

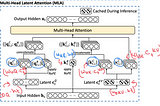
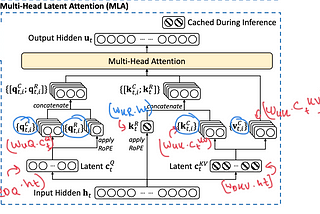
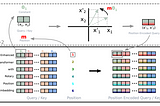
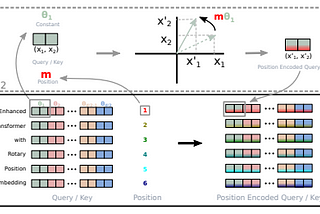







Zain ul Abideen
Machine Learning Engineer | I share what I learn. https://www.linkedin.com/in/zaiinulabideen/ | https://huggingface.co/abideen
Machine Learning Engineer | I share what I learn. https://www.linkedin.com/in/zaiinulabideen/ | https://huggingface.co/abideen