Thoughts on Clean Architecture
As an Android developer, software engineer, technology enthusiast, I’m always working hard to write elegant and clean code. I read books, articles, listen to talks, and try to pass on the knowledge as best I can. Clean architecture isn’t just a new buzzword, there are several articles from old to new (here’s one I prefer), from very high level to actual implementations, but somehow none of them gave me an idea on how to actually apply it. Because of this I started experimenting, learning high level architecture concepts, talking with experienced engineers, exchanging ideas. I’m going to introduce you to some of the concepts and practices that will help you achieve a clean architecture, from an Android developer’s perspective.

Design principles haven’t changed much in the last decade of computer programming, most of the ideas in this article have been around for more than that. If you’re an experienced engineer, you’re already versed in every principle and pattern there is a book about, but that will still not help you when there’s pressure to ship a feature, and your codebase is a couple of years old (full of technical debt).
Requirements change faster and faster these days. In order for us (the developers who implement these requirements) to keep up with them, we’ll need to shift our ways of coding, to be more agile, and I’m not talking about implementing some form of agile process. I’m talking about “Cost of change”. This metric usually increases over time on every project as it accumulates technical debt. You need to stay ahead of your customers needs and be proactive instead of reactive. That cannot be achieved if a refactor takes months to implement.
Read a lot of technical books, articles, wikis, watch recorded videos of tech talks, go to as many tech events as you can, but always take any advice given or technique with a grain of salt, even this one.
There’s plenty of articles around Android app architecture from MVP and Reactive techniques to Redux like systems and many more. Even ones that promote some form of Clean Architecture. While I appreciate the authors writing them, I’d like to propose a different approach.

Concepts
Dependencies and inversion
Most analysis tools report and allow you to visualize dependencies between packages/classes because it’s the easiest way to keep your codebase in check. If you have an unwanted dependency you invert it, using a simple interface (Dependency Inversion). Your code base should be free of cyclic dependencies as well. There are tools you can use to maintain dependencies including in Android Studio. Understanding dependencies and which direction they should point is important and you should spend some time familiarizing yourself with these tools.
Volatile vs Rigid components
Picture a graph of classes and arrows pointing in the direction of dependency. Whenever there’s a dependency towards a class and that class changes, the classes that depend upon it will most likely change as well. As a class gains more dependents it becomes more rigid (harder to change), when it doesn’t have any dependents only dependencies it’s more volatile (easier to change).

Frameworks and 3rd party libraries
You can say for certain that a piece of code that you’re not in control of, will make your life harder, it’s not a matter of if, just a matter of when. Think about how many times you needed to change a third party library because it didn’t meet all of the criteria, or had so many issues and backward compatibility problems that maintaining your codebase wasn’t feasible. This also goes for frameworks that solve a short term problem for you, or speeds up development time until your codebase gets bigger and requirements change so much that the framework just doesn’t cut it anymore. By this time changing it would mean you have to rewrite the entire app. If these situations apply to you, there’s a solution: keep every class that uses third party libraries and frameworks (in my case even Android components) volatile. It will be easier to change or replace completely.

Layers and boundary
If you look at any high level architecture you’ll see layers and interactions between these layers. It may seem very complicated to implement at first but it’s actually not “rocket surgery”. You just need to figure out the boundary classes that need to be used and how they interact.

Each architecture proposes different types of layers, different stacking orders, and different types of boundaries. Let’s see some and talk about why they aren’t good.
Database as the single source of truth
I’ve seen a ton of applications use an approach where the database was the first decision ever made when creating the architecture. People usually think of architecture as a collection of frameworks, libraries and database management systems. Robert Martin proposes that these sort of technical decisions should be deferred, and have them abstracted. Maybe you don’t even need a db for certain features, and just a simple memory cache is enough. It certainly is enough to unit test your logic. The real problem appears when you realize that the DB framework you decided to use a year ago is not suitable for you application. By this time a years worth of code can be a hard thing to change.
Using THE framework
This is true for most apps. When you look at the directory structure and files of a project, the first thing you see is the framework itself. Everything is arranged in packages or folders that are modeled for that framework. For web you mostly see MVC like structures, you have packages for Controllers and Models and Views but in order to understand what the application does you need to read a bunch of code first. This statement is true for Android apps as well. Most apps have a package where every activity or fragment is implemented. The worst part is that because of this people are tempted to use packages to put classes that have the same function together instead of classes that have the same reason to change. For example a “LoginFragment” and a “ProductDetailFragment” have the same function but don’t have the same reason to change. The LoginFragment and a CustomLoginButton will have the same reason to change (the UI needs to be updated with a new branding). This can quickly get out of hand even for small apps.
Uncle Bob’s clean Architecture
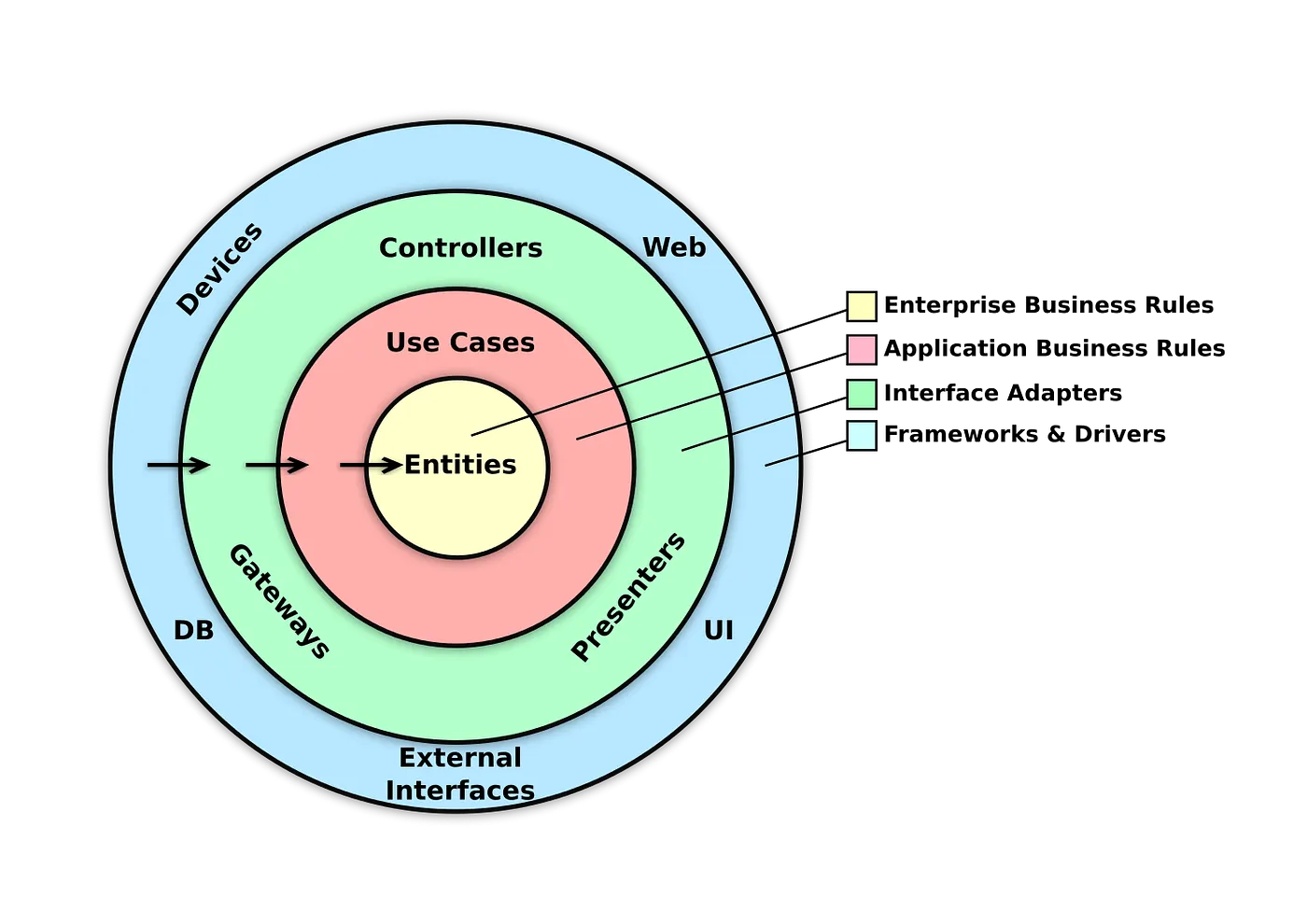
This is an overview of the architecture proposed by Robert Martin. What you don’t see in this diagram is that beneath these layers, packages are structured based on “use cases”, and you can clearly see what the application does with a simple glance at the packages and classes.
Separation of concerns
In the picture above with Clean architecture you can see that “Frameworks and drivers”, UI, DB and Networking related classes are all in the same layer, however these shouldn’t depend on each other.
I propose we change the representation with the following, to make this clearer.
Classes belonging to the DB should have nothing to do with the UI or the Networking components. They can and should be isolated. This concept can also be found in the Hexagonal architecture, in which you have a core application and plugins connected via adapters.
Responsibility
Layers and architecture is meaningless if we don’t take special care in assigning clear responsibilities. Some concept are floating around discussions like UIs should be dumb, Entities should not contain logic and many more. I’d like to reiterate them and clear up some misconceptions.
UIs should be dumb in the sense that they should not contain application logic, but they are responsible to format, and make decisions on how to present them to the user. These decisions are not part of the application logic, and also not part of the presenter layer, since the presenter should not know anything about how the UI is structured. Another thing the UI is responsible for is navigation since it’s the only component that should have enough knowledge about the UI’s structure. A “dumb” UI means that every user interaction like a “click on button x” needs to be translated into an “intention” that the “controller” can understand: “do something with X”. In case of Android the UI means the classes extending from Activity, Fragment. View, etc.
A controller takes a user intention and passes the necessary data to use cases that will make the actual computation.
The use case will implement high level policies that facilitates the interaction with different abstractions, it will fetch data from the db and the network via gateways, and use the presenters to pass the result back to the user.
Presenters should also be “dumb”. They should have no knowledge about the structure or anything else about the UI. I’ve seen a lot of examples that violate this convention. A dumb presenter will have the advantage that the UI can change while everything else in the system remains the same. This is especially important since UI updates are the most frequent in many applications.
The communication between the UI, controllers, use case and presenter is similar to every other communication channel, you just name them differently (e.g Gateways).

The Entities layer contains enterprise level policies. This is a bit confusing, because most people use entities as a term for POJOs modelling the database or the network calls. Then there’s the rule that they shouldn’t contain logic. That’s true if you’re thinking about using them that way. Truth is entities layer in the clean architecture diagram represent something else. To understand the concept let’s step outside the context of an application and think about the business. A retailer might have 3 mobile applications, an app for clients, an app for employees and an app for suppliers. The apps have different functionalities but they all have the same business in common, the entities layer could be reused in all 3 apps as they contain enterprise level policies and rules, while everything else that’s application specific goes in the use case layer. These rules could contain logic. Calculating tax is the same in each application.

A common mistake in Android applications is the over-use of the SDK. The Android framework is just that, a “framework” and it should be present only in the outer layer of your code. It has UI components, gives you access to sensors, storage and network among other things. If you take another look at the diagram, all of these have an abstraction behind them. This means everything but the last layer can be reused, extracted as a library. The application itself can run on the console if you want it to (just by implementing the necessary interfaces).
Resulting traits of a clean Architecture
Writing code in the manner described above has some advantages:
Everything starting from the “interface/adapters” layer can be easily tested. And your not only making it easy to test, but you’re not relying on anything but pure logic, no IO operations, no frameworks that need to be up and running, no UI. Automation can handle the rest.
You can easily change any 3rd party library or even the entire framework, since these are in the outer most volatile layer. This also means when you’re building the app you don’t need to decide which libraries you will use, what kind of storage. The UI can be swapped out without affecting the underlying logic.
Developers who are unfamiliar with your codebase can easily find and understand what’s going on. This is a result of structuring based on use cases instead of the underlying frameworks. There’s a term for this called “screaming architecture”, you can find a great article about that here.
Final Thoughts
You might find this approach to be overkill, or have a different pattern in mind when it comes to architect an app. The Clean Architecture approach will save you from the day to day frustrations you probably have with your current one. If you’ve tried it, let everyone know how awesome it is, and share this article.