Foundations and Trend in Robotics, 2:1–142.
- Kober, J., Bagnell, J. A., and Peters, J. (2013). Reinforcement learning in robotics: A survey. International Journal of Robotics Research, 32(11):1238–1278.
Robotics: Dexterity
- Learning Dexterity
- Dexterous Manipulation with Reinforcement Learning: Efficient, General, and Low-Cost
- Zhu, H., Gupta, A., Rajeswaran, A., Levine, S., and Kumar, V. (2018). Dexterous Manipulation with Deep Reinforcement Learning: Efficient, General, and Low-Cost. ArXiv.
Robotics: Sim-to-Real
- Chebotar, Y., Handa, A., Makoviychuk, V., Macklin, M., Issac, J., Ratliff, N., and Fox, D. (2018). Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience. ArXiv.
- Chen, T., Murali, A., and Gupta, A. (2018b). Hardware conditioned policies for multi-robot transfer learning. In NIPS.
- Hwangbo, J., Lee, J., Dosovitskiy, A., Bellicoso, D., Tsounis, V., Koltun, V., and Hutter, M. (2019). Learning agile and dynamic motor skills for legged robots. Science Robotics, 4(26).
- Peng, X. B., Andrychowicz, M., Zaremba, W., and Abbeel, P. (2017). Sim-to-Real Transfer of Robotic Control with Dynamics Randomization. ArXiv.
- Rusu, A. A., Vecerik, M., Rothörl, T., Heess, N., Pascanu, R., and Hadsell, R. (2017). Sim-to-real robot learning from pixels with progressive nets. In Conference on Robot Learning (CoRL).
- Sadeghi, F., Toshev, A., Jang, E., and Levine, S. (2018). Sim2real view invariant visual servoing by recurrent control. In CVPR.
Robotics: Value-based Learning
- Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., and Zaremba, W. (2017). Hindsight experience replay. In NIPS.
- Levine, S., Finn, C., Darrell, T., and Abbeel, P. (2016). End-to-end training of deep visuomotor policies. JMLR, 17:1–40.
- Zhu, Y., Mottaghi, R., Kolve, E., Lim, J. J., Gupta, A., Li, F.-F., and Farhadi, A. (2017). Target-driven visual navigation in indoor scenes using deep reinforcement learning. In ICRA.
Robotics: Policy-based Learning
- Finn, C. and Levine, S. (2017). Deep visual foresight for planning robot motion. In ICRA.
- Gu, S., Holly, E., Lillicrap, T., and Levine, S. (2017). Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In ICRA.
Go to Table of Contents
Science, Engineering, and Art
I attempt to put reinforcement learning in the broad context of science, engineering, and art. In this blog, topics in other sections inevitably overlap with “science, engineering and arts”.
Science: Biology
- Neftci, E. O. and Averbeck, B. B. (2019). Reinforcement learning in artificial and biological systems. Nature Machine Intelligence.
Science: Chemistry
- Segler, M. H. S., Preuss, M., and Waller, M. P. (2018). Planning chemical syntheses with deep neural networks and symbolic AI. Nature, 555:604–610.
- You, J., Liu, B., Ying, R., Pande, V., and Leskovec, J. (2018). Graph convolutional policy network for goal-directed molecular graph generation. In NIPS.
- Neftci, E. O. and Averbeck, B. B. (2019). Reinforcement learning in artificial and biological systems.Nature Machine Intelligence.
Science: Drug Design
- Popova, M., Isayev, O., and Tropsha, A. (2018). Deep reinforcement learning for de novo drug design. Science Advances, 4(7).
Science: Earth Science
- DeVries, P. M. R., Viégas, F., Wattenberg, M., and Meade, B. J. (2018). Deep learning of aftershock patterns following large earthquakes. Nature, 560:632–634.
Science:Maths
- Pan, Y., massoud Farahmand, A., White, M., Nabi, S., Grover, P., and Nikovski, D. (2018). Reinforcement learning with function-valued action spaces for partial differential equation control. In ICML.
- Urban, J., Kaliszyk, C., Michalewski, H., and Olšák, M. (2018). Reinforcement learning of theorem proving. In NIPS.
Science: Physics
- Biamonte, J., Wittek, P., Pancotti, N., Rebentrost, P., Wiebe, N., and Lloyd, S. (2017). Quantum machine learning. Nature, 549:195–202.
Art: Animation
- Peng, X. B., Abbeel, P., Levine, S., and van de Panne, M. (2018). Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. In SIGGRAPH.
- Peng, X. B., Kanazawa, A., Malik, J., Abbeel, P., and Levine, S. (2018b). Sfv: Reinforcement learning of physical skills from videos. ACM Transaction on Graphics, 37(6).
Art: Drawing
- Xie, N., Hachiya, H., and Sugiyama, M. (2012). Artist agent: A reinforcement learning approach to automatic stroke generation in oriental ink painting. In ICML.
Art: Music
- Jaques, N., Gu, S., Bahdanau, D., Hernández-Lobato, J. M., Turner, R. E., and Eck, D. (2017). Sequence tutor: Conservative fine-tuning of sequence generation models with KL-control. In ICML.
Art: Story Telling
- Thue, D., Bulitko, V., Spetch, M., and Wasylishen, E. (2007). Interactive storytelling: A player modelling approach. In AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE).
Go to Table of Contents
Transportation
- Deep Reinforcement Learning with Applications in Transportation, AAAI 2019 Tutorial, https://outreach.didichuxing.com/tutorial/AAAI2019/
- Belletti, F., Haziza, D., Gomes, G., and Bayen, A. M. (2018). Expert level control of ramp metering based on multi-task deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems, 19(4):1198–1207.
- El-Tantawy, S., Abdulhai, B., and Abdelgawad, H. (2013). Multiagent reinforcement learning for integrated network of adaptive traffic signal controllers (marlin-atsc): methodology and large-scale application on down- town toronto. IEEE Transactions on Intelligent Transportation Systems, 14(3):1140–1150.
- Khadilkar, H., A Scalable Reinforcement Learning Algorithm for Scheduling Railway Lines, IEEE Transactions on Intelligent Transportation Systems, 20(2): 727-736, 2019
- Li, M., (Tony)Qin, Z., Jiao, Y., Yang, Y., Gong, Z., Wang, J., Wang, C., Wu, G., and Ye, J. (2019). Efficient ridesharing order dispatching with mean field multi-agent reinforcement learning. In WWW.
- Mannion, P., Duggan, J., and Howley, E. (2016). An experimental review of reinforcement learning algorithms for adaptive traffic signal control. In McCluskey, T., Kotsialos, A., Müller, J., Klügl, F., Rana, O., and R., S., editors, Autonomic Road Transport Support Systems, pages 47–66. Springer.
- Simao, H. P., Day, J., George, A. P., Gifford, T., Nienow, J., and Powell, W. B. (2009). An approximate dynamic programming algorithm for large-scale fleet management: A case application.Transportation Science, 43(2):178–197.
- Wei, H., Zheng, G., Yao, H., and Li, Z. (2018). Intellilight: A reinforcement learning approach for intelligent traffic light control. In KDD.
Go to Table of Contents