Solving Open AI’s CartPole Using Reinforcement Learning Part-1
Q-Learning is the most basic form of Reinforcement Learning, which doesn’t take advantage of any neural network but instead uses Q-table to find the best possible action to take at a given state.
Background information
- Environment
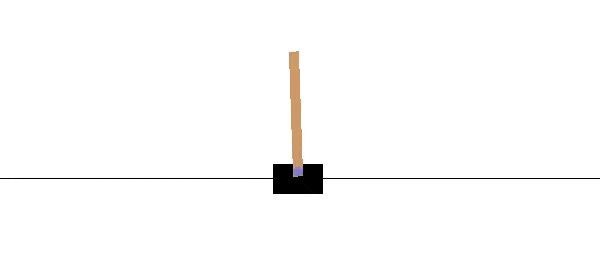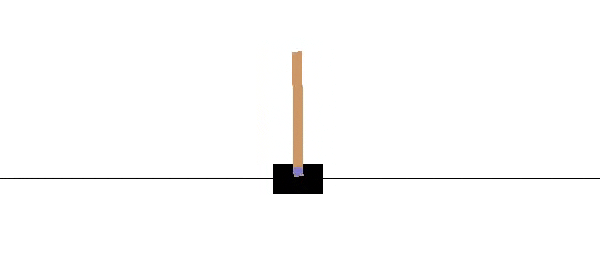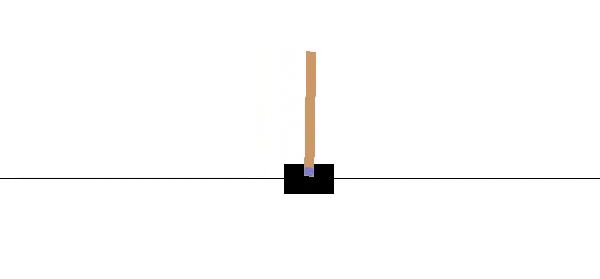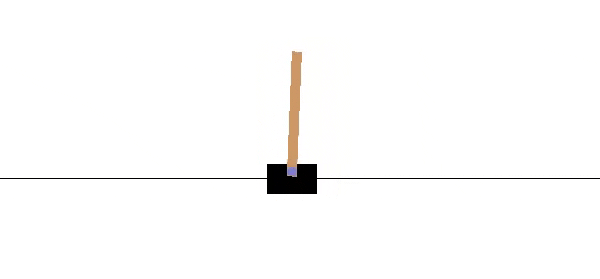
A CartPole-v0 is a simple playground provided by OpenAI to train and test Reinforcement Learning algorithms. The agent is the cart, controlled by two possible actions +1, -1 pointing on moving left or right.
The reward +1 is given at every timestep if the pole remains upright. The goal is to prevent the pole from falling over(maximize total reward) as in GIF above. After 100 consecutive timesteps and an average reward of 195, the problem is considered solved.
The episode ends when the pole is more than 15 degrees from vertical or the cart moves more than 2.4 units from the center.[1]
2. Q-Learning

In Reinforcement Learning agent is performing an action. As a result of it, the environment is giving back information about the state and reward.
