Gradually improving our code quality with Test::Perl::Critic::Progressive
A few months ago, we introduced a new test into our test suite with the aim of gradually improving code quality.
This test will run on every branch that is pushed to our central git repository, along with our functional tests.
Unlike the functional tests, this one does not run the code and check it does what we expect. Instead it examines the code without running it, and checks it meets certain policies.
The aim is to gradually improve the quality of our code over time without requiring us to have a big clean-up phase.
Perl::Critic is available for free on the CPAN, and is packaged for a number of operating systems.
In this article I will explain how and why we are using Perl::Critic in our test suite and share a small test script that we’re using to get a balance between gradual improvement and readable feedback.
Why create a continuous improvement test?
Adzuna has been developed over a number of years by various developers. Over that time, the consensus about standards has changed.
At Adzuna we are always looking to improve the way we do things and one of the things we wanted to do was to improve the consistency of code.
As well as improving consistency, we all want to learn and improve continuously and this is quite an easy way to get lots of advice on best practices and how to avoid certain pitfalls.
Perl::Critic and policies
The tool we are using to check the code is called Perl::Critic. It’s been around for a few years, and for those used to other languages it’s equivalent to a “linter”.
Thanks to pluggable policies, Perl::Critic continues to evolve to this day. There are many policies distributed with the core Perl::Critic tool. Independent authors have also created policies available to download separately.
You can choose which policies to apply to your code with a configuration file called a perlcriticrc.
An example policy
Here’s an example Perl::Critic policy: Perl::Critic::Policy::InputOutput::ProhibitBarewordFileHandles.
As the name suggests, any code that makes use of a “bare word file handle” (an older style of Perl coding that is now deprecated) will violate this policy. The description of that module explains why:
Using bareword symbols to refer to file handles is particularly evil because they are global, and you have no idea if that symbol already points to some other file handle.
It also gives some examples to clarify:
open FH, '<', $some_file; #not ok
open my $fh, '<', $some_file; #ok
Test::Perl::Critic
The perlcriticscript that comes with the Perl::Critic distribution is designed to run interactively on your code while you’re programming. Its output is human readable and concisely lists the violations. The idea is that you run it regularly, so that you don’t have large numbers of violations.
That’s very useful and I recommend anyone wanting to improve their code and/or their knowledge of Perl and programming in general runs perlcriticduring development sessions.
But we don’t want to rely on remembering to do that check, so we wanted to add something to our test suite.
Fortunately for us, there is Test::Perl::Critic. This wraps Perl::Critic for Perl’s testing framework, which means that violations become test failures.
Each violation gets reported as a failure with a meaningful name and description in the test output (which becomes a test report in our continuous integration server).
It’s extremely easy to set up a Test::Perl::Critic test, and then all your code must pass your configured policies or your test suite will fail!
The output can be configured. In its most verbose format, the full explanation of the reason for the policy, with examples, will appear in the test report:
Test::Perl::Critic::Progressive
Wait a minute! We’ve got a large amount of code that’s been developed over years. We don’t want to have to fix all of the violations in one go. Sometimes the fix requires some care, as a rushed fix can introduce a bug in place of a stylistic perlcritic violation!
Fortunately for us, someone’s thought of that too. Test::Perl::Critic::Progressive remembers the numbers of each type of violation that you currently have, and only triggers a test failure when the number of violations increases from what it was before.
So the result is that we can leave our old code, which works fine, slightly messy. But new code — including changes to existing files that are compliant — must comply with our policies or the build will be flagged as a failure.
Progressive diagnostics
Unfortunately, when we moved to Test::Perl::Critic::Progressive we lost something useful. Where the test report used to list the violations, with description of the policy and examples, now it just says something like
InputOutput::ProhibitBarewordFileHandles: Got 7 violation(s). Expected no more than 6.It doesn’t give us the nice explanation of why we prohibit bare word file handles, and it also doesn’t tell us which of the 7 violations is the new one that caused the test failure.
There’s no way for Test::Perl::Critic::Progressiveto know which files have new violations without quite a bit of work on the internals of the module.
Time for a quick perl script
Fortunately for us, this is Perl, so we can whip up a quick script. As we’re using git, we know which files have changed, so we can run the plain (non-progressive) Test::Perl::Critic just on those files, which will give us the nice output and point us to which files have introduced the failure.
Here’s the script in full, with an explanation below:
The first thing to note is the irony of the messy BEGIN … no warnings … redefinition of another module’s internals, in a test that’s meant to be improving quality!
The first real action takes place on line 38. The progressive_critic_ok call will check if we have more violations than we previously recorded. If so it will log some test failures that look like
InputOutput::ProhibitBarewordFileHandles: Got 7 violation(s). Expected no more than 6.and return a false, value, so we go into the unless block. If we don’t have any new failures, we’ll skip to done_testing()
Inside the unless block is the real logic of this script. The if on line 40 checks if some environment variables are set. In the Jenkins job that runs this test on our master branch, we set these to match the previous and current build commit hashes:
CRITIC_DIFF_START=$GIT_PREVIOUS_SUCCESSFUL_COMMIT CRITIC_DIFF_END=$GIT_COMMIT our_test_runner.shSo if those are set, we’re on master. The useful information to give people is the list of failures in files that have changed since the previous successful commit. We get that list with a call to git diff on line 44.
If those environment variables aren’t set, we assume we’re on a feature branch. So the useful information is a list of failures in files that are different on this branch compared to master. A slightly different git diff on line 52 provides that.
Just in case we’re running with local (uncommitted) modifications, we run another variation of git diff on line 54.
We then iterate over all of the files we decided were useful, and run critic_ok on them. This picks up the configuration set on line 29, which gives us a very clear explanation of the violations. In the test result summary, we can see which changed files had violations:
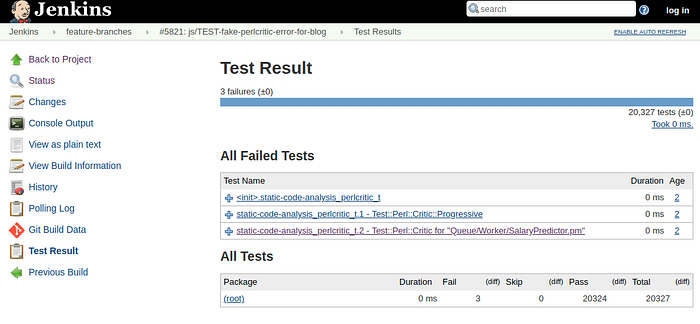
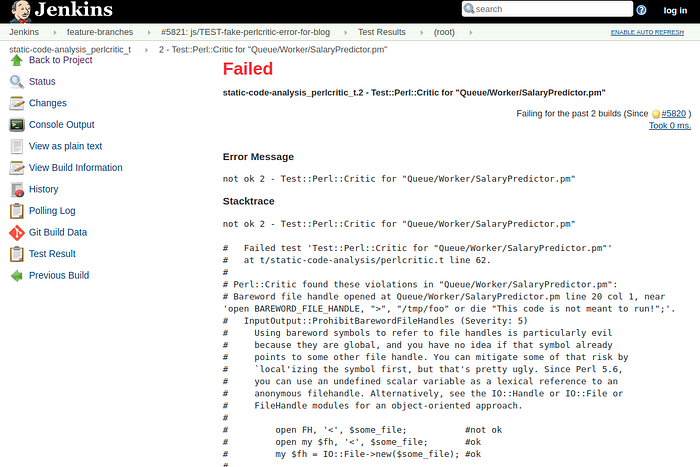
In the full report, the file name, line and column and an extract of the code where the violation was found is provided, along with the detailed explanation of the policy.
It’s not perfect, but it seems to be helping us avoid pitfalls and create more consistent code.
At present we’re only using a small number of the available policies. We plan to increase the policies applied as we get better at complying with the existing ones and feel confident that the diagnostics are sufficient.
Let us know in the comments if this is helpful to you and/or if you have a better way to achieve the goals!
Future developments
Having these tests is a great start. It stops us from adding new violations to the Perl::Critic policies we have enabled. We also need to ensure that we tackle the existing violations in a safe manner. One way would be to fix existing violations in code as we’re editing during feature development. This helps to ensure that the “fixed” code gets tested.
Although our test will stop us from merging more violations, it’s generally considered good to get feedback as soon as possible. Rather than developing a feature based on code with violations, then finding out the tests failed, it would be more efficient to tackle the violations earlier.
For faster feedback, I encourage people to run perlcritic on their code as they develop (with more policies than are enforced in our test), and perhaps to integrate perlcritic into their editor, see for example https://atom.io/packages/linter-perlcritic and https://marketplace.visualstudio.com/items?itemName=d9705996.perl-toolbox.
Further reading
Here’s a useful guide to getting started with perlcritic: https://perlmaven.com/getting-started-with-perl-critic
This is a more detailed introduction to Perl::Critic and policies: https://www.capside.com/labs/perlcritic-safe-perl/
This may be a useful strategy for cleaning up an old codebase (complementary to a Progressive test to avoid new violations): https://perlmaven.com/perl-critic-one-policy
Perl::Critic’s own documentation: https://metacpan.org/pod/Perl::Critic, including a list of the built-in policies.
The manual for the command line tool perlcritic : https://metacpan.org/pod/distribution/Perl-Critic/bin/perlcritic
https://metacpan.org/release/Task-Perl-Critic is a bundle that will install Perl::Critic itself plus some additional policies that are distributed separately.
Perl Best Practices, a book by Damian Conway, which inspired many of the first Perl::Critic policies: http://shop.oreilly.com/product/9780596001735.do
