GANs and Plans
Using Neural Networks to explore thematic content

Continuing from where we last left off (a little over two months ago now) we have spent time exploring themes surrounding the Chinese Social Credit System and we have surveyed possible technologies that might provide us with some interesting tools and ways of exploring these themes.
The Old Indulgences

One concept that our artist explored was drawing parallels between the medieval tradition of Catholic indulgences and the social credit system. When we think of indulgences today, we generally think of it as a form of enjoying oneself through splurging; however, in the medieval era indulgence had a much more significant meaning. Indulgence was “a way to reduce the amount of punishment one has to undergo for sins” and an indulgence could be obtained by performing a “good” act or deed. This generally constituted prayer, public works, and donations for Catholic works. The donation part is where — as you can imagine— things got out of hand and gave the catholic practice of indulgences a reputation of abuse.

Indulgence & Social Credit
Similar to the proposed Chinese Credit System, indulgences were structured as a way to compel citizens to perform good works with the hope that it would benefit society. Replace sin with score and the parallels are evident, especially when watching this Vice News broadcast. Aside from getting rewards for performing good deeds, if you watch around the 4:00 minute mark there is footage from a local community office where citizens can make donations — which the government says will go to charity — to raise their credit scores. Sound familiar? Hence this point of comparison became the basis for our first set of experiments using neural networks to explore the intersection of these two themes.
Neural Networks: GANs, Neural Style Transfer, and… a Collage Builder?
So why Neural Networks? Neural Networks are a state of the art branch of machine learning that, until relatively recently, have become usable due to the increased availability of huge amounts of data and significant improvements in computer hardware technology. In our previous post we had begun exploring ideas about visualizing data and how it could be representative of the Social Credit System.
This led us to the parallel where, like Neural Networks, surveillance and other types of monitoring — i.e. the NSA’s PRISM program — are becoming more effective because of huge sources of data and the ability to process such data with more advanced technologies and models. Like the NSA, big data is making the idea of an advanced social credit system possible. Hence we decided that Neural Networks could be a reasonable medium and analogy to generate visualizations that related to theme of Indulgence and Social Credit.
Generative Adversarial Networks (GANs):

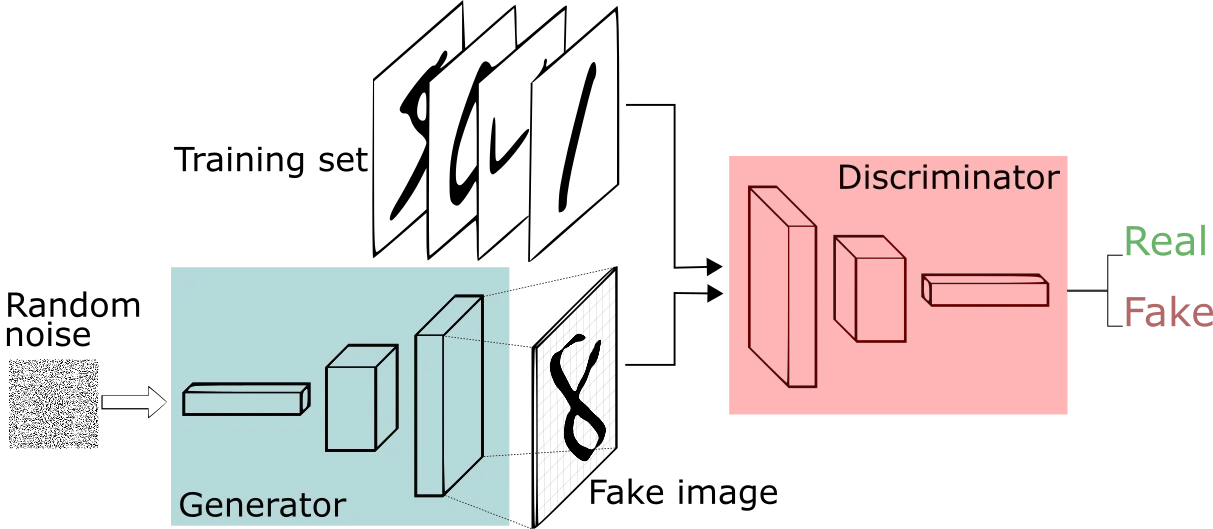
In our first approach we examined the use of Generative Adversarial Networks (GANs). A GAN is a method where you train two competing neural networks: one which generates fake data, and one which discerns whether or not that generated data is a fake or real example. The generator consistently tries to create better fakes whereas the discriminator tries to learn how to better differentiate real from the fake outputs of the generator.
The GIF above shows what that training process looks from the beginning where you start out with random noise (the rainbow pixels) to something that starts to take shape once the generator has started learning enough to produce more and more reliable fakes. We applied this approach with a data set of old Chinese propaganda images.


The GIF on the right is our model in the process of training and as you can see at a low resolution (these are 64 x 64 pixels) you can start seeing how the fake images are becoming discernible relative to the training images that we fed the network. This was a promising result; however, GANs are notoriously difficult to train and although we got images that began to look promising, a huge challenge — if this were to be used in an art piece — is getting fake images to be generated at a high enough resolution.


As you can see above our fake generated images look pretty decent at a low resolution. What happens when you take a closer look?




Now this shouldn’t be too surprising since these were generated at a very low resolution, but if it were to be usable we would definitely need to increase the resolution significantly. This is not a simple problem. While we could alter our model to accept larger resolution inputs — as a means to output higher resolution fakes — this makes the model much larger and more difficult to train. For context, Nvidia created a high resolution GAN called StyleGAN that produces incredible high resolution fakes; however, take a look at the expected training times posted below.

Up to 41 days to reproduce their results! This also doesn’t take into consideration the days of tweaking parameters and all of the debugging that comes along with implementing such an approach for a unique data-set, or the fact that most of our prototyping was being done on a free cloud GPU.
This clearly was a dilemma given our limited time; but in the spirit of exploration, we were off to setup the next experiment.
Neural Style Transfer

Next on the docket was testing another common neural network approach known as Neural Style Transfer. Generally, Neural Style Transfer utilize a pre-trained convolutional neural network (i.e. VGG-19, ResNet-50, etc.) to decompose an image and then calculate a set of loss values between an input image and a target style image.
These pre-trained neural networks were designed to classify images (for example differentiate a dog from a cat) and they do so by abstracting an image into different layers (illustrated below) which the computer can use to make sense of what the image contains. For a simple example, one layer might contain information about the outline of objects in a scene and another might have color information or focus on specific parts of an image.
Without getting too in-depth, the quick summary is that we can use these layers to then take an input image (such as the corgi above) and create a new image which then tries to maintain the content of the input image while also trying to re-colorize / re-stylize the generated image so that it is close to the desired style target. This balancing act is represented as a difference or loss which a neural network then tries to minimize (More detailed explanation here).
Now that you have a general sense of the approach, it is probably pretty obvious that this would be a relatively simple and cool way to mix imagery relevant to the Social Credit System and the Catholic indulgences.

You can see in the examples above and below that the results vary quite a bit but overall they are decent for a first pass.

What we did come to realize through this exercise is that for both medieval and propaganda image sets that we were using, each individual picture contained a lot of objects in its scene. This produces an issue because the target style image has a lot of color variations due to it containing a lot of varying objects. The reason why paintings like the Starry Night (used to stylize the corgi at the beginning of this section) map so well to an input image is because they don’t contain a lot of object information, but rather have more of a texture or pattern and are less focused on specific objects.
Aside from this issue, neural transfer has also been ad nauseam and while the results were interesting, we figured that there wasn’t much to build upon if we pursued this technique further. That being said another related approach which we didn’t implement arose. There were some papers that had the idea of inserting (or removing) objects into an image or painting and using that image’s style to then blend the object seamlessly. We won’t go into detail but you can take a look here.
Generative Collages

Lastly, we experimented with the idea of using object recognition and segmentation to generate collages that mixed different objects from different images. Object recognition is another area where neural networks have not only become the benchmarks for machine learning, but have also managed to outperform human eyes.
In order to accomplish this task, we leveraged a model known as a Mask R-CNN (Region-Convolutional Neural Network). This model uses a Neural Network to first identify all objects in a scene and then creates a bounding box around that object.

Once it has identified the general location of those objects it then uses another network to predict where the object actually is within those confines and thus giving us a “mask” of that object which is illustrated above in the different colors illustrated. This differentiation of objects in a picture is known as image segmentation.
Using this approach we then applied this principle to our own set of images. In order to make this work, we first used the model to identify the object masks in our medieval and Chinese propaganda image sets. Once we did that, we added additional functionality to cut out the masked object and then save it as an individual png file. Once we standardized this procedure, we processed all of our images to create a set of images from both sets. Finally, we created a separate script that then took a list of png files and randomly selected and pasted those images in random locations. Voila.


Unfortunately most of the images in our sets only contained people so most of our resulting object bank is filled with cutouts of people figures. Either way we were pleased with the results.
Conclusion
In this post we talked in depth about how we took parallels between the Social Credit System and Catholic indulgences and then explored those themes using three different types of Neural Network approaches. We did not go into great technical detail or explain fully all of the work that went into setting up these models, but we hope that this overview gave some insight into our thought process and how we rapidly explored and prototyped different ideas. None of these approaches provided enough traction to become the focus for our final piece, but we learned quite a bit and are currently continuing to iterate through ideas and mediums.
