資料工程師們到底在做什麼?

現代軟體工程師種類繁多,你可能聽過網站前端、後端工程師,聽過 Android、iOS 工程師,也聽過資料科學家,可能還聽過 DevOps、SRE、Security、DBA … 等等職位,但其實還有個職位叫做資料工程師 ( Data Engineer ),似乎較少人知道。所以今天來聊聊這個有趣的職位到底在做什麼吧!
有人說這不就 DBA 嗎?或後端工程師的職責之一?其實也不算差太遠,過往差不多就是這樣,如果五年前搜尋這個職缺,會發現 JD 內容五花八門什麼都有,有的要你會 SQL ,有的要 R,甚至 excel 也有,直到近幾年才開始拆分的比較清楚,成為一個比較專指做某件事的職位。
要知道一個職位怎麼來的,其實可以從他的歷史演進來看,就會知道為什麼會出現這樣的崗位,還有他的責任到底是什麼,今天就讓我們快速的隨著 Web 應用軟體的演進,看看這些職位怎樣出現的吧。
1. 那個一切事情都可以由一個人完成的美好年代

可能 199x~200x 那個年代,網際網路興起,許多軟體工程師就一個人把整個網站搞定了。
2. 直到有一天,發現事情實在太多了…是不是該來分工一下啊

前後端的概念出現是很自然的,畢竟負責的領域差異很明顯,要學習的東西也不同,專業分工之下就被分開了,之後當然還出現了 mobile 端,但我們可以把他也當成廣義的前端看待,所以這邊的 Front-End 可以看成 Web-Front-End、android、iOS 的統稱,甚至諸如電視、智能手錶、電子看板… 等等有關畫面呈現的都可以納入。當然一直到現代,也還是有許多的全端工程師一人搞定全部,可能在小新創,或自己當 freelancer,但大多數公司已經傾向分別找不同人來處理。
3. 然後,大數據時代來臨了

資料科學家 (Data Scientist),在 2012 年被稱為21世紀最性感的職業而爆紅!本來的定義是可以用資料產生價值的人,不過後來有點變成專指做機器學習 (Machine Learning) 與人工智慧 (Artificial Intelligence) 的人。其實更早之前也有各種資料分析的專家,但大多使用統計技巧,也比較常被稱作資料分析師 (Data Analyst)。總之就是給他資料,他就能給你各種神奇的東西,滿足你所有的幻想(?)
4. 資料科學家表示:請給我更多資料

資料科學家與大數據,算是雞跟蛋的關系了,當資料的儲存越來越容易,催生出了可以用海量數據產生出價值的資料科學家,而他們的出現也同樣開始研究各種資料的使用技巧,並要求更多的資料來提供他們實現模型。此時通常是後端工程師擔起了這個角色,幫他們收集各種各樣的資料,諸如使用者行為、個資、自然環境、政府機構…等等。由於你也不太知道哪些資料突然就能派上用場,儲存又相當便宜,那當然是無所不收,越多越好。
5. 於是大家都有了滿手的資料,但資料很髒也不行啊,我們需要的是乾淨的資料!
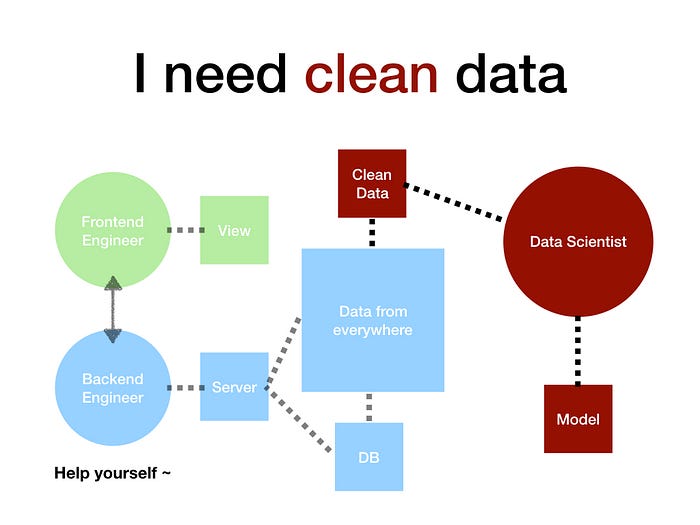
我們開始進入問題的核心了,通常我們從各地方搜刮來的資料都很髒,甚至自家產的資料也可能很髒,髒代表的可能是缺失、格式錯誤、內容錯誤、不合理的極端值…等等問題,這些東西無法直接餵給電腦去訓練模型,所以需要經過清洗,但通常也只有資料科學家最清楚到底想要怎樣整理資料,於是他們必須得是個同時具備高端的軟體開發能力、數學統計能力與領域知識的神獸,當然薪水也就很可觀了。
6. 但資料清洗其實是個大坑
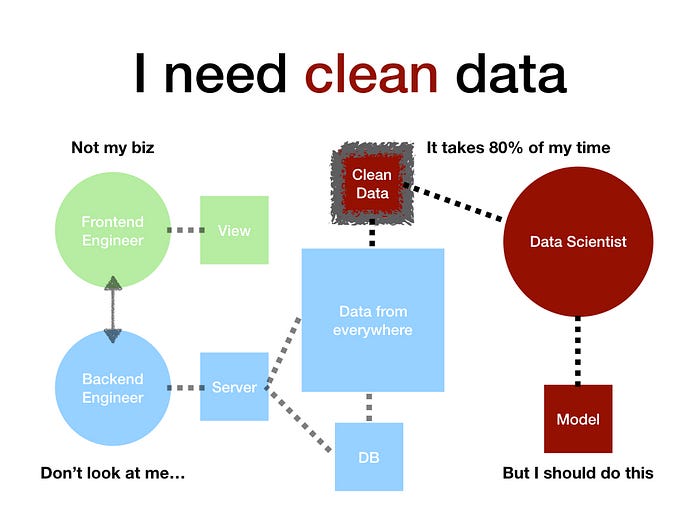
資料科學家們漸漸發現,自己花了 70~80% 的時間在做資料清洗,由於分析用資料量通常極為龐大,開發清洗的工具本身就是一件很龐大的工程問題,最終導致他們能拿來做模型的時間極少(有的甚至還要處理資料視覺化問題,標準的全端資料科學家),但這樣的人力分工其實是非常不經濟的,如果能把工程端與科學研究端切開才是更合理的選擇,但傳統的後端工程師主要職責還是在處理商業系統的邏輯需求,也無力兼顧兩者,於是,終於要進入正題了。
7. 就決定是你了!資料工程師
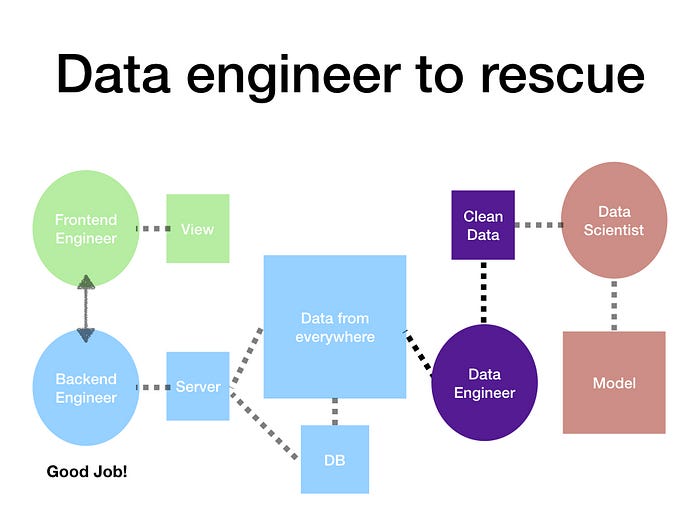
在這樣的環境下,資料工程師的誕生就非常合情合理了,他站在資料科學家的角度,從後端蒐集的資料中,幫忙做好清洗的這塊複雜工作。他們在與前端溝通(例如API設計)或商業需求的開發上,可能沒有後端工程師來的熟悉,但需要專精於大數據處理的能力,如一些平行運算的技巧,工具如 Hadoop 或 Spark 等,或 realtime 處理工具如 Flink 或 Storm 等,也得有管理運算集群的能力(又可細分為雲端集群或自建機房),更要對諸多不同的數據庫有深入的理解,才能知道該如何安排資料該去的位置,並且最好對資料科學家要做的事能有一定程度的理解。剛開始確實很多是後端工程師跨過來做的(不意外),但也有純的資料工程師,就只專精在資料這塊。
8. 但其實資料工程師還可以做得更多
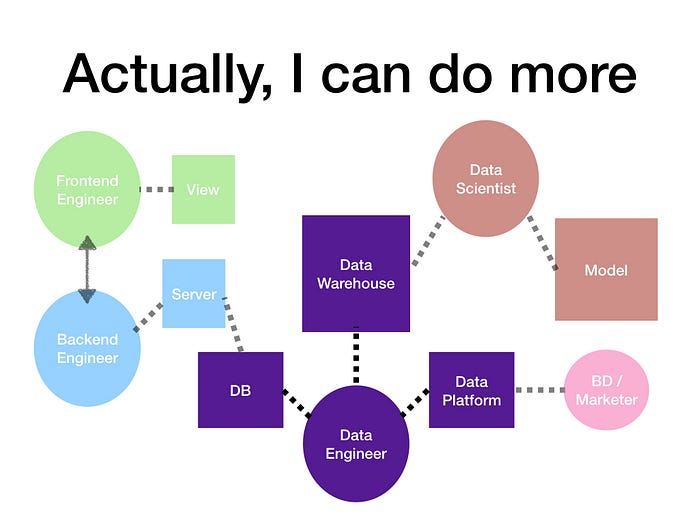
事實上隨著時間發展,資料工程師也開始不僅止於協助資料科學家的角色,而是成為了整個資料平台的建構者,在部分公司這樣的角色已經出現,由一群資料工程師團隊,建構整個資料平台,將所有資料分門別類,提供其他所有團隊使用。不過更多的公司通常是處於建立的過程,所以可能會有非常多後端團隊都有各自的資料庫,然後慢慢想辦法整併起來變成統一的資料團隊負責,開發一整套統一的流程來達到品質與效能的最大化。
故事到這邊差不多說完了,不過實際上不同狀況的公司,也會因應需求有不同的變化,資料工程師通常只會出現在資料量與資料複雜度有一定規模以上的公司,初期通常是後端先努力頂住,撐不住才開始建立專職資料團隊,此時的資料工程師角色往往會跟後端工程師重疊,需要協調分工,也需要互通知識。
而當公司還沒成長到養的起資料科學家團隊,但又想做一些簡單的模型時,也可能請資料工程師和行銷團隊、營運團隊一起思考,有沒有可以使用程式建立模型,或做自動化處理,來降低人力手工分析的時間成本,這時又會變成類似資料科學家的角色,做一些比較像研究而非工程的任務。
最後總結一下不同崗位的常見職責與技能分配:
1. 前端工程師:處理使用者看得見的部分,Web 端語言通常是 javascript 與各種衍伸框架,mobile 就看各家,不贅述。
2. 後端工程師:處理商業邏輯,給與前端 API,並維護 Server 的各種效能、安全性與自動化問題,也須要處理資料庫的議題。使用語言眾多,基本上大多主流語言都有後端框架可用。
3. 資料工程師:專職處理大數據資料庫會遇到的效能、安全性、自動化等問題。清洗資料並將資料維護在合適的資料庫系統供各端使用。常見技能是 Hadoop 或 Spark。處理情境分 batch 與 realtime。且需理解常見 SQL 與 NoSQL 資料庫的使用時機與效能調整。最好還略懂一點資料科學家的需求。
4. 資料科學家:比較像科學研究的職位了,雖然要懂程式,但工程的成分相對較少,反而需要更深的是數學研究能力。技能上通常是根據 ML 或 AI 的不同應用去分類。

