Regresyon(Regression) ve Kolinearite(Multicollinearity) İncelemesi
Datayla Konuşalım !
Dil bilimcilerden bazıları tüm canlılar ses çıkarır ama sadece insanlar konuşur diyorlar. Bazıları ise bu yetenek sadece insana özgü değil dolaylı yolla diğer canlılarda konuşur savını ileri sürüyorlar. Konuşmak iletişim yollarından biri ama etraflıca düşünülürse her canlının iletişim yolu içinde birbirleri ile yaptığı alışverişe “konuşma” denilebilir. İnsanoğlu “konuşma” tanımını “sözlü anlatım” diye sadece kendi zaviyesinden beş duyu organına hitap edecek şekilde tanımlamış ve bu evrensel olabilecek kelimeyi kısıtlamış gözüküyor. Dünya üzerindeki birçok canlının bir çok farklı yolla birbirleri ile iletişim kurduğu ispatlanmış durumdadır ve uç bir örnek verilecek olursa bitkilerde, mantarlarda ve hatta tek hücreli bakterilerde bile “iletişim” yetisine rastlanmaktadır.
Burada değinmek istediğim başka bir yetenek var. İnsanın diğer tüm canlılarla ve cansız varlıklarla kurduğu ya da geliştirdiği iletişim metodu ki çoğumuz buna hayatımızın birçok noktasında şahit olmuşuzdur. Evcil hayvanlarımızla kurduğumuz o özel iletişim, pencere önündeki mor menekşe ile kurulan iletişim, sevgiliden gelen boynumuzda taşıdığımız kolye ile kurulan yürekten iletişim gibi ve insanı bilim dünyasında yücelmesine olanak sağlayan sayılarla formüllerle kurduğu iletişim. Kabul, bu son yazdığım iletişim herkese hitap eden bir iletişim yolu olmasa da bu yeteneğe sahip olanların çok iyi bildiği bir dil sayılarla rakamlarla olan iletişim.
İşte sayılar yığını olan ya da her ele gelen veriyi sayıya çevirip onunla iletişim kuranlar arada özel formüller geliştirerek onları anlayıp anlamlandırmayı başarmış ve bir nevi onların kendi aralarındaki konuşmayı dinleyip insanlığa aktarmayı başarmışlardır.
Veri biliminin temeli veri ile kurulan iletişime ve onu ne kadar iyi dinleyip sorulan anlamlı sorularla ne kadar iyi cevaplar aldığımıza dayanıyor. Nasıl yaklaşılmalı bir veriye? Eee her seven sevdiğine yaklaşmanın yolunu bilmeli bilmiyorsa da bulmalı değil mi? Peki biz bu sevgiliye nasıl yaklaşmalıyız?
Yaptığım araştırmalardan çıkan ilk başlık “Veri Setini Anlama” olarak karşımıza çıkıyor. Bunun için de veri setindeki değişkenlerin (features) ne anlama geldiğini yani her birinin muhtevasını, tanımını (ki tanım önemli demedi demeyin) bilmeli ve her bir değişkenin birbiriyle ilişkilerini inceleyerek aralarındaki bağlantıyı keşfetmeliyiz. Böylece veri setini anlamlandırmış olalım , anlatmak istediklerini bir çerçeve içerisinden ve hatta farklı pencerelerden görmek için yeni yollar bulabilelim.
Peki bu featurelar arasındaki ilişki nasıl çözülür?
“Regresyon(Regression)” ve “Kolinearite (multicollinearity)”ye bakmak önemli yollardan ikisidir. Hangisi önce değerlendirilmeli bu sevgili için derseniz, bize farketmez diyor kendileri. Sıralama önemli değil, yeter ki sen sor bu soruları ben uygun cevapları veririm diyor. Bu aşamaya gelene kadar ise yani regresyon ve kolineariteye bakmadan önce yapılması gereken işlemler var tabi. Evvela onların üzerinden şöyle bir geçelim, sonrasında onları da detaylandırmaya tabi tutarız başka yazılarda.
Veri ön işleme bunlardan biri yani verilerde bulunan eksik, hatalı ve gürültülü gözlemleri düzenlemek veya düzeltmek için bir ön işlem yapmak. Örneğin bir veri setinde normalleştirme, eksik değer atama gibi işlemler yapılması gerekli olabilir. Sonuçta yarım kalmış hiçbir şeyden net bir sonuç çıkmaz.
Bir diğeri ise ayrık ve sürekli değişkenleri yakalama işlemi ki veri setindeki değişkenlerin ayrık, sürekli ya da kategorik olup olmadığını belirlersek ona sorulacak soruları doğru tespit edip nabza göre şerbet verebiliriz ve böylece alabileceğimiz en munis ve olumlu cevapları da alabiliriz.
Bir başka adım da Outlier’ları belirleme işidir. Veri setinde norm dışı değerlere sahip gözlem olup olmadığını tespit ederek bu sevgilinin kafasında çok uçlarda kalmış senaryoları bertaraf ederek kafasının karışmasını engelleyelim. Zira bu noktalar sonrasında kurulacak olan modeli olumsuz etkileyebilir. Outlier konusunun tespiti de ayrı bir makalenin konusu olsun şimdilik.
Bu adımdan sonra sıra eğim analizleri yapmaya geliyor. İşte burda sevgili verimizle konuşmaya başlıyoruz. Eğim matematikte türeve eşittir diyebiliriz türev ise “bir denklemi bu uzayda anlayamıyorsan bir alt uzayda anlayabilirsin” der bize. Artık biz de verimizin alt uzaylarına inerek yani derinlerine bakmaya başlıyoruz. Eğim analizi, basit ancak etkili bir tekniktir. Regresyon analizine güçlü bir zemin hazırlar. Değişkenler arasındaki ilişkinin doğasını anlamak için ideal bir yaklaşımdır.
Eğim analizinde bağımlı ve bağımsız değişken ya da değişkenler belirlenir ve analiz etmek için değişkenlerin ölçü birimlerini gözden geçirilir. Eğer farklı ölçeklerde ve birimlerde değişkenler varsa, standartlaştırma yapılmalıdır. Aksi takdirde sonuç doğru ve anlamlı olarak elde edilemez. Sonrasında veriler üzerinde görselleştirmeler yapılır. Elde edilen eğrilerin yönü belirlenir özellikle doğrusal bir ilişki varsa eğim bize ilişkinin gücü hakkında net bilgiler verebilecektir. Örneğin eğim ne kadar dikse ilişki o kadar güçlüdür gibi
İşte burada bağımlı değişkenle bağımsız değişken arasındaki ilişkinin incelenmesinin yanı sıra bağımsız değişkenlerin de kendi aralarında değerlendirilmesi ve bu değişkenler arasındaki ilişkinin tespiti de çok önemlidir. Bu durumda bakılacak şey korelasyon durumudur .
Korelasyon, iki değişken arasındaki ilişkinin yönünü ve derecesini ölçen istatistiksel bir tekniktir. Korelasyon katsayısı -1 ile +1 arasında değer alır ve elde edilen korelasyon katsayısının değerine göre literatürde genelde aşağıdaki değerlendirmeler elde edilir.
• +1: Pozitif mükemmel korelasyon. Değişkenler arasında pozitif yönlü güçlü bir ilişki vardır.
• +0.7 ile +1: Pozitif yüksek korelasyon. Değişkenler arasında pozitif yönlü kuvvetli bir ilişki mevcuttur.
• +0.3 ile +0.7: Pozitif orta düzeyde korelasyon. Değişkenler arasında pozitif yönlü belirli bir ilişki vardır.
• +0.1 ile +0.3: Pozitif düşük düzeyde korelasyon. Değişkenler arasında pozitif yönlü zayıf bir ilişki mevcuttur.
• 0: Korelasyon yok. Değişkenler arasında ilişki bulunmamaktadır.
• -0.1 ile -0.3: Negatif düşük düzeyde korelasyon. Değişkenler arasında negatif yönlü zayıf bir ilişki vardır.
• -0.3 ile -0.7: Negatif orta düzeyde korelasyon. Değişkenler arasında negatif yönlü belirli bir ilişki mevcuttur.
• -0.7 ile -1: Negatif yüksek korelasyon. Değişkenler arasında negatif yönlü kuvvetli bir ilişki vardır.
• -1: Negatif mükemmel korelasyon. Değişkenler arasında negatif yönlü güçlü bir ilişki mevcuttur.
Korelasyon katsayısı (corelation coefficient), iki değişken arasındaki ilişkinin varlığını ve yönünü gösterirken nedensellik hakkında bilgi vermez. Nedensellik için daha gelişmiş analiz teknikleri gereklidir.
Korelasyon analizi (corelation analysis), veri analizinde değişkenler arasındaki ilişkileri incelemede ve keşfetmede kullanılan en temel yöntemlerden biridir ve birçok analiz tekniğinin de temelini oluşturur.
Eğer bağımsız değişkenler arasında yüksek korelasyona rastlarsak da kolinearite ortaya çıkmış olur. Bu durum bağımsız değişkenlerin birbirlerini doğrusal olarak tahmin edebildiği anlamına gelir. Yani aslında aynı sonuca varan değişkenlerin, sevgili verimizin yüreğine yük üstüne yük olması durumudur ki bu bir yığın birbirini tekrar eden veri yığını var demektir. Bir nevi kuru kalabalık oluşur diyebiliriz. Bu kalabalık yani kolinearite sorunu, regresyon modellerinde tahminlerin hassasiyetini azaltırken modelin anlamlılığını da düşürür.
Kolinearitenin bazı nedenlerini sıralayacak olursak eğer aşağıda ki nedenler elde edilebilir:
• Çok sayıda bağımsız değişken: Kullanılan değişkenlerin sayısı arttıkça, aralarındaki korelasyon olasılığı da artar. Yani hedefe ulaşırken oluşturulacak değişkenler (features) çok dikkatli belirlenmeli, sade ve yalın bir anlayış için tekrara düşmekten kaçınılmalıdır.
• Aynı ölçütü ölçen değişkenler: Aynı olguyu farklı şekilde ölçen değişkenler yüksek ilişki gösterir. Mümkün olduğunca ölçüm ve değerlendirmeler için bağımlı formüller içeren sütun değerleri oluşturulmamalıdır. Mesela bir sınıftaki öğrencilerin notlar toplamı ve öğrencilerin not ortalamalarının formülasyonu aynı değerleri kullanarak hesaplandığından oranlama sonucunda ortak yüzdelere ulaştırır.
• Doğal olarak ilişkili değişkenler: Nedensellik ilişkisi olan değişkenler birbirleriyle yüksek korelasyon gösterir. Bunun için nedensellik testleri yapılabilir.
• Yanlı değişken seçimi: Bağımsız değişkenler araştırmacının ön yargıları ve seçiciliği doğrultusunda belirlenmiş olabilir. Bu durumun varlığı kolinearite yol açabilir.
Kolinearitenin varlığının bize çıkardığı sorunlar nedir diye bakarsak eğer :
Standart hatayı arttırır. Bu durumu da tahminlerin hassasiyeti azaltırken ve güven aralıklarını genişletir.
Değişkenlerin etkilerini belirsizleştirir ve hangi değişkenin ne kadar etkili olduğu belirlenemez.
R2 değerinin yanıltıcı olmasına sebep olur ki yüksek R2 modelin iyi olduğu izlenimini verir ancak etkiler belirsizdir.
Tahminleri kararsızlaştırır. Küçük veri değişiklikleri büyük tahmin değişikliklerine yol açar.
VIF (Variance- Inflation — Factor ) değerlerinin yüksek çıkmasına sebep olur. Variance, Inflation, Factor değerleri kolinearitenin derecesini verir. Yüksek VIF, kolinearite sorununu gösterir.
Kolinearite sorununu engellemek veya azaltmak için çoklu korelasyon testleri yapılmalı, yanlı değişken seçimi önlenmeli, değişkenler birleştirilmeli ya da bazı değişkenler model dışı bırakılmalıdır.
Şimdi Regresyon (Regression) adımına geçelim ve regresyon nedir ile başlayalım işe.
Regresyon kelimesi geniş anlamda geçmişe dönüş veya gerilemeyi ifade eder. Psikolojide regresyon, bireyin daha ilkel ve olgunlaşmamış bir gelişim dönemine geri dönmesi olarak tanımlanır.
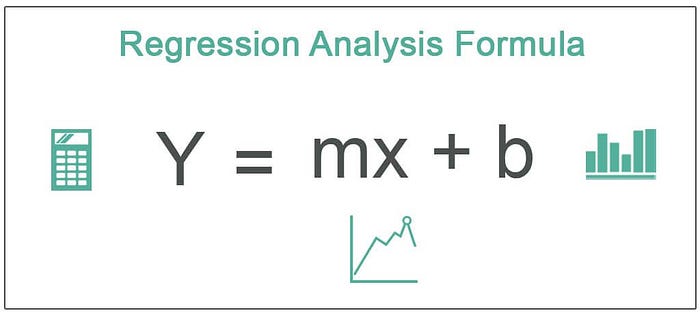
İstatistikte Regresyon, iki ya da daha fazla değişken arasındaki ilişkinin matematiksel olarak modellenmesi için kullanılan yöntemlerin genel adıdır. Regresyon analizi, bağımlı değişkende meydana gelen değişimlerin bağımsız değişkenler tarafından ne ölçüde açıklandığını bulmaya çalışır.
Regresyon kelimesinin gerçek anlamı ile istatistikte kullanılan regresyon kavramı arasında dolaylı bir bağlantı vardır.
Regresyon kelimesi sözlük anlamıyla ‘gerileme, geri gitme’ anlamına gelir. İstatistikte regresyon analizi ise iki veya daha fazla değişken arasındaki ilişkinin matematiksel modellenmesi için kullanılan yöntemleri ifade eder. Bu bağlamda regresyon, değişkenler arasındaki ilişkinin geriye doğru incelenmesi ve açıklanması olarak düşünülebilir. Yani nedenselliğin tersine işleyerek, sonuçtan başlangıç değişkenlerine gitmeyi amaçlar.
Regresyon analizinde amaç, bağımlı değişkende meydana gelen değişimin yüzde kaçının bağımsız değişken(ler) tarafından açıklandığını belirlemek ve bağımlı değişkendeki değişimleri bağımsız değişken(ler) kullanarak tahmin etmektir.
Bir regresyon modelinde;
• Bağımlı değişken: Açıklanmaya çalışılan değişkendir.
• Bağımsız değişken(ler): Açıklayıcı değişken(ler)dir. Bağımlı değişkeni etkiler.
•Katsayılar: Bağımsız değişkenlerin bağımlı değişken üzerindeki etki büyüklüklerini gösterir.
• Sabit terim: Bağımsız değişkenlerin etkisi olmadığında bağımlı değişkendeki değerdir.
•Hata terimi: Model tarafından açıklanamayan, bağımlı değişkendeki değişimin geri kalan kısmını temsil eder.
Regresyon analiziyle;
• Değişkenler arasındaki ilişkinin incelenmesi,
• Tahmin modeli oluşturulması,
• Gelecekteki sonuçların öngörülmesi,
• Karar verme süreçlerine katkı sağlanması
gibi çalışmalar yapılabilir.
Regresyon analizi, istatistik ve veri bilimi alanlarında sıklıkla kullanılan en önemli analiz tekniklerinden biridir. Birçok disiplinde, bilimsel araştırmalarda ve iş dünyasında yaygın olarak başvurulan bir yöntemdir.
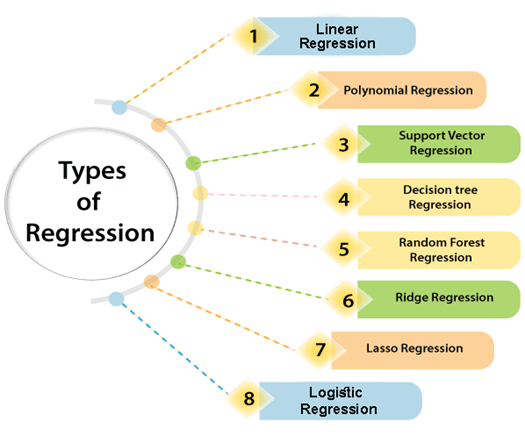
Regresyonun bazı temel türleri şunlardır:
- Doğrusal regresyon: Bağımlı ve bağımsız değişkenler arasındaki ilişkinin doğrusal bir modelle açıklandığı regresyon türüdür. En basit regresyon modelidir. (Unutmayın bir sevgili dümdüz ve basit cevaplarla genelde tatmin olmaz.)
- Çoklu regresyon: Bağımlı değişkeni tahmin etmek için birden fazla bağımsız değişkenin kullanıldığı modeldir.
- Lojistik regresyon: Bağımlı değişken kategorik olduğunda kullanılan regresyon modelidir. Sınıflandırma ve olasılık tahmini için uygundur.
- Polinominal regresyon: Bağımsız ve bağımlı değişkenler arasındaki ilişkinin doğrusal olmadığı, polinom denklemleriyle modellenebildiği regresyon türüdür.
- Ridge regresyon: Kolinearite sorununu gidermek için kullanılan ve doğrusal regresyona benzer bir modeldir.
- Lasso regresyonu: Yüksek boyutlu verilerde doğrusal modelleme yapabilmek için kullanılan bir yaklaşımdır. Değişken seçimi yaparak doğrusal modele uygular.
- Destek vektör makineleri (SVM-Support Vector Machine): Karmaşık ve doğrusal olmayan veri kümelerinde sınıflandırma ve regresyon için kullanılan güçlü makine öğrenmesi yöntemidir.
Tamam, buraya kadar verimizi anlamak, onu anlamlandırmak ve gözyaşlarını silmek ve hatta yüzünde tebessümler açtırmak için bir çok işlem uyguladık ve biraz da yorulduk. Peki bu kurulan regresyon modellerini değerlendirmek için nelere bakılmalı? Yani kurduğumuz matematiksel(duygusal) ilişki, sevgiliyi tatmin edecek mi ve biz onu gerçekten anlamış ve anlamlandırmış mıyız yani modelimiz ne kadar başarılı oldu, bunlara nasıl karar vereceğiz? :
R2, düzeltilmiş R2, standart hata ve F istatistiklerine bakarak tabi ki.
Bunun için sonraki yazıda görüşelim.








