Batch-Constrained Deep Q Learning in TensorFlow
Reinforcement Learning (RL) algorithms like Deep Q Networks (DQN) and Deep Deterministic Policy Gradients (DDPG) interact with an environment, store data in a replay buffer, and train on that data. DQN and DDPG can be classified as growing batch learning. As the agent is trained with data from the replay buffer, the agent continues to interact with the environment and gather more data. This is in contrast to fixed batch learning, where the RL agent is trained on a fixed data set and no longer interacts with the environment.
If an RL agent can reliably learn from fixed batch data, that would allow us to train agents much more effectively in many real world cases. For example, in areas where data has already been gathered, where data is expensive to collect, or where there are safety constraints on gathering data.
In the Off-Policy Deep Reinforcement Learning without Exploration paper, the authors train an agent from a fixed batch using the Batch-Constrained deep Q-learning (BCQ) algorithm. The authors find that DQN and DDPG cannot train effective agents from a fixed batch due to extrapolation error. Extrapolation error causes the agent’s policy to inaccurately estimate q values that fall outside of the distribution of the fixed batch. DQN and DDPG can overcome extrapolation error in the growing batch case since the agent can alter its exploration and training.
The paper demonstrates the effectiveness of the BCQ algorithm over DDPG and DQN in the fixed batch setting on three types of fixed batch data: a final buffer of diverse data, an imitation buffer of expert data, and a concurrent buffer where an inactive agent learns alongside an active agent. BCQ outperforms DDPG and DQN in effectively estimating the true value function:

The paper’s most surprising finding is that even in the concurrent case, where an active agent (that interacts with the environment) and an inactive agent (no interaction with the environment) both train from the same replay buffer, the inactive agent fails to accurately estimate the true value function. While it makes sense that DQN or DDPG would struggle in the fixed batch setting — after all the size of the replay buffer and how the replay buffer is sampled from and replaced are all hyperparameters — the divergence in the concurrent case is surprising.
BCQ
BCQ attempts to eliminate extrapolation error by constraining the agent’s actions to the data distribution of the batch. This is done by training a DDPG-esque Actor-Critic agent with a Variational Auto Encoder (VAE) to constrain the actions. The authors have a PyTorch implementation available, this is a TensorFlow implementation. Let’s walk through the main parts of the BCQ code available at my repo, in particular the BCQ.py file.
The BCQ.py file contains a BCQ network. The BCQ network is similar to a DDPG network in that it has an actor network, critic network, and uses deterministic policy gradients (DPG). The actor part of the BCQ network:
Unlike DDPG, The BCQ actor constrains the actions produced by the states and actions of the batch, hence the actor network takes in states and actions as the input. The BCQ actor network also scales the output down by 0.05 before adding it to the original actions in the final output layer.
Like the TD3 variant of DDPG, BCQ uses clipped double Q learning to reduce overestimation bias. That means that the critic network is a actually a pair of critic networks. When calculating the target value from the critic, clipped double Q learning takes the minimum of the output of the pair. BCQ uses soft clipped double Q learning. The “soft” indicating that it doesn’t take the straight minimum but a mixture of the pair of outputs (.75 of the min output and .25 of the max):
self.soft_q_ = 0.75 * tf.minimum(self.critic_1_out_, self.critic_2_out_) + 0.25 * tf.maximum(self.critic_1_out_, self.critic_2_out_)The critic network takes in the output of the actor network and I use the actor and critic network outputs with TRFL to get the deterministic policy gradients:
self.dpg_return_ = trfl.dpg(self.critic_1_out_, self.actor_clip_)BCQ uses a VAE to generate the batch constrained actions. The VAE is a vanilla VAE with an encoder, decoder, and Gaussian distribution parameters that are learned. The VAE is trained on the replay buffer of fixed data. One thing to note about the VAE is that when it is called to generate actions — like for the agent’s select_action function or to produce perturbed actions to train the BCQ network — the input is duplicated 10 times. The paper describes the perturbation hyperparameter and number of samples taken as a trade-off between imitation learning (behavioral cloning) and RL (Q learning).
The training procedure at a high level:
- Train the VAE on the replay buffer
- Generate actions from the VAE
- Use VAE actions with soft clipped double Q learning to get target values
- Train the critic network with the target values
- Generate actions from the VAE
- Use the actions and the critic network to calculate the DPG and train the actor network
When selecting an action with the select_action function, we use the environment states and the VAE generated actions (duplicated 10 times) along with the actor network to select a policy for the agent.
Experiment
I tested the BCQ code by training some BCQ agents from an expert batch of data. I created an expert using the train_expert.py file for the OpenAI gym environments Pendulum and LunarLander. Then I used generate_buffer.py to generate a replay buffer. I used main.py to load the expert buffer (the fixed batch) and train the BCQ agent. The LunarLander commands from the terminal:
#train expert
python3 train_expert.py --env_name LunarLanderContinuous-v2 --seed 31 --expl_noise=0.1 --actor_lr=0.0005 --critic_lr=0.0005 --actor_hs=64 --critic_hs=64 --batch_size=32 --discount=0.99 --tau=0.001#generate buffer
python3 generate_buffer.py --env_name LunarLanderContinuous-v2 --seed 31 --actor_lr=0.0005 --critic_lr=0.0005 --actor_hs=64 --critic_hs=64 --batch_size=32 --discount=0.99 --tau=0.001 --noise1=0.1 --noise2=0.1#train BCQ agent
python3 main.py --env_name LunarLanderContinuous-v2 --seed 31
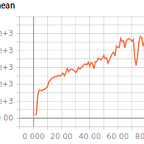
Results of the trained BCQ agents on Pendulum (try to minimize negative reward) and LunarLander (solved if average of 200 reward over 100 episodes, BCQ agent averages 238 reward):

Thoughts
For those interested in fixed batch RL, here are some other papers that I found interesting:
- REM algorithm: Theorizing on why fixed batch RL doesn’t work well with DQN, how distributional RL helps, and some interesting insights and algorithmic advances. Great breakdown of the paper on reddit.
- Batch RL paper that takes a different approach and benchmarks results against BCQ.
- Theory on potential issues in Q learning which is related to some of the issues discussed in the BCQ paper.
If I have the time I’m thinking of implementing this or a different RL algorithm in Stable Baselines or Ray if anyone is interesting in collaborating.