THE ULTIMATE GUIDE
Your Handbook to Convolutional Neural Networks
The Whats and Hows in CNNs answered in simple English for all readers to understand.
With CNNs slowly being implemented in our daily routines, from search recommendations to analyzing security cam footage, what does a CNN consist of that makes it so intelligent? Every concept of CNNs explained in simple English.

- What Is A CNN?
- What Are the Current Uses of CNNs?
- The Basic Layout of a CNN
- How Do CNNs Work?
- Kernels
- Strides
- Pooling
- Flattening and Prediction
- Summary
- Sources
- A Personal Note
What is a Convolutional Neural Network (CNN)?
As the quarantine days become boring, you attempt to spice up your day by solving a 500-piece puzzle. Because it had been sitting under your bed for quite a long time, the cover photo on the box is all scratched out. Only leaving you and your senses, you try and identify what it depicts. A couple of puzzle pieces start to match, which creates features in the puzzle that give you an insight into the outcome. This is considered a convolution.
A convolution is a process of extracting features from an image by altering the picture.
But, the formation of a few puzzle pieces doesn’t really tell you the final result; it might as well be a dog or a cat. So, you keep matching groups of similar puzzle pieces that ultimately attach. One convolution is rarely enough, so several convolutions are necessary for a CNN to display valuable features.
A Convolutional Neural Network is a form of deep learning that used to analyze images and detect patterns using convolutions.
To perform this, CNNs use a series of convolutions on the input image to obtain a prediction.
CNNs can be considered unsupervised — clustering, or supervised learning — classification, depending on what the requirement is. But generally, it’s supervised.
Uses of CNNs
The most prevalent use of CNNs is for image classification. One prime example is classifying handwritten digits, classifying whether a picture is a dog or a cat, among many others.

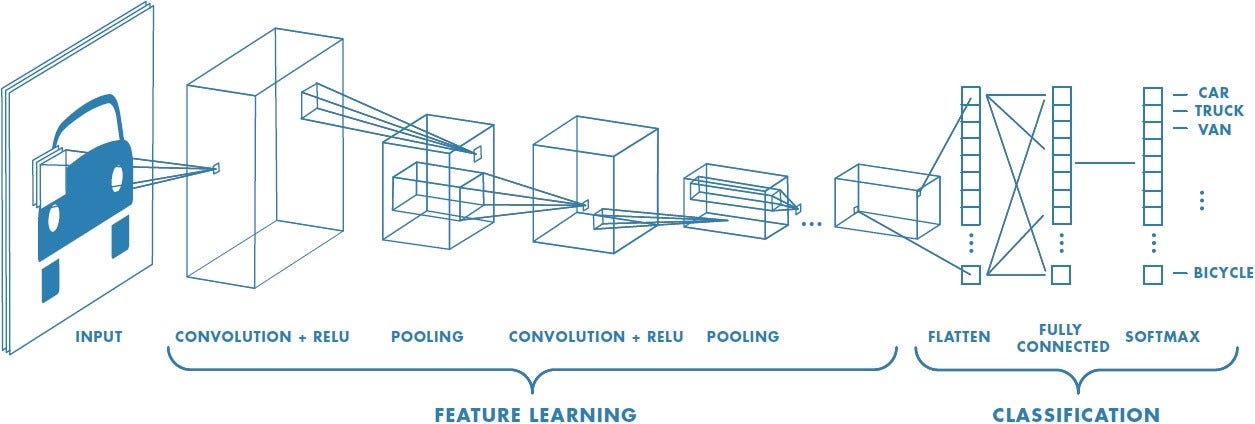
The Basic Layout of a Convolutional Neural Network

CNNs have an input layer, some hidden layers, and an output layer that outputs the transformed input—the hidden layers inside a CNN use filters. Filters are detectors for patterns. In the beginning, the CNN only starts to detect edges and shapes. As the algorithm progresses, it starts to detect tangible objects, such as an ear.
How Do Convolutional Neural Networks Work?
CNNs are mainly dependent on convolutions to extract features and produce a sufficient output. The first type of convolution is a kernel. A kernel is nothing but a filter that is used to extract the features from the images.
When we read a book, we extract meaning from the text by reading from left to right. Similarly, a kernel extracts features from the input image from moving left to the right.
Likewise, we tend to absorb information per word, not by reading each letter. Similarly, kernels extract features by a set of pixels at a time.
The most common form of kernel used is a 3 x 3, shown below.

As you may know, each pixel in an image comes with a number value in the range of 0 to 255. For colored images, it’s determined in three channels: red, blue, and green. The higher the number value, the more intensity the pixel produces.
As mentioned before, kernels also have a value associated with each of its blocks.
Using Kernels
Most of the mathematical calculations in many Neural Networks include a thorough understanding of linear algebra and calculus. However…
using kernels is as easy as multiplication and addition!
Let’s break it down. The kernel has a matrix of 3x3, and the red numbers in the yellow boxes are the filters. As you can see, the input pixels are being multiplied by their corresponding filter number, and then those 9 multiplied numbers are being added together.
In other words, 9 input values get individually multiplied and added to become 1 output value, which then becomes part of the convolved image.
For example, for the first set of pixels:
If we use the value of the input image at [1,1] and multiply this at position [1,1] of the kernel, we get 1. And then, we multiply the input image at [2,1] by position [2,1] of the kernel, we get 0.
Basically, (1*1)+(1*0)+(1*1)+(0*0)…=4.
Doing that until we have used all the values in the 3x3 kernel, the corresponding output spits out: 4.
And because of the overlap in the numbers, the convolved image is more accurate and has more pixels (compared to perhaps using a 5x5 matrix or a larger stride).
Strides
Images contain thousands of pixels is bound to contain all sorts of data. Attempting to process an abundant amount of pixels is computationally expensive and difficult to debug and organize. This imposes the ideal time to use the stride parameter.
Striding defines the number of pixels by which the kernel should move in either direction

In this illustration, the stride is [1,1]. This tells the kernel to move 1 pixel right while moving along the row and move 1 pixel down while moving around the column. The output is a 3x3 image.

In this illustration, the stride is [2,2]. This tells the kernel to move 2 pixels right while moving along the row and move 2 pixels down while moving around the column. The output is a 2x2 image.
As depicted, the larger the stride, the smaller the feature map (or convoluted image) is. On that note, strides are significant to CNNs because they are used to shrink the image size drastically.
Pooling
If deducing to 1/4 of the input image is enough to determine what the whole image displays, there is no point in processing all 4/4s of the image. This is where pooling plays a role.
Pooling is used to reduce the size of a feature map.
Like kernels, pooling moves a n x n filter (i.e., 3x3 filter) over the features and takes one value determined over the input pixels. That one value can be found in several ways: it may be the maximum of the input pixels (Max Pooling), the sum of all the values (Sum Pooling), or the average of all values (Mean Pooling). The most commonly used type of pooling is Max Pooling.

Flattening and Prediction
Once the algorithm has used many different kernels and pooling techniques, it’s time for the prediction. At this point, the algorithm can now detect eyes, ears, whiskers, and a face. Now, all it has to do is predict that the image is of a cat. That’s where flattening comes into the picture.
Flattening is the function that converts the pooled feature map to a single column that is passed to the fully connected layer.


After flattening, the flattened feature map is passed through a neural network. This step comprises the input layer, the fully connected layer, and the output layer in an Artificial Neural Network (ANN). The output layer is where we get the predicted classes. The information is passed through the network, and the error of prediction is calculated. The error is then backpropagated through the system to improve the prediction.
As confusing as this may sound, flattening is a simple concept to grasp, automatically clicking after re-reading a few times. Flattening is important to convert the extracted features from the convolutions into an actual predicted output that the algorithm spits out.
But how do we build a CNN? Keep an eye out for the next article for an in-depth walkthrough of building a CNN.
Summary

- A CNN analyzes images and extracts important features
- Convolutions are traits that alter the input image in a way that extracts important features, which can then be fed through an Artificial Neural Network (ANN).
- CNNs go through filters, which are the main guide to extracting features such as horizontal lines, vertical lines, and curves
- Striding is used in kernels that determines how many boxes the filter moves across the image. The larger the stride, the smaller the image is.
- A feature map is a convoluted layer or a layer that has already gone through convolutions.
- After, pooling is used. Pooling is used to reduce the size of the feature map.
- Flattening is vital for the feature maps to be used in ANNs. From there, the ANN predicts classifications, clustering, image segmentation, etc.

{kind=link}
{kind=link}
{kind=link}
{kind=link}