Noisy Student: Knowledge Distillation強化Semi-supervise Learning
Self-supervised leaning與semi-supervised learning都是近年相當熱門的研究題目 (畢竟supervised learning早已發展到一個高峰)。其中,Noisy Student是今年 (2020年) 一個相當簡單而有效的semi-supervised learning方法。基於knowledge distillation與EfficientNet,透過不斷疊代的teacher student型態的訓練框架,將unlabeled data的重要資訊萃取出來,並一次一次地蒸餾,保留有用的資訊,進而提升模型的效果。
事實上,在做任何machine learning的問題時,data總是最關鍵的。data若是不夠多、不夠全面,訓練出來的模型很容易會有over-fitting的現象。然而取得更多的且全面的標註資料往往是繁雜的,蒐集unlabeled data則相較簡單許多,這就是semi-supervised learning的想法起點。

文章難度:★★☆☆☆
閱讀建議:本篇文章是只需要對 deep learning有些基礎概念,即使完全在 knowledge distillation零基礎的人也能閱讀的文章。文章前段從基礎開始介紹 knowledge distillation,後段則為介紹 noisy student的方法。
推薦背景知識: image classification、semi-supervised learning 、self-supervised leaning。
Knowledge Distillation (KD)
具我所知,KD (知識蒸餾) 最早是由Bucila提出 [1]。後來由Hinton完成一個泛用的里程碑 [2],當時 (2014年) ensemble model在衝數據時很流行,不過缺點自然是過大的模型與運算量。而Hinton透過KD展示了單一的模型是可以逼近ensemble model的效果,並且開啟了後續一個在分類問題中很重要的訓練技巧 label smoothing (soft target)與許多承襲teacher student架構的研究。
許多文章會把 KD解釋為一種 model compression的方法,這的確是 KD一開始概念的本意。不過隨著後續研究, KD已經不單純用於壓縮模型,更是一種可以強化模型表現的方法。
Soft Target and Its Regularizing Ability
Soft target是目前實現KD最常見的做法,以分類問題為例簡單解釋soft target大概是這樣:使用每個分類的probabilities取代原本的on-hot hard target做訓練目標。為了生成這個soft target的probabilities,使用 (但非唯一方法) 另一個預先用hard label訓練的網路,生成每個class的預測的機率,再把這個機率作為另一個網路的訓練目標。
再Hinton的論文中,在KD方法的部分在生成soft target的時候使用帶有temperature的softmax,並討論了不同temperature的設定對KD的影響。而論文中除了soft target以外,也會接受原本的hard target作為另一個訓練目標。

目前關於 knowledge distillation的研究幾乎都是圍繞著 soft target在走,甚至許多文章會將這兩者劃上等號,不過我個人始終認為, soft target只是 KD的其中一個實現方法。
而Hinton這篇論文的實驗數據有兩個亮點,其中第一個自然是distilled single model的表現非常地逼近10倍大的ensemble model。而第二個則是在小量數據下,使用soft target可以大幅地降低over-fitting的情況,也因此稱為soft target regularization。

對 soft target有興趣、想多了解一些的人可以再閱讀一下這篇在 NIPS 2019延續討論的論文 [4]。
Reversed and Defective Knowledge Distillation
如前述所說,以往的KD多半用一個較強的網路 (teacher) 教一個較弱的網路 (student) ,不過事實上並不一定要這樣。在Revisit Knowledge Distillation: a Teacher-free Framework [5]對另外兩個KD的例子做了密集的實驗:
- Reversed KD: 使用較弱的網路教較強的網路。
- Defective KD:使用沒訓練好的較強網路教較弱的網路。

而實驗結果上,這兩個方法都還是可以提升model的表現。
Noisy Student
Noisy Student [6]的出發點接近上述的reversed KD,使用不斷疊代的較弱網路去教導較強網路,並且透過可以移除的regularization技巧,讓teacher network擁有更多精煉的dark knowledge可以轉交給student network。
(2021.02.06 更新) 近期有讀者來信詢問 knowledge distillation、 soft label與 self-training之間的關係。
在 Hinton的論文中 KD確實指的是透過大的網路蒸餾知識給小的網路學習,並且未考慮 unlabeled data self-supervised的部分,然而在後期只要是網路教知識給網路,就會被稱為 KD。另一方面, self-training 則是強調對 unlabeled data 產生 pseudo label的部分。至於 soft label,就只是有沒有用 distribution 表示 hard label。
Noisy Student的演算法很簡單,就是一個不斷疊代的過程如下:
- 用有標註的資料訓練第一個teacher network。
- 用teacher network預測pseudo label (soft或hard label都可) 。
- 用這些pseudo label訓練一個一樣或更大的網路 (student network),並在訓練的過程增加noise,提高學習難度。
- 移除noise,回到第二步,並用新的student network取代原本的teacher network。
這邊訓練student network時有兩個重點:第一個是使用逐漸加大的網路backbone (EfficientNet [7]),讓student network的潛力至少大於等於teacher network。第二個則是在訓練student network時加上noise,增加學習難度,逼迫student network學習到更robust的資訊。這邊指的noise包含data augmentation (RandAugment [8])、dropout [9]、stochastic depth [10]。事實上,而這三個元件只是作者的選擇,或許並不是必須,重點是對於student network學習時提高難度。
實驗數據
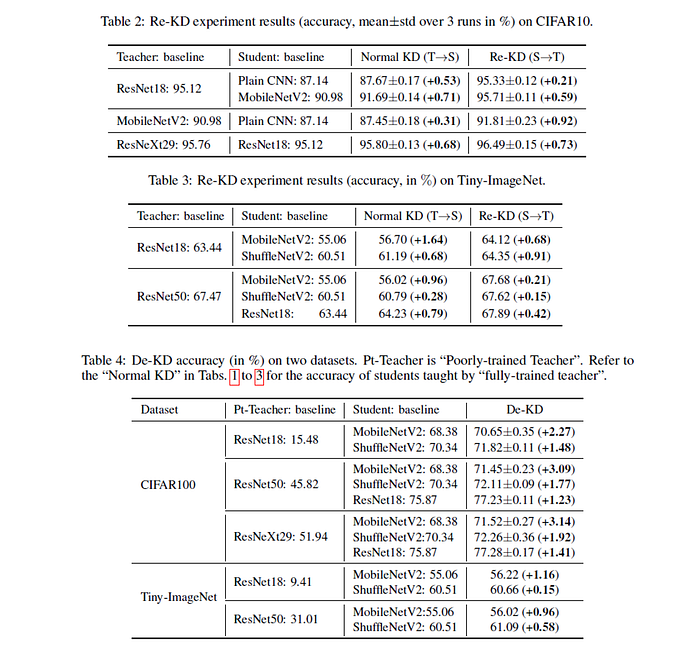
Noisy student的數據顯示了他的的確是一個運用unlabeled data的一個好方法,在額外使用JFT這個dataset的情況下 (不使用label),可以將ImageNet的準確度往上提高蠻多的,甚至比起Google Brain自己出的另外一篇論文,使用了更寬網路與JFT weakly labeled的的BiT還來的高。
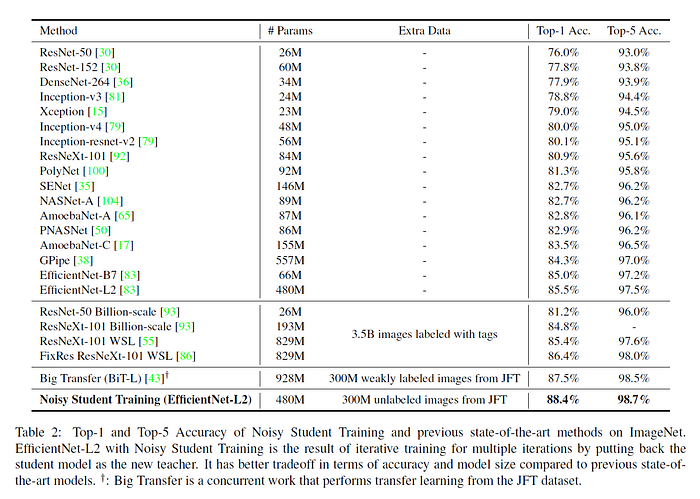
實際上Noisy Student最令人驚喜之處在於robustness的提升,這是一般accuracy看不出來的優勢。除了大幅刷新ImageNet-A、ImageNet-C與ImageNet-P的數據外,也在FGSM (fast gradient sign method) [11] 的adversarial attack下維持很不錯的水準。
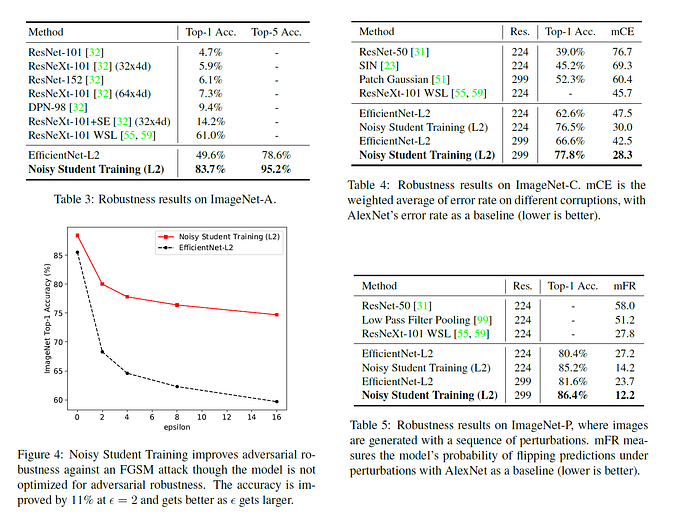
這邊稍微解釋一下ImageNet-A、ImageNet-C與ImageNet-P。
- ImageNet-A指的是natural Adversarial examples,是一些真實存在、但是對於網路相當困難的圖片 [12]。
- ImageNet-C指的是Corruptions,是指加了很強的noise、blur、pixelate等等影像畫質的破壞 [13]。
- ImageNet-P指的是Perturbations,影像全部是連續的MP4,包含各種來自連續影像的擾動 [13]。
至於所謂的 Top-1、 Top-5 accuracy,相信許多讀者已經熟知,不過還是補充一下。 Top-5指的是即對一個圖片,如果 softmax輸出的機率前五高的類別中包含正確答案,即判定為正確。而 Top-1就是沒有這個寬容值。
小結論
總覺得Google近年很喜歡做這種設計簡單、帶有總結性的論文:BiT總結了近年的pre-training觀念,SimCLR總結了近年self-supervised learning與contrastive learning,而本篇總結了knowledge distillation。
回歸主題,Noisy Student啟發於knowledge distillation,帶來了一個非常簡單、好用的semi-supervised learning方法,雖然在訓練流程有點繁雜,不過確實在使用unlabeled data上有相當的幫助。
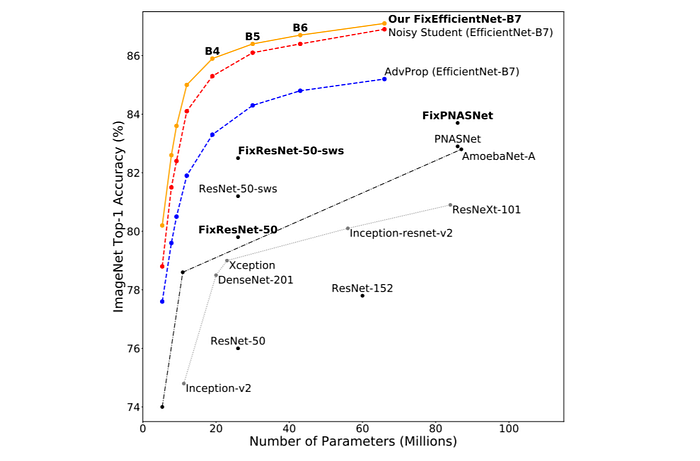
最後附帶一提,據我所知, Noisy Student目前 (2020年) 在 ImageNet上的成績是第二,輸給 FixEfficientNet [14] 一點點,不過兩篇方向不同,一篇是聚焦 SSL,一邊則是網路架構與概念的修正,而且 FixEfficientNet其實可以再直接套上 Noisy Student。
老話一句:Deep Learning領域每年都會有大量高質量的論文產出,說真的要跟緊不是一件容易的事。所以我的觀點可能也會存在瑕疵,若有發現什麼錯誤或值得討論的地方,歡迎回覆文章或來信一起討論 :)
關於Noisy Student挑戰pre-training地位與兩者之間的比較,可以參考:
關於Noisy Student的同期作品,同樣來自Google Brain的SimCLR可以參考這篇文章:
關於BiT與pre-training可以參考這篇文章:
References
- Model Compression [KDD 2006]
- Distilling the Knowledge in a Neural Network [NIPS 2014]
- Rethinking the Inception Architecture for Computer Vision [CVPR 2016]
- When Does Label Smoothing Help? [NIPS 2019]
- Revisit Knowledge Distillation: a Teacher-free Framework [arXiv 2019]
- Self-training with Noisy Student improves ImageNet classification [CVPR 2020]
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks [ICLR 2019]
- RandAugment: Practical automated data augmentation with a reduced search space [2019 CVPRW]
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting [JMLR 2014]
- Deep Networks with Stochastic Depth [ECCV 2016]
- Natural Adversarial Examples [arXiv 2019]
- Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations [ICLR 2019]
- Explaining and Harnessing Adversarial Examples [ICLR 2015]
- Fixing the train-test resolution discrepancy: FixEfficientNet [arXiv 2020]