Microservices Resilience and Fault Tolerance with applying Retry and Circuit-Breaker patterns using Polly
In this article, we are going to Developing “Microservices Resilience and Fault Tolerance with applying Retry and Circuit-Breaker patterns using Polly”.

Microservice architecture have become the new model for building modern cloud-native applications. And microservices-based applications are distributed systems.
While architecting distributed microservices-based applications, it get lots of benefits like makes easy to scale and manage services, but as the same time, it is increasing interactions between those services have created a new set of problems.
So we should assume that failures will happen, and we should dealing with unexpected failures, especially in a distributed system. For example in case of network or container failures, microservices must have a strategy to retry requests again.

But What happens when the machine where the microservice is running fails?
For instance, a single microservice can fail or might not be available to respond for a short time. Since clients and services are separate processes, a service might not be able to respond in a timely way to a client’s request.
The service might be overloaded and responding very slowly to requests or might simply not be accessible for a short time because of network issues.
How do you handle the complexity that comes with cloud and microservices?
— Microservices Resilience
Microservice should design for resiliency, A microservice needs to be resilient to failures and must accept partial failures. We should Design microservices to be resilient for these partial failures. They should ability to recover from failures and continue to function.
We should accepting failures and responding to them without any downtime or data loss. The main purpose of resiliency microservices is to return the application to a fully functioning state after a failure.
So when we are architecting distributed cloud applications, we should assume that failures will happen and design our microservices for resiliency. We accept that Microservices are going to fail at some point, that's why we need to learn embracing failures.
Let’s check our big picture and see what we are going to build one by one.
As you can see that, we are in here and start to developing “Microservices Resilience and Fault Tolerance with applying Retry and Circuit-Breaker patterns using Polly”.

We are going to cover the;
- Start with Microservices Resilience Patterns
- Definition of Retry pattern
- Definition of Circuit-Breaker patterns
- Definition of Bulkhead pattern
- Appling Retry patterns using Polly
- Appling Circuit-Breaker patterns using Polly
We will apply these microservices resilience patterns on our microservices communications which specifically
- Shopping Client microservices
- Ocelot Api GW microservices
- Shopping.Aggregator microservices
These are communicating internal microservices in order to perform their operations, so these communications should be resilient with applying retry and circuit-breaker patterns.
Also Applying Retry pattern for Database migrate operations.
- When Discount microservices startup, we will create database, table and seed table in PostreSQL database in order to perform migration. This will retry by applying retry pattern with polly.
- When Ordering microservices startup, we will create database, table and seed table in SQLServer database in order to perform migration. This will retry by applying retry pattern with polly.
So in this article, we are going to Develop our “Microservices Resilience and Fault Tolerance with applying Retry and Circuit-Breaker patterns using Polly”.
By the end of the article, we will make stronger for our microservices reference application with applying microservices resilience patterns.
Background
This is the introduction of the series. This will be the series of articles. You can follow the series with below links.
- 0- Microservices Observability, Resilience, Monitoring on .Net
- 1- Microservices Observability with Distributed Logging using ElasticSearch and Kibana
- 2- Microservices Resilience and Fault Tolerance with applying Retry and Circuit-Breaker patterns using Polly
- 3- Microservices Monitoring with Health Checks using WatchDog
We will focus on microservices cross-cutting concerns on these article series.
Step by Step Development w/ Udemy Course

Get Udemy Course with discounted — Microservices Observability, Resilience, Monitoring on .Net.
Source Code
Get the Source Code from AspnetRun Microservices Github — Clone or fork this repository, if you like don’t forget the star. If you find or ask anything you can directly open issue on repository.
Microservices Resilience Patterns
In order to provide unbroken microservice, the architecture must be designed correctly, and the developers must develop applications that are suitable for this architecture and will not cause errors.
Unfortunately, we may not always achieve this, but fortunately there are some approaches that we can apply to provide uninterrupted service, the name of these approaches is “Resilience Pattern”.
Resilience Patterns can be divided into different categories according to the problem area they solve, and it is possible to examine them under a separate topics, but in this article, we will look at the most needed and essential design patterns.
Ensuring the durability of services in microservice architecture is relatively difficult compared to a monolithic architecture. In the microservice architecture, the communication between services is distributed and many internal or external network traffic is created for a transaction. As the communication need between services and dependence on external services increases, the possibility of occurring errors will increase.
Polly Policies
We will use Polly when implementing microservices resilience patterns.
Polly is a .NET resilience and transient-fault-handling library that allows developers to express policies such as Retry, Circuit Breaker, Timeout, Bulkhead Isolation, and Fallback in a fluent and thread-safe manner.
Go to;
https://github.com/App-vNext/Polly
You can check Resilience policies. Polly offers multiple resilience policies:
- Retry
Configures retry operations on designated operations - Circuit Breaker
Blocks requested operations for a predefined period when faults exceed a configured threshold. - Timeout
Places limit on the duration for which a caller can wait for a response. - Bulkhead
Constrains actions to fixed-size resource pool to prevent failing calls from swamping a resource. - Cache
Stores responses automatically. - Fallback
Defines structured behavior upon a failure.
Retry Pattern
Microservices Inter-service communication can be performed by HTTP or gRPC and can be managed by developments. But when in comes to network, server, and such physical interruptions may be unavoidable.
If one of the services returns http 500 during the transaction,
the transaction may be interrupted and an error may be returned to the user,
but when the user restarts the same transaction, it may work.
In such a case, it would be more logical to repeat the request made to the 500 returned service, so that the roll-backs of the realized transactions will not having to work, and the user will be able to perform the transaction successfully, even if it is late.
So we can say that a distributed cloud-native environment,
microservices communications can fail because of transient failures,
but this failures happen in a short-time and can fix after that time.
For that cases, we should implementing retry pattern.

In the image, the client requested to api gateway in order to call internal microservices. Api Gateway Service needs to access internal Microservice and creates a request, so if internal microservice has failed for a short-time and returns http 500 or gets an error, the transaction will be terminated,
But when the Retry design pattern is applied, the specified number of transactions will be tried and may be performed successfully.
For this image, api gateway get 2 times 500 response from internal microservice and finally the third call got succeed, so that means the transaction completed successfully without termination.
In order to allow the microservice time to fix itself with self-correct,
it is important to extend the back-off time before retrying the call.
In Most usages the back-off period should be exponentially incremental withdrawal to allow sufficient correction time.
Circuit Breaker Pattern
Circuit Breakers pattern, is a method in electronic circuits that is constructed like circuit breaker switchgear, as the name suggested. Circuit breakers stop the load transfer in case of a failure in the system in order to protect the electronic circuit.
When the Circuit Breakers pattern is applied, it is constructed to include communication between services. It monitors the communication between the services and follows the errors that occur in the communication. An example of this error is that an API end that has been requested returns an HTTP 500 error code.
When the error in the system exceeds a certain threshold value,
Circuit Breakers turn on and cut off communication, and returning previously determined error messages.
While Circuit Breakers is open, it continues to monitor the communication traffic and if the requested service starts to return successful results, it becomes closed.
If you look at the image, the circuit breaker has 3 basic modes.

Closed: In this mode, the circuit breaker is not open and all requests are executed.
Open: the circuit breaker is open and it prevents the application from repeatedly trying to execute an operation while an error occurs.
Half-Open: In this mode, the circuit breaker executes a few operations
to identify if an error still occurs. If errors occur, then the circuit breaker will be opened, if not it will be closed.
In the image, the client requested to api gateway in order to call internal microservices. And we have implemented retry pattern on this communication. But what if internal microservice is totally down, and it can’t be ready for a long time.
For that cases if we repeated retries on an unresponsive service,
this will consume resources such as memory, threads, and database connections and cause irrelevant failures.
So for that reason, we have applied Circuit Breaker pattern over the retry pattern. As you can see that, in here, after 100 failed requests in 30 seconds,
the circuit breakers opens and no longer allows calls to the internal microservice from api gateway. That means circuit breaker pattern applied in the api gateway when calling internal microservices. After 30 second, api gateway try to call microservices again and If that call succeeds, the circuit closes and the service is once again available to traffic.
The Circuit Breaker pattern is prevent broken communications from repeatedly trying to send request that is mostly to fail. We set the pre-defined number of failed calls and time period of this fails, if fails happen in that time interval than it blocks all traffic to the service.
After that it is periodically try to call the target service in order to determine its up or down. If the service call succeed than close the circuit and continue to accept requests again.
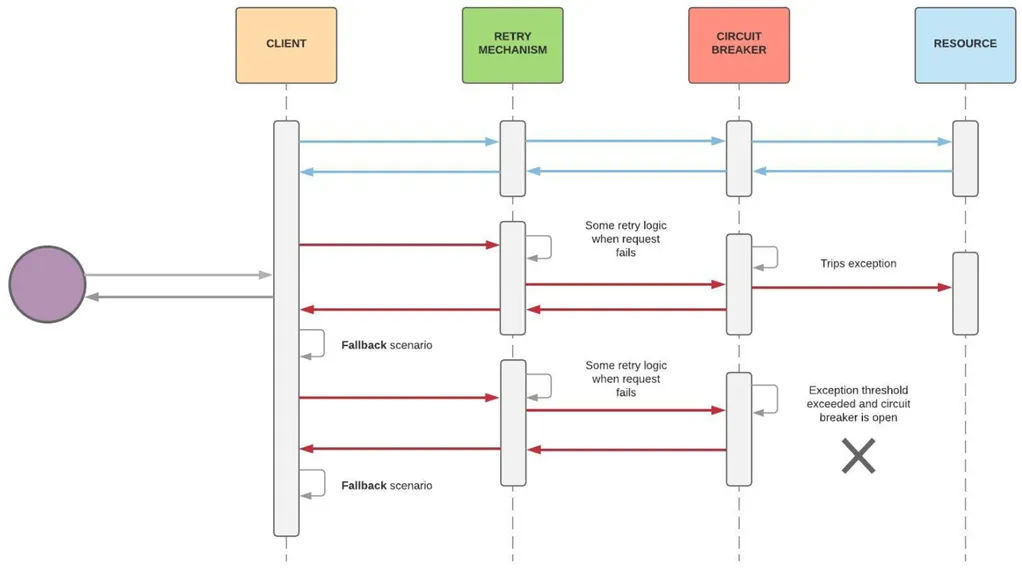
Retry + Circuit Breaker Pattern
If we compare with the Retry pattern, Retry pattern only retry an operation in the expectation calls since it will get succeed. But The Circuit Breaker pattern is prevent broken communications from repeatedly trying to send request that is mostly to fail.
So we are going to apply both Retry and Circuit-Breaker Pattern in our microservices reference application with using Polly library.
https://github.com/App-vNext/Polly
We will examine examples of github readme file and develop for our microservices.
For further explanations on this topic, you should check microsoft architecture book which name is — Architecting Cloud Native .NET Applications for Azure written from Rob Vettor and Steve Smith
Go to
https://docs.microsoft.com/en-us/dotnet/architecture/cloud-native/
If you come to topic of Cloud-native resiliency. You can get additional details of this topic. Also our images comes from this book, this is free book from Microsoft.
Bulkhead Pattern
The Bulkhead design pattern aims to isolate the occurring error which is in one location does not affect other services by isolating the services.
The main purpose is isolated error place and secure the rest of services.

The inspiration for this design pattern is naval architecture. While ships or submarines are being built, they are made not as a whole, but by shielding from certain areas, so if there is happens a flood or fire, the relevant compartment is closed and isolated and the ship / submarine can continue its mission.
If we think of our microservices as a ship, we must be able to respond to user requests by isolating the relevant service so the error that will occur in a service does not affect other services.

See image here, we can better understand why we need the bulkhead design pattern. In case of the http requests from users comes too high, physical machines will not be able to process all requests at the same time and will naturally put them in order.
Let’s assume that users make a request to service A, service A doesn’t respond due to a software bug, and user requests start to accumulate in the queue as shown in number two. After a certain time, the requests will start to use all CPU threads of the machines and after a while, all new requests will start to wait in the queue.
While all requests to service A that are not working are busy with resources,
requests to service B that are running successfully will continue to wait in the queue, in this case, none of the demanding users will be satisfied.
In order to solve this problem, the bulkhead design pattern also suggests that
when a service is unresponsive, instead of using all resources to process requests to that service, some of the resources are allocated in a separate process and other requests are processed with the remaining server resource.
To implement this design pattern, resource limits can be defined for the application server where the services are running, for example, the maximum number of threads and memory limit that the service can use.
Apply Retry Pattern with Polly policies on HttpClientFactory for Shopping.Aggregator Microservices
We are going to Apply Retry Pattern with Polly policies on HttpClientFactory for Shopping.Aggregator Microservices. As you remember that when we developed Shopping.Aggregator microservices, this will consume internal microservices with using HttpClientFactory and agregate Catalog, Basket and Ordering microservices data in one web service.
If one of the internal microservices is temporary down or not accessible, we will apply retry pattern with using Polly policies on HttpClientFactory for Shopping.Aggregator Microservices.
So how Polly policies can apply retry pattern on HttpClientFactory ?

You can see in this picture, we are going to
- Use IHttpClientFactory to implement resilient HTTP requests
- Implement HTTP call retries with exponential backoff with IHttpClientFactory and Polly policies
You can find the main article of this picture,
https://docs.microsoft.com/en-us/dotnet/architecture/microservices/implement-resilient-applications/use-httpclientfactory-to-implement-resilient-http-requests
Before we start, we should go to Shopping.Aggregator Microservices
In this microservices we Use IHttpClientFactory to implement resilient HTTP requests.
We have Implemented Typed Client classes that use the injected and configured HttpClient with IHttpClientFactory
Go to Shopping.Aggregator
Startup.cs — ConfigureServices
services.AddHttpClient<ICatalogService, CatalogService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:CatalogUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>();
services.AddHttpClient<IBasketService, BasketService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:BasketUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>();
services.AddHttpClient<IOrderService, OrderService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:OrderingUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>();We have 3 api connection with HttpClientFactory. So we are going to Develop Policies for Retry and Circuit Breaker Pattern with Polly policies on HttpClientFactory.
Let’s take an action.
Install Nuget Package
Install-Package Microsoft.Extensions.Http.Polly
See that
<PackageReference Include=”Microsoft.Extensions.Http.Polly” Version=”5.0.1" />Before we start, we should check Polly repository on github
Polly Policies :
https://github.com/App-vNext/Polly
// Retry a specified number of times, using a function to
// calculate the duration to wait between retries based on
// the current retry attempt (allows for exponential backoff)
// In this case will wait for
// 2 ^ 1 = 2 seconds then
// 2 ^ 2 = 4 seconds then
// 2 ^ 3 = 8 seconds then
// 2 ^ 4 = 16 seconds then
// 2 ^ 5 = 32 seconds
Policy
.Handle<SomeExceptionType>()
.WaitAndRetry(5, retryAttempt =>
TimeSpan.FromSeconds(Math.Pow(2, retryAttempt))
If you check Retry operation, you can see example of usage with custom wait strategy.
Developing Retry and Circuit Breaker Pattern
Lets develop custom policy methods with detail policies.
Go to Shopping.Aggregator
Startup.cs
private static IAsyncPolicy<HttpResponseMessage> GetRetryPolicy()
{
// In this case will wait for
// 2 ^ 1 = 2 seconds then
// 2 ^ 2 = 4 seconds then
// 2 ^ 3 = 8 seconds then
// 2 ^ 4 = 16 seconds then
// 2 ^ 5 = 32 secondsreturn HttpPolicyExtensions
.HandleTransientHttpError()
.WaitAndRetryAsync(
retryCount: 5,
sleepDurationProvider: retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)),
onRetry: (exception, retryCount, context) =>
{
Log.Error($”Retry {retryCount} of {context.PolicyKey} at {context.OperationKey}, due to: {exception}.”);
});
}private static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(
handledEventsAllowedBeforeBreaking: 5,
durationOfBreak: TimeSpan.FromSeconds(30)
);
}
After that, we should refactor our policies.
This time we will use “AddPolicyHandler” method.
Change ConfigureServices
Go to Shopping.Aggregator
Startup.cs — ConfigureServices
public void ConfigureServices(IServiceCollection services)
{
services.AddTransient<LoggingDelegatingHandler>();services.AddHttpClient<ICatalogService, CatalogService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:CatalogUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>()
.AddPolicyHandler(GetRetryPolicy()) — -> ADDED
.AddPolicyHandler(GetCircuitBreakerPolicy()); — -> ADDEDservices.AddHttpClient<IBasketService, BasketService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:BasketUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>()
.AddPolicyHandler(GetRetryPolicy()) — -> ADDED
.AddPolicyHandler(GetCircuitBreakerPolicy()); — -> ADDEDservices.AddHttpClient<IOrderService, OrderService>(c =>
c.BaseAddress = new Uri(Configuration[“ApiSettings:OrderingUrl”]))
.AddHttpMessageHandler<LoggingDelegatingHandler>()
.AddPolicyHandler(GetRetryPolicy()) — -> ADDED
.AddPolicyHandler(GetCircuitBreakerPolicy()); —-> ADDED
TEST Polly :
Make sure that your docker microservices working fine.
Run Docker compose :
docker-compose -f docker-compose.yml -f docker-compose.override.yml up -d
docker-compose -f docker-compose.yml -f docker-compose.override.yml downNow we can test application retry operations.
Set a Startup Project
Shopping.Aggregator
Change App url
“ApiSettings”: {
“CatalogUrl”: “http://localhost:8000",
“BasketUrl”: “http://localhost:8009",-- CHANGE 8001 to 8009- Run Application
test with
swn - See logs
As you can see that retry 3 times
As you can see that, we have Developed Policies for Retry and Circuit Breaker Pattern with Polly policies on HttpClientFactory.
Get Udemy Course with discounted — Microservices Observability, Resilience, Monitoring on .Net.
For the next articles ->
Step by Step Development w/ Udemy Course
Get Udemy Course with discounted — Microservices Observability, Resilience, Monitoring on .Net.
