THE DEFINITIVE GUIDE
Feature Selection: Embedded Methods
3 Embedded-based methods to choose relevant features
Embedded Methods
Embedded methods combines the advantageous aspects of both Filter and Wrapper methods. If you take a closer look into the three different methods, you may end up wondering what is the core difference between Wrapper and Embedded methods.
At first glance, both are selecting features based on the learning procedure of the Machine Learning model. However, Wrapper methods consider unimportant features iteratively based on the evaluation metric, while Embedded methods perform feature selection and training of the algorithm in parallel. In other words, the feature selection process is an integral part of the classification/regressor model.
Wrapper and Filter Methods are discrete processes, in the sense that features are either kept or discarded. However, this may often result in high variance. On the other end, the Embedded Methods are more continuous and thus, don’t suffer that much from high variability.
LASSO
Least Absolute Shrinkage and Selection Operator (LASSO) is a shrinkage method that performs both variable selection and regularization at the same time. I know, it sounds fancy but soon you realize it is just Linear Regression with L1 regularization. But let’s take one thing at a time, starting with L1 regularization.
Regularization is a process that shrinks the coefficients (weights) towards zero. What does that mean exactly? It means that you are penalizing more complex models to avoid overfitting.
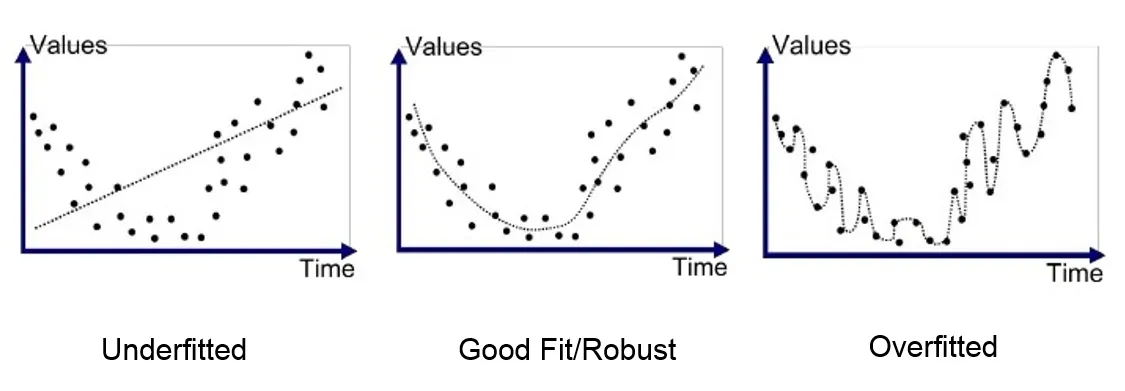
But how does this translate to feature selection? You may have heard of other regularization techniques like Ridge Regression or Elastic net, but LASSO enables coefficients to be set to 0. If a coefficient is zero then the feature is not taken into consideration, thus, it is in a way discarded.
Note: Elastic Net is the combination of LASSO and Ridge Regression. This means, that it can also perform feature selection. Ridge Regression cannot do that since it only allows coefficients to be very close to zero but never actually zero.

The complexity parameter lambda (λ) is non-negative and controls the amount of shrinkage. The larger its value the greater the amount of shrinkage, the simpler the model you are building. Of course, its value is a hyper-parameter that you should tune.
The idea of penalization is used in many algorithms including neural networks; we just call it weight decay.
Let’s see an example… I chose the Breast Cancer dataset from sklearn (binary classification task). There are only 569 samples in the dataset, thus, we will perform Stratified Cross Validation for each step.
from sklearn.linear_model import LassoCV
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFoldcancer = load_breast_cancer()X = cancer.data
y = cancer.targetskf = StratifiedKFold(n_splits=10
lasso = LassoCV(cv=skf, random_state=42).fit(X, y)print('Selected Features:', list(cancer.feature_names[np.where(lasso.coef_!=0)[0]]))

lr = LogisticRegression(C=10, class_weight='balanced', max_iter=10000, random_state=42)
preds = cross_val_predict(lr, X[:, np.where(lasso.coef_!=0)[0]], y, cv=skf)
print(classification_report(y, preds))
Feature Importance
Does feature importance ring a bell?
With a few lines of code, we can really get the gist of the feature space — extracting useful information — leading to a better and more interpretable model. There are 2 paths we can take; Tree-based Methods and Permutation Importance.
Tree-based Methods
Decision Tree, RandomForest, ExtraTree, XGBoost are some of the tree-based methods one can use to get the feature importance. My favorite ones are RandomForest and Boosted Trees (XGBoost, LightGBM, CatBoost) as they are improve the variance of simple Decision Trees by incorporating randomness.
But how?
To answer the question, I continue with Random Forest as my algorithm of choice. Random Forest uses mean decrease impurity (Gini index) to estimate a feature’s importance. The lower the value, the more important the feature is. Gini index is defined as:

where the second term is the sum of the squared probabilities of each class for sample i. The Gini index of feature j is measured for each node of a tree where feature j was used and averaged over all trees in the ensemble. If all the samples that reached the node are linked with a single class then that node can be called pure. Read more about it here.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
import matplotlib.pyplot as pltcancer = load_breast_cancer()X = cancer.data
y = cancer.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)rf = RandomForestClassifier(n_estimators = 100, class_weight='balanced', random_state=42)
rf.fit(X_train, y_train)importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]plt.figure()
plt.title("Feature importances")
plt.bar(range(X_train.shape[1]), importances[indices],
color="lightsalmon", align="center")
plt.xticks(range(X_train.shape[1]), cancer.feature_names[indices], rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.show()

This can give you a good estimate on the threshold value you want to set when selecting features based on their importance. I choose 0.06, this results in 7 features.
sfm = SelectFromModel(rf, threshold=0.06)sfm.fit(X_train, y_train)X_important_train = sfm.transform(X_train)
X_important_test = sfm.transform(X_test)rf = RandomForestClassifier(n_estimators = 100, class_weight='balanced', random_state=42)rf.fit(X_important_train, y_train)
y_pred = rf.predict(X_important_test)print(classification_report(y_test, y_pred))

You can repeat the same with any of the Boosted Trees algorithms by simply replacing
RandomForestClassifier()withXGBClassifier()
Permutation Importance
A not so well-known idea but still worth the exploration. The method permutes a feature’s values and then measures the increase in the model error. The feature is important if and only if the shuffling led to an increase. The steps are the following:
- Train the model as usual. Estimate the error:
L(y, f(X));L: loss,y: true target vector,f(X); estimated target vector. - For each feature
jin the input feature vector, generate a new input matrixX'where featurejis permuted — in order to break feature’sjassociation with target variabley. Estimate the error once again with the new input matrix:L(y, f(X')). Compute the importance by simply doing:L(y, f(X'))-L(y, f(X)). - Sort features according to their importance.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifierimport eli5
from eli5.sklearn import PermutationImportancecancer = load_breast_cancer()X = cancer.data
y = cancer.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)rf = RandomForestClassifier(n_estimators = 100, class_weight='balanced', random_state=42)
rf.fit(X_train, y_train)perm = PermutationImportance(rf, random_state=42).fit(X_test, y_test)eli5.show_weights(perm, features_names=cancer.feature_names)

I select features whose importance is higher than 0.08.
rf = RandomForestClassifier(n_estimators = 100, class_weight='balanced', random_state=42)
preds= cross_val_predict(rf, X[:, np.where(perm.feature_importances_>=0.008)[0]], y, cv=skf)
print(classification_report(y, preds))
This method is seldom used to select features, but rather for interpretability reasons.
What happens if we do not perform feature selection?

Mmmm 🤔 … ok, there is no obvious advantage concerning the performance. However, always keep in mind that every method resulted in a smaller feature space, which leads to faster training and more interpretable models. Thus, although we have not improved on the performance, we achieve same results by using 4 features instead of 30!
Conclusion
To the end of this series, we can conclude that Feature Selection is all about keeping relevant and useful features automatically through processes that we described over the different posts. We investigate the Feature Selection task from different points of view; from statistics to machine learning methods. Overall, it can lead to better models, which achieve higher performance and are more interpretable. Last but not least, having a subset of features enables the machine learning algorithm to train faster.
