SeqGAN: GANs for sequence generation

As the “artistic” capabilities of AI systems starting taking us by awe (the images on the left were generated by a computer program), people wondered — why not make it a “creative writer” too?! To understand what this entails, let’s discuss in brief about what GANs generally do and then in detail about SeqGANs.
Programming is a logic-based creativity — John Romero
GANs are capable of mimicking any distribution of data and can be taught to generate images, music, prose, etc.
A GAN is typically a team of two (neural networks) — A Generator and a Discriminator. Let us talk in terms of images.
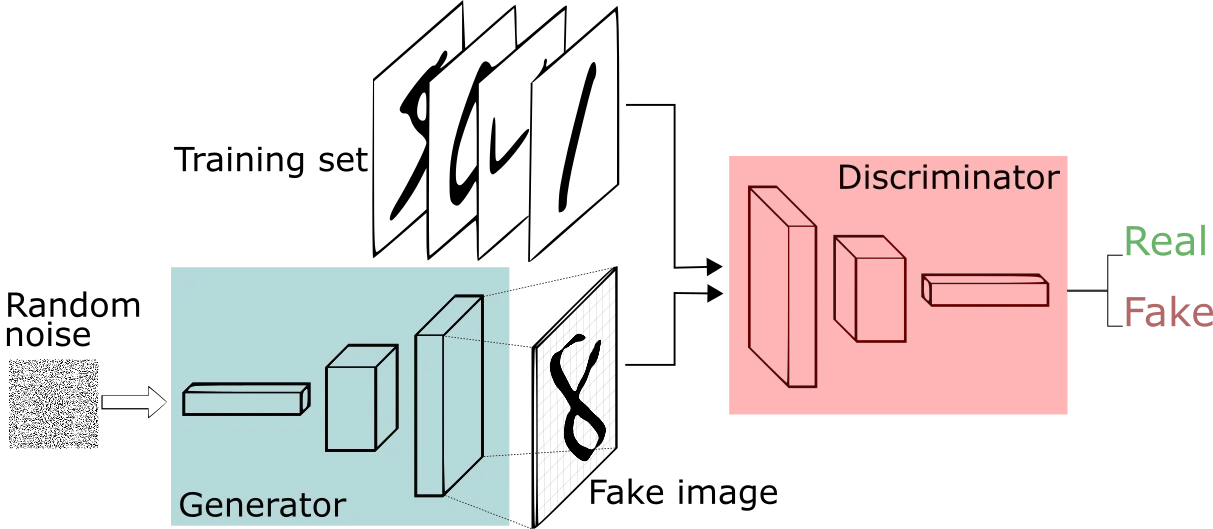
The Discriminator’s (D) goal is to be able to accurately classify an image as authentic or fake. The goal of the Generator (G) is to generate an image that appears so much like a real image that the D cannot classify it as fake.
G starts off by generating an image given some random noise (matrix of random values which need not be meaningful) and D tries to distinguish it from real images. The feedback from D is conveyed to G which then understands the classification of the current data it is producing and learns how to modify the data in such a way that it can fool D. However since D is provided with both real and fake data, it also learns how to get smarter and better classify the data that G generates. So the agenda for both is to fool each other. Typically when G is trained, D is frozen and when D is trained, G is frozen. Here is a more detailed blog for understanding GANs.
The above discussion concerns image (read real-valued, continuous) data. When it comes to sequential data (text, speech, etc), there are some limitations in applying the exact same concepts. These limitations arise mainly due to the sequential and discrete nature of the data. Let us discuss in the context of text.
Look at the 2 images below.

This is the image representation of a random matrix (M)
This is the image representation of M+0.08
Clearly, since images are composed of continuous, real-values, changing the matrix values starting from random noise, will still result in defined images that can be classified as real or fake by a discriminator.
Now consider the case in text. Typically text tokens (say, words) are represented by an “embedding-vector” of real-values. These vectors, though composed of continuous real-values, are discrete!
Suppose that the word “computer” is represented by the real-valued vector v = [0.11143, -0.97712, 0.445216 ….., 0.7221240]. Now, v + 0.08 is another vector which need not necessarily represent some word in the vocabulary.
So utilising the gradient of the loss from D with respect to the outputs of G to guide its parameters makes little sense. Thus the discreteness of text tokens is a hindrance to the usage of vanilla GANs for sequence generation.
Secondly, D can only classify and give the loss for an entire sequence. For partial sequences, it cannot provide any feedback on how good the partial sequence is and what the future score of the entire sequence might be. Since the concept of intermediate feedback/scores come into the picture, the G in the problem can be modelled as an agent of Reinforcement Learning (RL).
In SeqGANs, the generator is treated as an RL agent.
State: Tokens generated so far
Action: Next token to be generated
Reward: Feedback given to guide G by D on evaluating the generated sequence
As the gradients cannot pass back to G due to discrete outputs, G is regarded as a stochastic parametrized policy. The policy is trained using policy gradient.
In a stochastic paramterized policy, the actions are drawn from a distribution that parameterizes your policy. For eg., your action may be sampled from a normal distribution whose mean and variance will be predicted by your policy. When you draw from this distribution and evaluate your policy, you can move your mean closer to samples that lead to higher reward and farther from samples that lead to lower reward. The policy gradient integrates over both state and action spaces, whereas in the deterministic case it only integrates over the state space.
Now the objective of the generator model (policy) is to generate a sequence from the start state s0 in such a way that maximises the expected end reward. R_T is the end reward that is determined by D.

Y is the vocabulary of all words under consideration.
The expectation of getting the end reward R_T given the start state s0 and the Generator(parametrized by theta) is the product of the possible values of the reward(2nd term) and the probability of that value occurring(1st term).
Here term 2 is the action-value function. This function returns the reward value for taking an action (y1) from the state s0 following the policy G.
This action-value function is estimated by the discriminator. However, D only provides a reward at the end of a finished sequence. Yet, it is important that at every time-step, the fitness of both previous tokens as well as future outcome are considered. For this, the policy gradient used in SeqGANs employs a Monte Carlo (MC) search with a roll-out policy (P) to sample the unknown remaining tokens and approximates the state-action value at an intermediate step. An N-time MC search is represented as follows:

where Y(1:t) = (y1,….yt) and Y(t+1:T) is sampled based on the roll-out policy.
The roll-out policy(P) can be any; even G for simplicity.
The MC search with a start state s0 is a tree-search algorithm with a root node s0. This node is expanded by trying all possible actions belonging to the set of action states and constructing a child node for each of them. Now the value for each child node needs to be determined. For this, the remaining tokens are rolled out using the policy P until the entire sequence has been generated.
On reaching the end of the sequence, the discriminator gives a score which is then accumulated over each node of the tree. Information of how many times each node has been rolled out is also maintained. The score and the number of rollouts are then propagated back to the parent node. For a node, its accumulated value is the sum of the accumulated values of its children.

Read this for more understanding on the Monte Carlo rollout policy.
The discriminator value is the probability of the generated sequence being real
Thus, the action-value can be defined as follows:

where when there are no intermediate rewards, the function is iteratively defined as the next-state value starting from Y(1:t) and rolling out to the end.
Once G starts producing more realistic generated sequences, D is re-trained using the vanilla discriminator minimisation function.
G is first pre-trained using MLE on a training set of sequence data. G then produces negative samples for training D. D is pre-trained by minimising the cross-entropy loss. Then, the following steps are repeated until the SeqGAN converges:
- Use G to generate a sequence Y(1:T)
- For each time step t, calculate the action-value function reward
- Update the generator parameters via policy gradient
- Repeat 1–3 for g-steps
- Using current G, generate negative samples
- Combine above negative sample with positive samples from training set
- Train D using above combined samples
- Repeat 5–7 for d-steps
SeqGANs can be used for real-world tasks such as poem composition, speech language generation, music generation, etc. For more details, refer to the original paper.
