Understanding Overfitting and Underfitting in Machine Learning
If you are just a “new one” in the field of Machine Learning, and you hear someone say “The model ain’t generalizing data well” Whoops! This is one of most important things we should Understand, and it is quite easy if we try to look at it Practically.
What does it say?
In machine learning, generalization usually refers to the ability of an algorithm to be effective across a range of inputs and applications.
Suppose that we are designing a machine learning model. How a model is said to be a good machine learning model? -> By checking if it generalizes any new input data from the problem domain in a proper way. This helps us to make predictions in the future data, that data model has never seen.
Now, suppose we want to check how well our machine learning model learns and generalizes to the new data. For that we have overfitting and underfitting, which are majorly responsible for the poor performances of the machine learning algorithms.
A model is good if it neither Underfits or Overfits.
It is okay if it is going over your head, we will slowly make it go into your head.
The basic Overview of how Machine Learning works is that we have the data, the data contains number of features(information) which are being used by models to predict the future. We train the model using the train data so it gets ready for predicting the future instances.
Underfitting
A statistical model is said to have underfitting when it cannot capture the underlying trend of the data. It’s like, what if I send a 3rd grade kid to a Differential Calculus Class, the kid is only familiar with the basic arithmetic operations. That is what it is! If the data contains too much information that the model cannot take, the model is going to underfit for sure.
It usually happens if we have less data to train our model, but quite high amount of features, Or when we try to build a linear model with a non-linear data. In such cases the rules of the machine learning model are too easy and flexible to be applied on such a minimal data and therefore the model will probably make a lot of wrong predictions.
Specifically, underfitting occurs if the model or algorithm shows low variance but high bias. Underfitting is often a result of an excessively simple model.
To understand what bias and variance is, refer to https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
Understanding of bias and variance will make your concepts more clear.
Overfitting
Overfitting occurs when a statistical model or machine learning algorithm captures the noise of the data. Intuitively, overfitting occurs when the model or the algorithm fits the data too well. Specifically, overfitting occurs if the model or algorithm shows low bias but high variance. Overfitting is often a result of an excessively complicated model applied to a not so complicated dataset.
Let us take an example of a Regression model:
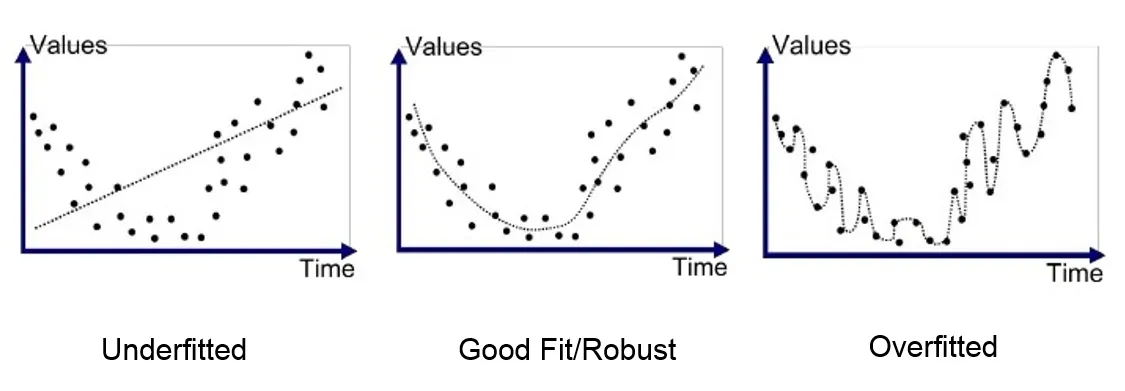
The pictures clearly shows the different ways the models are capturing the trend of the data, we can see that the underfitted model looks like it does not care where the data points are going, he just wants to go straight, don’t know where 😐. This is what happens when we apply a linear model to a non-linear data. It will not perform well neither perform good on the train data nor on the test data.
The overfitted model took the trend too seriously, it captured each and everything that is in the train data and fitting tremendously well. But, it does not mean it generalizes well, because it also captured the noise i.e., the information which does not tell us about the target function. It will give high accuracy on the train data, but that’s not what we want. It will collapse on the test data.
I think there is nothing to say about the Robust model picture we have 😃, this what a well generalized model looks like.
Same thing we can see on classification models:

How to avoid them?
Well, Underfitting is quite simple to overcome, it can be avoided by using more data and also reducing the features by feature selection.
But when it comes to Overfitting, we can either try to build a simpler model with more bias or there are various methods used, some of the common methodologies are:
Cross-validation
Cross-validation is a powerful preventative measure against overfitting.
The idea is clever: Use your initial training data to generate multiple mini train-test splits. Use these splits to tune your model.
In standard k-fold cross-validation, we partition the data into k subsets, called folds. Then, we iteratively train the algorithm on k-1 folds while using the remaining fold as the test set (called the “holdout fold”).

Cross-validation allows you to tune hyperparameters with only your original training set. This allows you to keep your test set as a truly unseen dataset for selecting your final model.
Train with more data
It won’t work every time, but training with more data can help algorithms detect the signal better. Of course, that’s not always the case. If we just add more noisy data, this technique won’t help. That’s why you should always ensure your data is clean and relevant.
Remove features
You can manually improve their generalizability by removing irrelevant input features.
Early stopping
When you’re training a learning algorithm iteratively, you can measure how well each iteration of the model performs.
Up until a certain number of iterations, new iterations improve the model. After that point, however, the model’s ability to generalize can weaken as it begins to overfit the training data.
Early stopping refers stopping the training process before the learner passes that point.

Epoch refers to the the number of iteration the model have been trained through. this technique is mostly used in deep learning while other techniques (e.g. regularization) are preferred for classical machine learning.
Regularization
Regularization refers to a broad range of techniques for artificially forcing your model to be simpler.
The method will depend on the type of learner you’re using. For example, you could prune a decision tree, use dropout on a neural network, or add a penalty parameter to the cost function in regression.
Don’t get scared if you don’t know the terms we talked about in the “How to avoid?” section, you will become familiar with them eventually when you’ll learn the intuition behind more and more machine learning algorithms, just let it go for now.
