Different Types of Machine Learning Algorithm

- Supervised Learning : Supervised learning required traning labled data. In order to do classification , we need to first label the data and then use it to train in model to classify them in groups.
In supervised learning, we train your model on a labelled dataset that means we have both raw input data as well as its results. We split our data into a training dataset and test dataset where the training dataset is used to train our model whereas the test dataset acts as new data for predicting results or to see the accuracy of our model.
2. Unsupervised Learning : Unsupervised learning does not require labelled or classified data explicitly.
In unsupervised learning, the information used to train is neither classified nor labelled in the dataset. Unsupervised learning studies on how systems can infer a function to describe a hidden structure from unlabelled data. The main task of unsupervised learning is to find patterns in the data.
3. Reinforcement: Reinforcement is a type of dynamic programming that train algorithm using a system of reward and punishment .The agent learn by interacting with its environment.

Supervised learning classified into two categories of algorithms:
- Classification: Classification produces discrete values and dataset to strict categories. We use classification when we want our result to reflect the belongingness of data points in the dataset.
A classification problem is when the output variable is a category, such as “Apple” or “Banana” or “Red” and “Blue”.
- Regression: Regression gives us continuous results that allow you to better distinguish between individual point.
A regression problem is when the output variable is a real value, such as “dollars” or “weight”.
Unsupervised learning classified into two categories of algorithms:
- Clustering: A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
- Association: An association rule learning problem is where you want to discover rules that describe large portions of your data.
The most widely used Supervised learning algorithms are:
- Logistic regression.
- Linear regression.
- Naive Bayes.
- Support Vector Machines.
- Decision trees.
- K-nearest neighbor algorithm.
- Random Forest
Logistic regression
- Logistic regression estimates discrete values based in a given set of independent variables.
- It predicts the probability logit function who’s value lies between 0–1. It is a statistical method for predicting binary classes . The outcome or target will be binary in nature.
- It is a classification and not a regression algorithm.
- The logistic model is used to model the probability of a certain class or event existing such as pass or fail, win or lose, alive or dead or healthy or sick.

Linear Regression
- Linear Regression is one of the most simple Machine learning algorithm that comes under Supervised Learning technique and used for solving regression problems.
- It is used for predicting the continuous dependent variable with the help of independent variables.The goal of the Linear regression is to find the best fit line that can accurately predict the output for the continuous dependent variable.
- By finding the best fit line, algorithm establish the relationship between dependent variable and independent variable.
- The output for Linear regression should only be the continuous values such as price, age, salary, etc.
Naive Bayes
- Naive Bayes Classifiers assumes that the presence of a particular feature in a class is unrelated to the pressence of any other feature.
- Navive Bayes Classifiers consider all the properties or feature of the data to independently contribute to the prabablity of the certain class or event.

- This algorithm requires a small amount of training data to estimate the necessary parameters.
- Naive Bayes classifiers are extremely fast compared to more sophisticated methods.
Support Vector Machines
The goal of the SVM is to train a model that assigns new unseen objects into a particular category.

In SVM ,we creating a linear partition of the feature space into two categories.Based on the features in the new unseen objects, it places an object above or below the separation plane, leading to a categorisation.
This makes it an example of a non-probabilistic linear classifier.
.
.
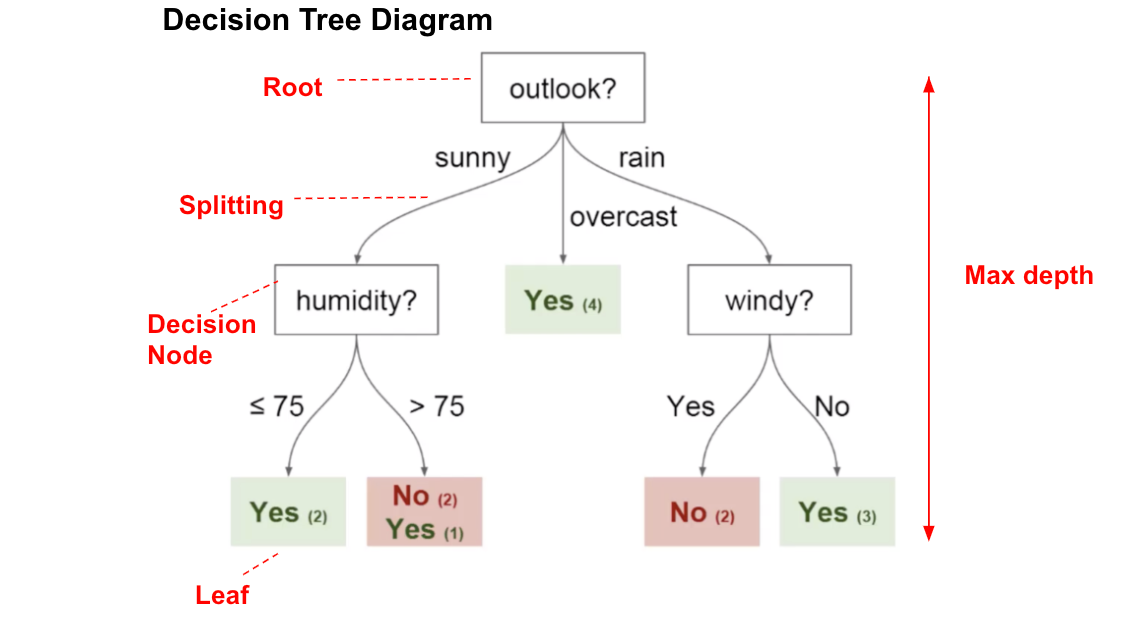
Decision trees
- Decision tree builds classification or regression models in the form of a tree structure.
- It breaks down a data set into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed.

- The final result is a tree with decision nodes and leaf nodes , leaf nodes represents a decision or classification.
- Decision trees can handle both categorical and numerical data.
.
.
K-nearest Neighbors (KNN)
K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure.
Classification is done by a majority vote to its neighbors.

The data is assigned to the class which has the most nearest neighbors.
As you increase the number of nearest neighbors, the value of k, accuracy might increase.
.
.
.
The most widely used Unsupervised learning algorithms are:
- k-means clustering.
- PCA (Principal Component Analysis).
- Association rule.
K- Means Clustering
- K-Means is one of the most popular “clustering” algorithms.
- k-means clustering is unsupervised clustering algorithm in which requires only a set of unlabelled points.

- The algorithm will take the unlabelled points and gradually learn how to cluster them into groups by computing the mean of the distance between different distigush point .
- K-mean uses perpendicular bisector between the centroids to divide the cluster into to different categories and then reassign the centroid untill we get all the data point categorisezed .
.
.
PCA (Principal Component Analysis)
- The goal of the PCA is to identify pattern in data and dectect the correlation between variable.
- PCA is a technique used to emphasize variation and bring out strong pattern in a dataset .
- It often used to make data easy to explore and visualize.
Here is the PCA of IRIS dataset~

— Navjot Singh
THANKS FOR GIVING YOUR VALUABLE TIME

{kind=link}
{kind=link}