T5: a detailed explanation
Given the current landscape of transfer learning for NLP, Text-to-Text Transfer Transformer (T5) aims to explore what works best, and how far can we push the tools we already have.
Recently, there are lots of transfer learning techniques for NLP. But some techniques may work almost identical — just with different datasets or optimizers — but they achieve different results, then can we say the technique with better results is better than the other? Given the current landscape of transfer learning for NLP, Text-to-Text Transfer Transformer (T5) aims to explore what works best, and how far can we push the tools we already have.
Baseline model
T5 framework

Many tasks are cast into this framework: machine translation, classification task, regression task ( for example, predict how similar two sentences are, the similarity score is in range 1 to 5), other sequence to sequence tasks like document summarization (for example, summarising articles from CNN daily mail corpus).
T5 model structure
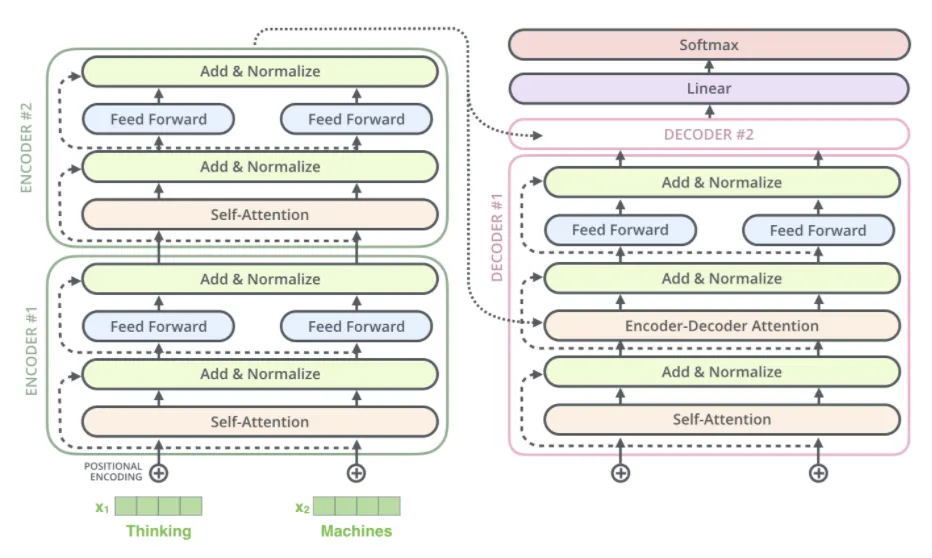
The mode structure is just a standard sort of vanilla encoder-decoder transformer.
Pretrained dataset

T5 uses common crawl web extracted text. The authors apply some pretty simple heuristic filtering. T5 removes any lines that didn’t end in a terminal punctuation mark. It also removes line with the word javascript and any pages that had a curly bracket (since it often appears in code). It deduplicates the dataset by taking a sliding window of 3 sentence chunks and deduplicated it so that only one of them appeared the dataset. For example, above 3 pages, the last paragraph on the middle page is removed since the same content appears on the first page. It ends up with 750 gigabytes of clean-ish English text. The dataset is publicly available on tensorlow.text.c4.
The unsupervised objective

With the framework, the model architecture, and the unlabeled dataset, the next step is to look for the unsupervised objective which gives the model some ways of learning from the unlabeled data. In the original text, some words are dropped out with a unique sentinel token. Words are dropped out independently uniformly at random. The model is trained to predict basically sentinel tokens to delineate the dropped out text.
Workflow

So the model pretrained based on Bert-base size encoder-decoder transformer with the denoising objective and C4 dataset, It trained 2¹⁹ steps on 2³⁵ or ~348 tokens with inverse square root learning rate schedule. Finetuning tasks include GLUE, CNN/DM(CNN / Daily Mail), SQuAD, SuperGLUE, and translation tasks: WMT14 EnDe, WMT14 EnFr, and WMT14 EnRo.


Next, different strategies in different settings were tried out to test how they influence performance.
Strategy comparison
Architectures


Fully-visible mask where every output entry is able to see every input entry. In the middle, there is a casual mask that is good for predicting a sequence due to the model is not allowed to look into the future to predict. The causal with prefix mask allows the model to look at the first bit of the input sequence as it with full visuality and then it starts predicting what comes next later on in the input sequence. The result shows that given the model bi-directional context on the input is valuable.

Objectives
Three objectives are concerned: language modeling (predicting the next word), BERT-style objective (which is masking/replacing words with a random different words and predicting the original text), and deshuffling ( which is shuffling the input randomly and try to predict the original text).

There are 3 options for corruption strategies: only masking tokens and do not swap tokens; masking tokens and replacing them with a single sentinel token; and removing tokens. The performance shows that ‘replacing corrupted spans’ strategy works best. What’s more, different corruption rates are applied and the result shows that unless a large corruption rate is taken (s.t. 50%), this setting is not sensitive to performance due to similar model performance with 10%,15%, and 25% corruption rates.


Given a good corruption rate, what happens if entire spans are dropped instead of iid decision being taken for each token ( IID decision: uniformly at random to decide whether we should corrupt the word or not). Basically at each position in the input, should a span of tokens be dropped and how long should that span be? Similar to the corruption rate setting, this setting doesn't influence performance a lot unless a large span of tokens is dropped (such as 10 tokens).
The highlight from this objective experiment is word corruption objectives tend to work best. Models tend to work pretty similarly with different corruption rates, and given this fact, it is suggested to use objectives that result in short target sequences since the shorter sequence is cheaper to do pretrain.
Datasets

Besides the clean-ish C4 dataset, the same data without any filtering also tried. The result shows that filtering does help the model to perform better. Other datasets with a smaller order of magnitude (which means more on some constrained domains) are also applied. Results show that pre-training on domain data helps downstream task performance. For example, pretrained model on RealNews-like dataset performed much better on ReCORD (a QA dataset on news articles) — the model pretrained on news tends to do better on a news QA task. The model pretrained on Wikipedia and TBC dataset (Tronoto book corpus) works better on multiRC dataset (a QA dataset that includes some data from novels).

What if the training dataset is limited and being repeated during training? How about setting these training steps? If you aren't going to be pertaining for that long, you might not have to worry about this. but if you start to repeat your dataset a bunch of times, the model can start to memorize your pertaining dataset (as bigger training steps lead to smaller training loss)and it causes a significant drop in performance on the downstream tasks
Multi-task

Instead of doing unsupervised pretraining and fine-tuning, the model is trained on multi-tasks. There are several mixing strategies. Tasks can be equally trained. The next option is to weight each dataset by the number of examples in the dataset as we don’t want to overfit the small dataset and underfit the big dataset. Because the unsupervised task is so big so that we need to set an artificial limit on how much we train on that task. This is what multilingual BERT does — sampling from different languages. We can also take these number of example proportions and apply a temperature to them to make then more close to uniform. Training equally on multi-tasks leads to worse performance. Setting threshold and temperatures correctly would have somewhat similar performance to the pretrained and fine-tuned setting. Especially on GLUR and SQUAD and superGLUE, there is a significant drop in performance when trying to train a single model on all these tasks at once.

Besides multi-task training, there are also other training strategies. Original one is pretraining on unsupervised tasks and fine-tuning on each individual downstream tasks. Another option is offered by MT-DNN: training on a multitask mixture and then fine-tuning on each individual task. This strategy closes the gap between unsupervised pertaining and fine-tuning. Leave-one-out multi-tasks training is pertaining on a multi-task mixture and then fine-tuning on a task which isn't used during pertaining. The result shows that this strategy still generates pretty good pretrained model. The final option is pertaining only on supervised tasks and fine-tuning on the same set of supervised tasks, which quite similar to what computer vision does. However, this strategy hurts performance pretty significantly.
Scaling
How to scale the model up? What if you are given four times as much compute, how should you use it? Should you train the model for longer, or use a bigger batch size, or train a bigger model, or train four models and ensemble them? Training the model longer does improve performance and this is one of the main things that Roberta did (pertaining to the model for longer). Making model bigger by making it both deeper and wider and training it two times as long also produces pretty significant gains. Training four models and assembling them also help a lot.

Putting it all together
After combining all these ideas together and scaling things up, the authors trained 5 variants: small model, base model, large model, and models with 3 billion and 11 billion parameters (which is by making the feed-forward layers wide). They achieved good performance except for translation. For translation, it seems like back-translation which is a very important ingredient for these state-of-the-art results works better than the English only pre-training. Noteworthy, superGLUE was designed to be hard for BERT but easy for humans. T5 performs very closely to the human level.


